Beta阶段
1. 新功能:
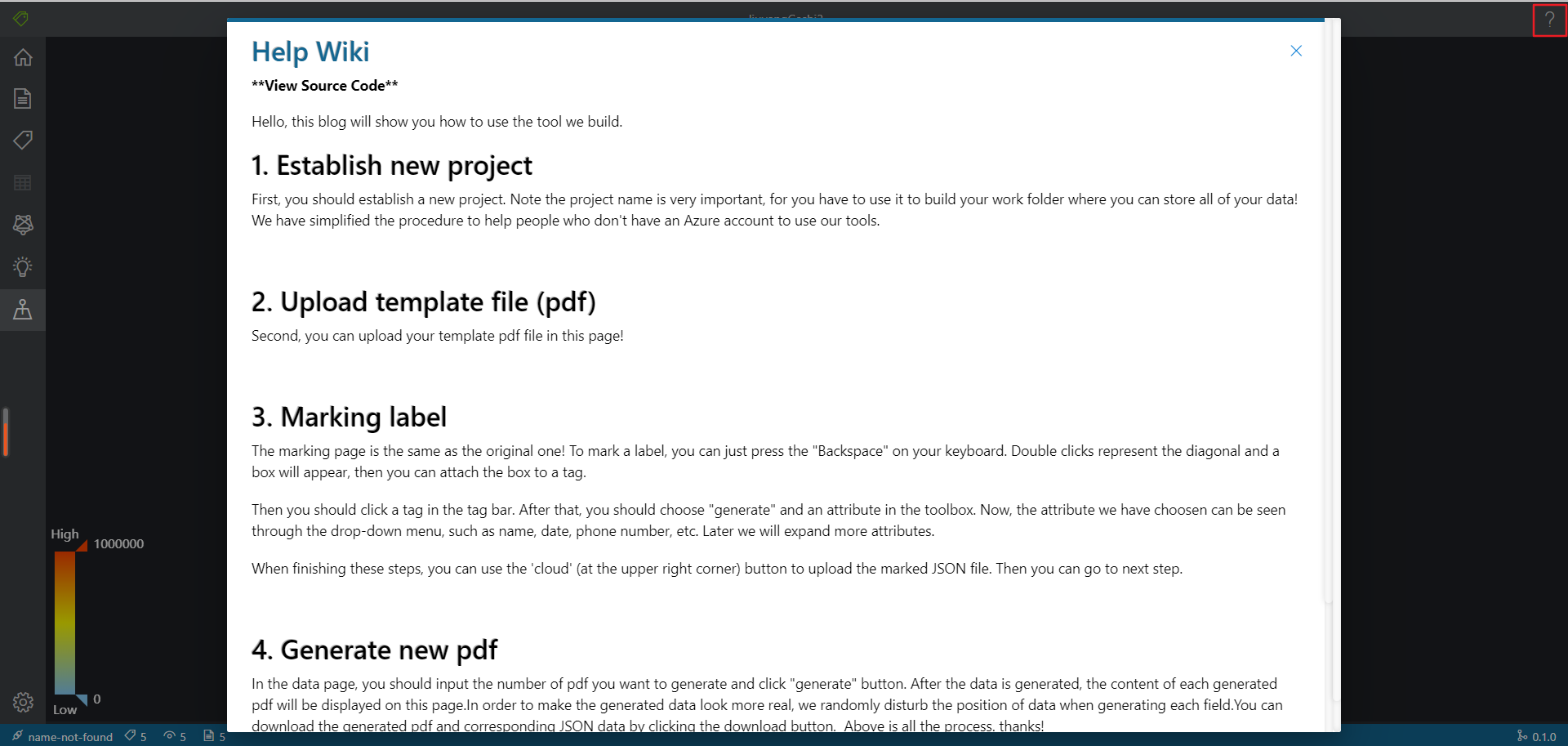
- 介绍页面
用户点击软件右上角的 ? 按钮即可看到软件的操作说明!
