深浅拷贝


1 import copy 2 3 husband=['xiaoxin',123,[200000,100000]] 4 5 wife=husband.copy() #浅拷贝 6 wife[0]='xiaohong' 7 wife[1]='456' 8 9 xiaosan=copy.deepcopy(husband) #深拷贝 10 xiaosan[0]='xiaoyu' 11 xiaosan[1]='666' 12 13 wife[2][1] -=2000 14 xiaosan[2][1] -=1999 15 16 print(husband,wife,xiaosan)
结果:
['xiaoxin', 123, [200000, 98000]] ['xiaohong', '456', [200000, 98000]] ['xiaoyu', '666', [200000, 98001]]
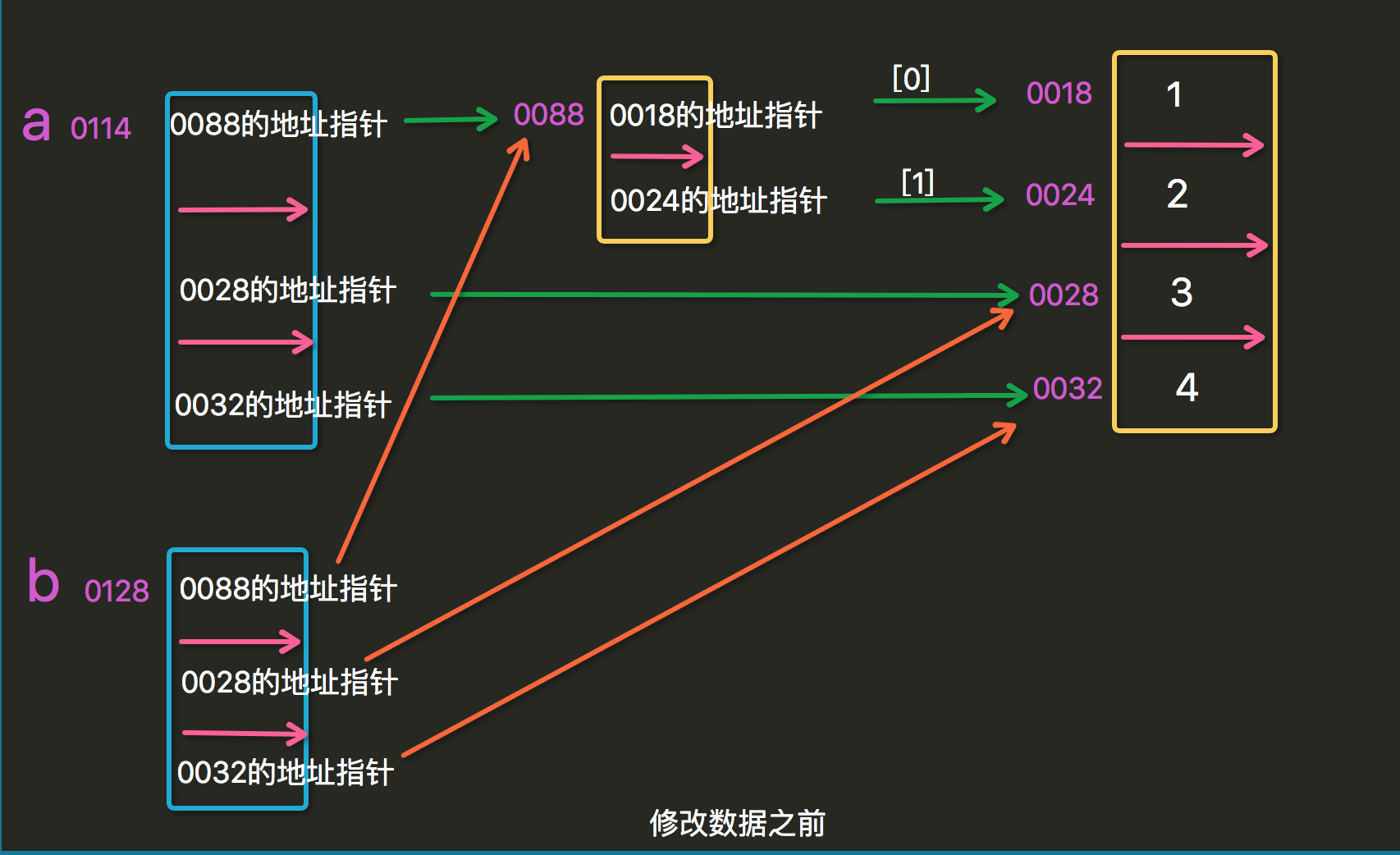
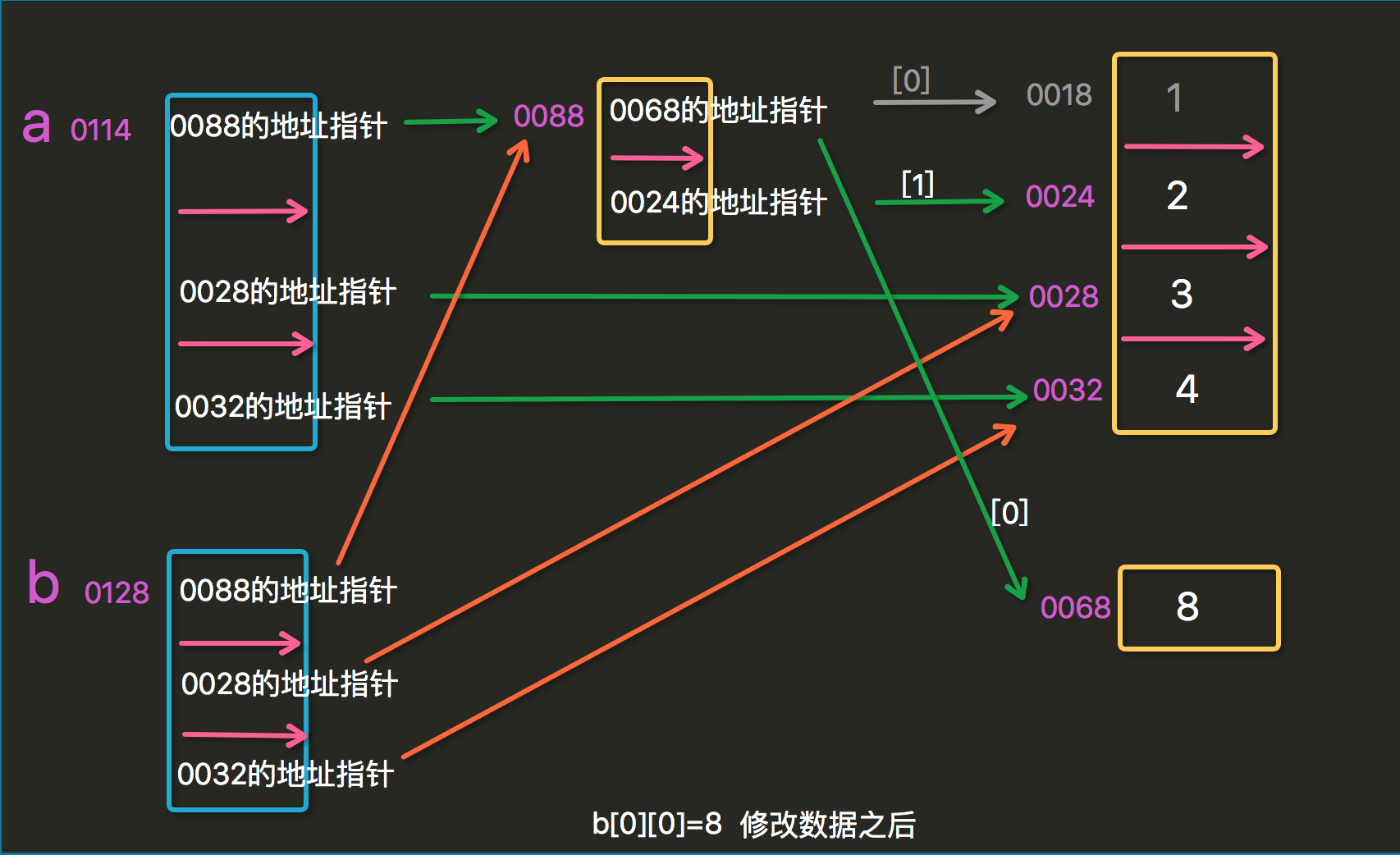
浅拷贝,只会拷贝第一层
当其中有列表等第二次时,拷贝后进行修改,元数据也会进行修改
修改数据前:
修改数据后:
集合
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
集合(set):把不同的元素组成一起形成集合,是python基本的数据类型。
集合元素(set elements):组成集合的成员(不可重复)
s=set('Nicknick') s1=['nick','xiaoli','xiaozhang','nick'] print(s) #{'c', 'i', 'N', 'k'} s1=set(s1) print(s1) #{'xiaoli', 'nick', 'xiaozhang'}