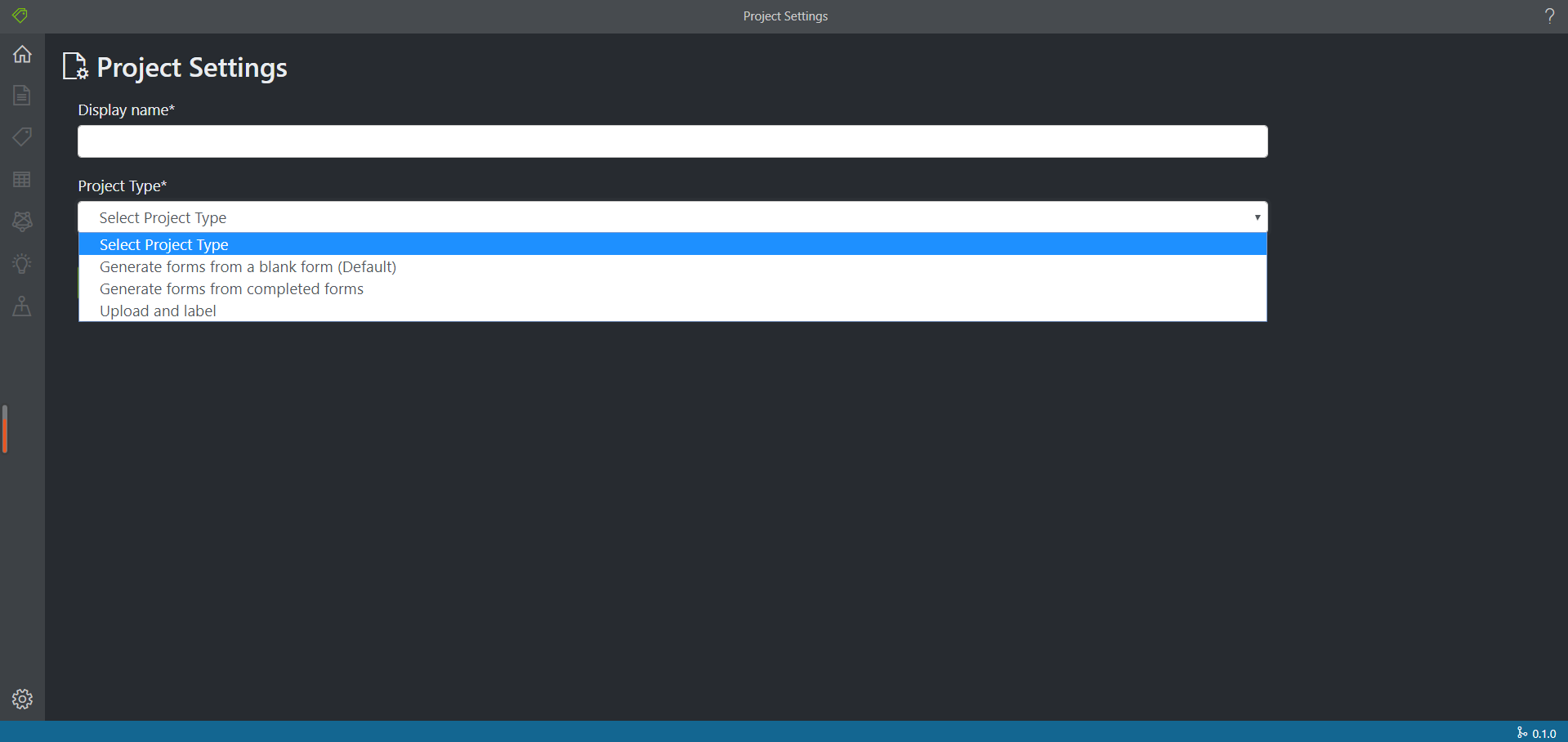
- 项目模式
目前软件支持三种模式
- 空白表单模式。该模式可以生成基于模板的表单数据,也支持生成数据直接训练模型以处理新的表单
- 自动处理模式。该模式用户只需要上传5份填好数据的表单,后端会自动处理识别字段并且训练,用户可直接使用预测的功能
- 原项目的标注训练模式——传送门
- 原项目功能恢复
我们把原项目的功能恢复了,用户可以手动上传5个表单,对每一个表单进行标注,之后进行训练,最后拿训练好的模型预测新的表单。
- 自动化训练
用户只需要上传5份填好数据的PDF表单
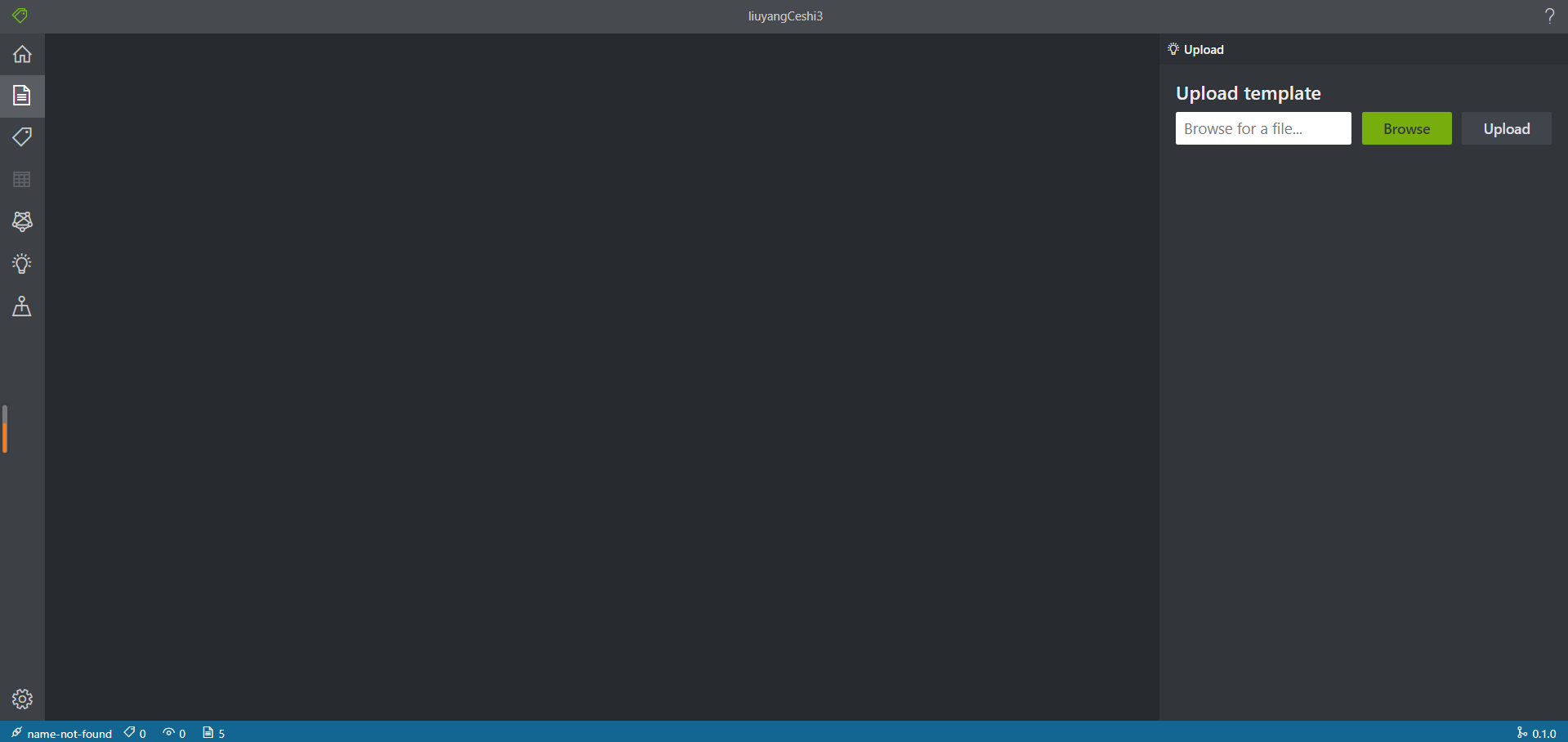
之后可以在标注页面进行查看,但是这一模式下无法进行标注
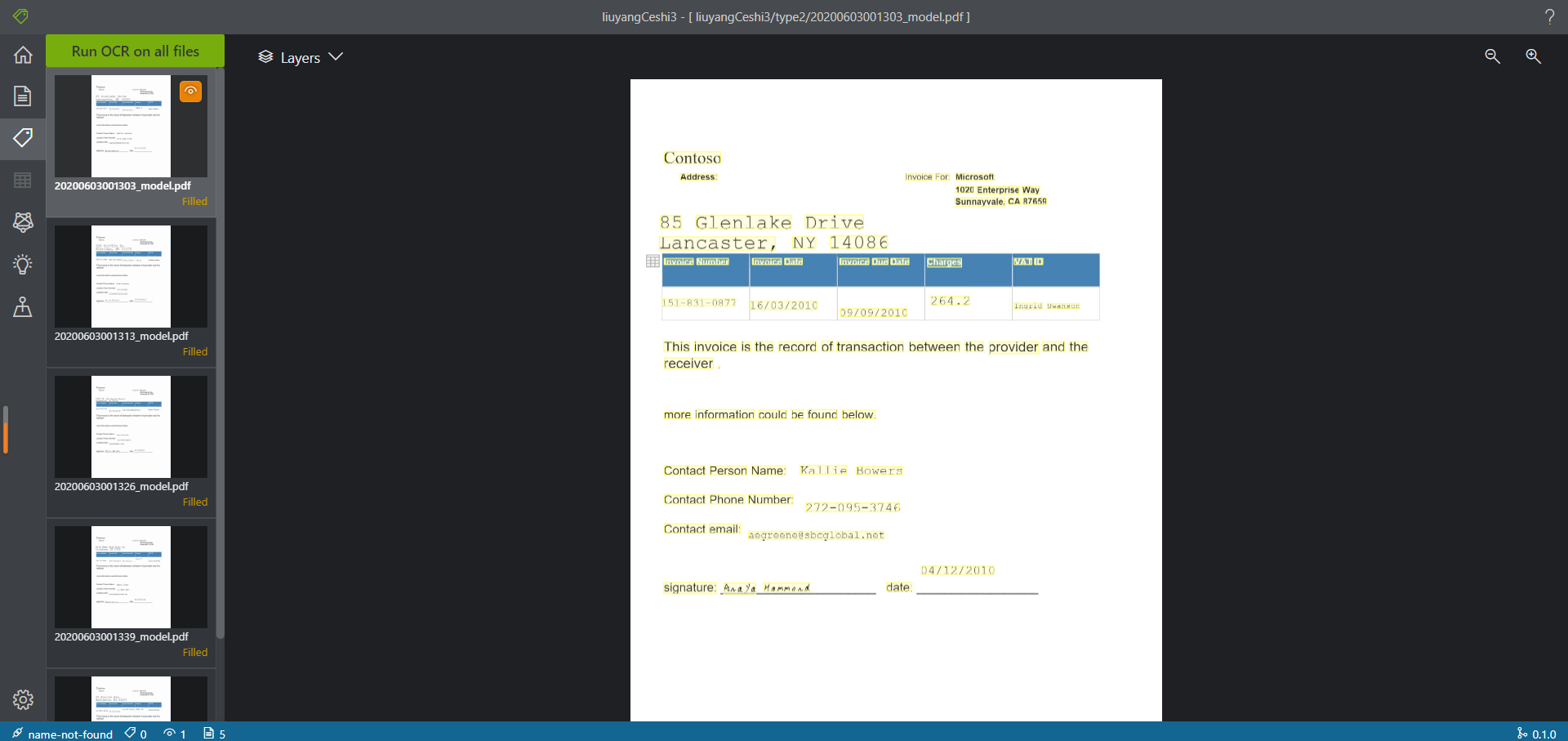
用户可以直接在训练页面进行训练,等待训练结束