s = set([3,5,9,10]) #创建一个数值集合 t = set("Hello") #创建一个唯一字符的集合 a = t | s # t 和 s的并集 b = t & s # t 和 s的交集 c = t – s # 求差集(项在t中,但不在s中) d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中) 基本操作: t.add('x') # 添加一项 s.update([10,37,42]) # 在s中添加多项 使用remove()可以删除一项: t.remove('H') len(s) set 的长度 x in s 测试 x 是否是 s 的成员 x not in s 测试 x 是否不是 s 的成员 s.issubset(t) s <= t 测试是否 s 中的每一个元素都在 t 中 s.issuperset(t) s >= t 测试是否 t 中的每一个元素都在 s 中 s.union(t) s | t 返回一个新的 set 包含 s 和 t 中的每一个元素 s.intersection(t) s & t 返回一个新的 set 包含 s 和 t 中的公共元素 s.difference(t) s - t 返回一个新的 set 包含 s 中有但是 t 中没有的元素 s.symmetric_difference(t) s ^ t 返回一个新的 set 包含 s 和 t 中不重复的元素 s.copy() 返回 set “s”的一个浅复制
a=set([1,2,3,4,5]) b=set([4,5,6,7,8]) #交集 print(a.intersection(b)) #{4, 5} print(a&b) #并集 print(a.union(b)) #{1, 2, 3, 4, 5, 6, 7, 8} print(a|b) #差集 print(a.difference(b)) #{1, 2, 3} print(a-b) print(b.difference(a)) #{8, 6, 7} print(b-a) #对称差集 反向交集 print(a.symmetric_difference(b)) #{1, 2, 3, 6, 7, 8} print(a^b) #父集 超级 print(a.issuperset(b)) print(a>b) #False #子集 print(a.issubset(b)) print(a<b) #False