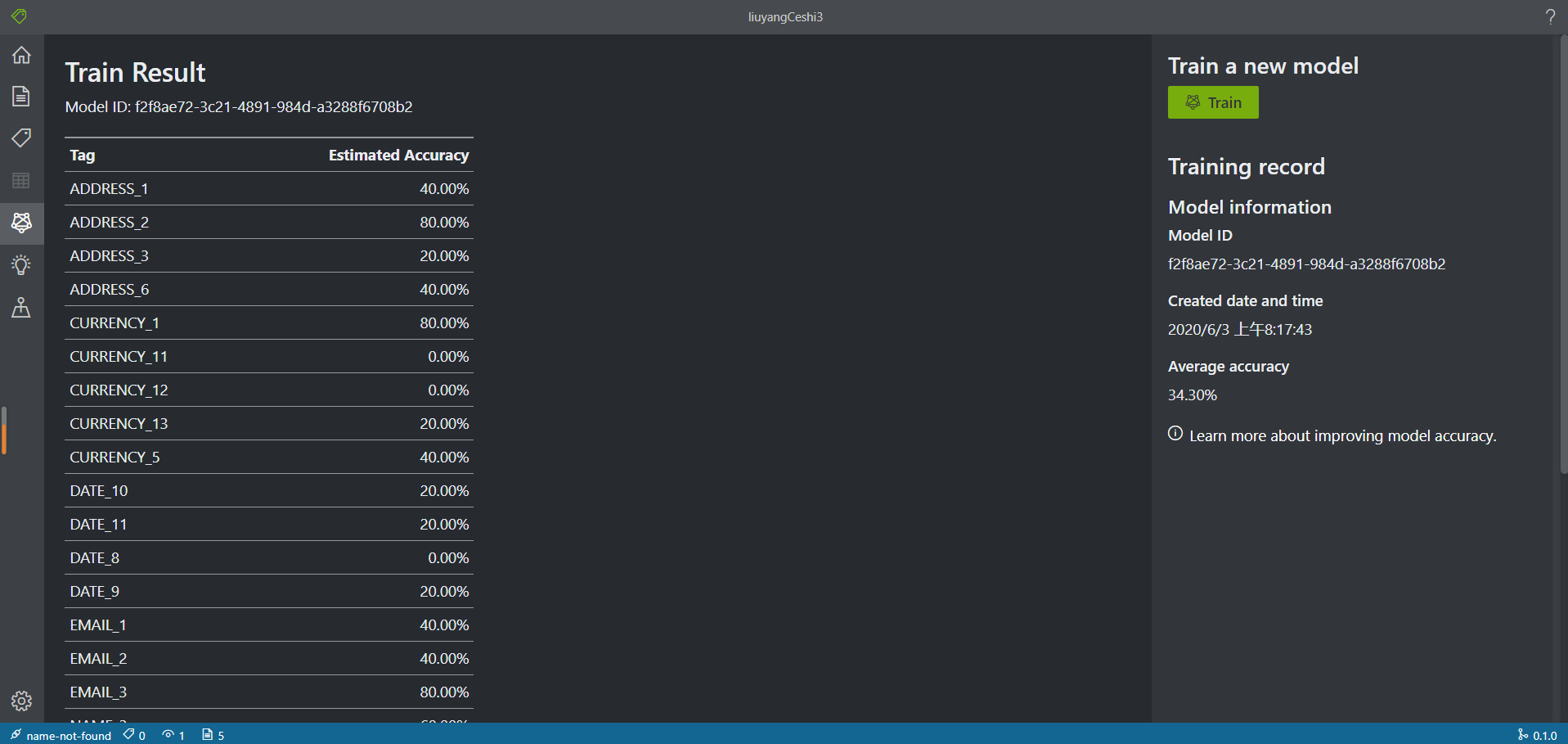
现在用户就可以使用模型处理新的表单了
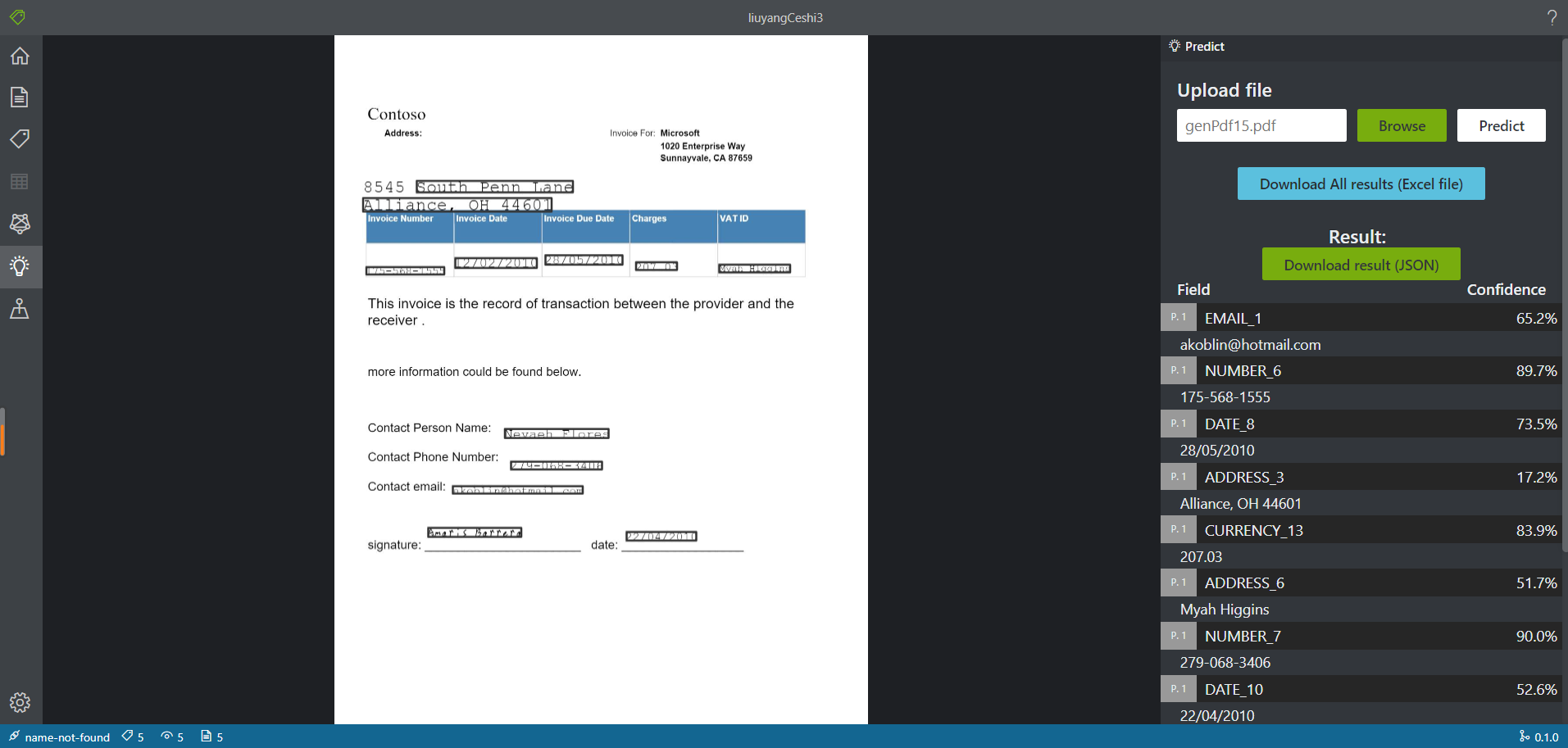
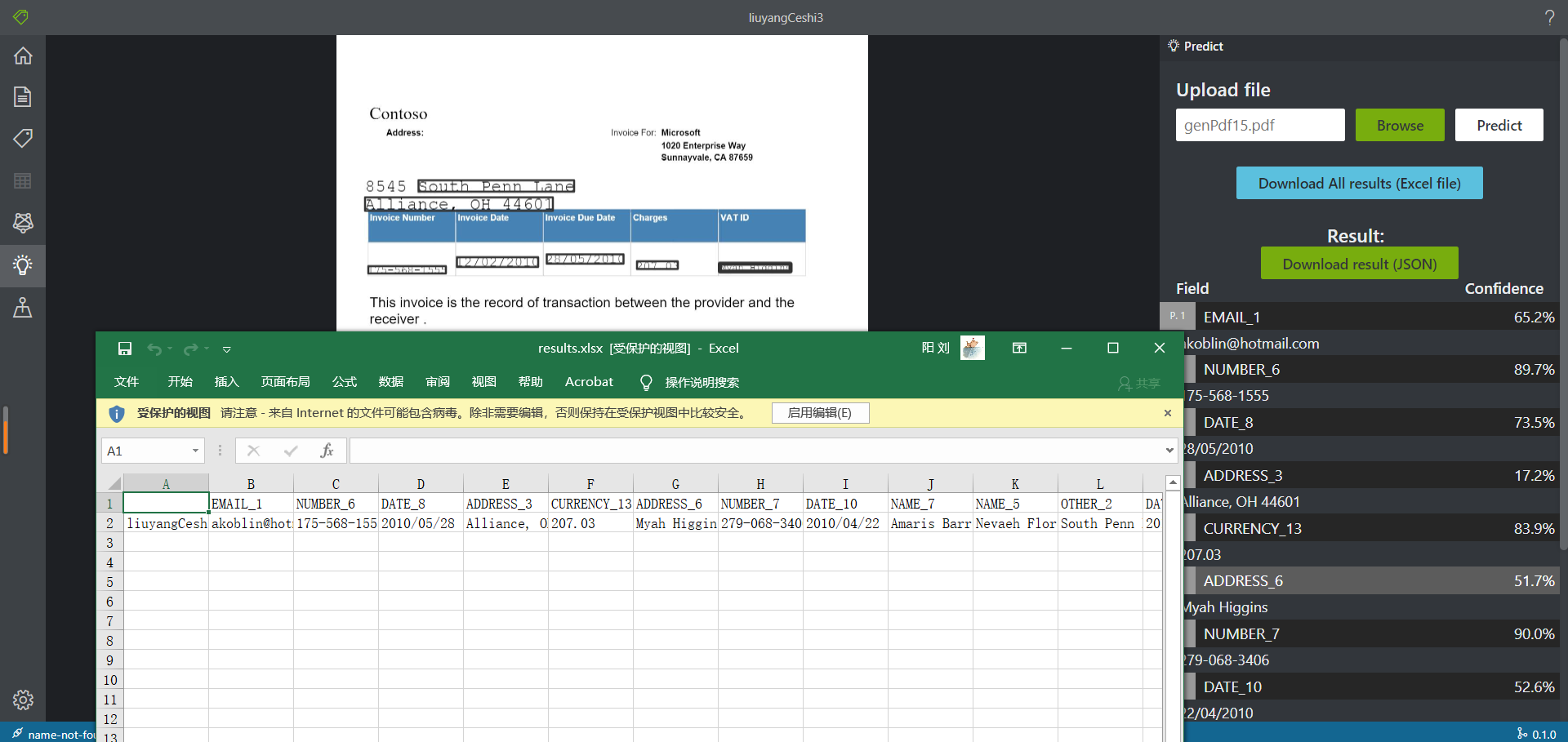
- 预测结果自动整理
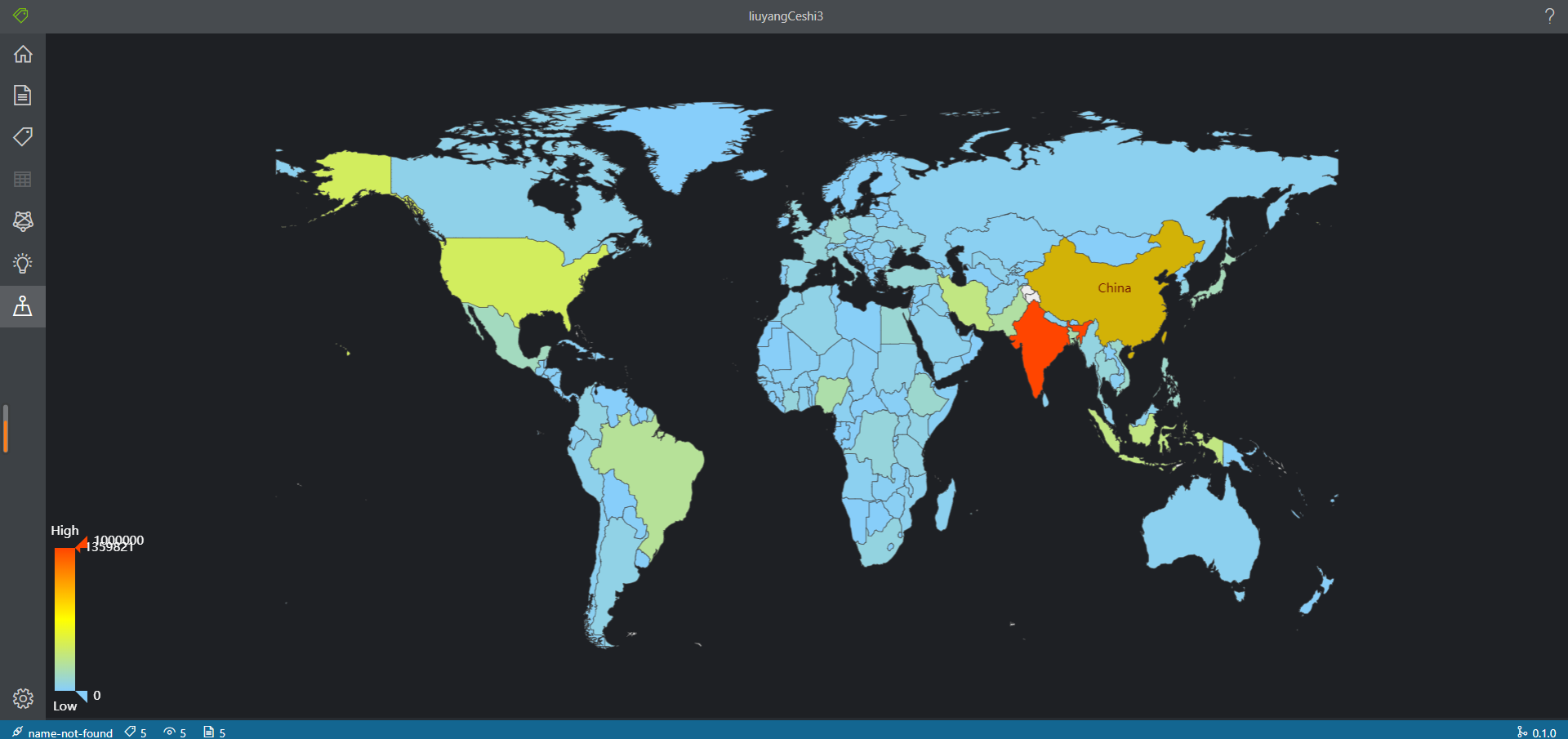
- 预测结果可视化
2. 修复的缺陷
-
tag页面同步导致的数据出错
因为原项目在数据同步时采用的是每一次都需要全部数据重新同步,导致标注的时候较慢。我们在这基础上优化并且修复了很多BUG,增加了部分提醒,一定程度上加快处理速度,提升了用户体验
-
tag页面目前是在更新的时候是强制锁定右侧编辑栏,同时保证其他功能正常使用;在对tag修改后,不再从azure重新读取数据而是前端动态更新,效率提高了60%以上
3. 运行环境
本项目为Web端应用,主流浏览器都可以使用
IE浏览器需要升级到chrome内核版本
4. 安装方法
无需安装,浏览器直接访问网页即可轻松使用!
入口2:https://namenotfound.wheremeow.com/
测试表单(可以从GitHub下载进行测试)
也可以从github上下载本项目,在本地部署使用npm编译运行前端工具
使用方法
5. 问题和限制
问题:
- tag页面的数据同步延迟大,需要等待一会,否则会报错
- 前端在测试过程中会不定时出现一些BUG,目前暂时没有解决
限制:
- 后端表单识别的服务使用的是免费版本,只有500个免费的表单,而且每分钟调用的次数有限,导致无法进行较大规模的使用(单纯用于软件体验还是可以支撑的)
- 实体识别API的服务也是免费版本,因此处理速度受限
- 目前数据可视化只支持地图展示,因为前面两条的原因导致这个功能使用需要等待较长时间
- 因为微软OCR的语言限制,目前软件支持的表单语言为英语
- 目前打开云端项目的功能无法使用,因为我们只有一个账号,所以把账号信息隐藏了,而这一功能需要指定特定的账号。
6. 发布方式和发布地址
- GitHub源码发布
- 微信群发布,在同学之间宣传
与Alpha阶段的对比
-
根据之前的反馈,我们增加了介绍页面,提供主要功能的使用流程。
-
优化了Tag页面标注的速度和用户体验
Alpha阶段标注页面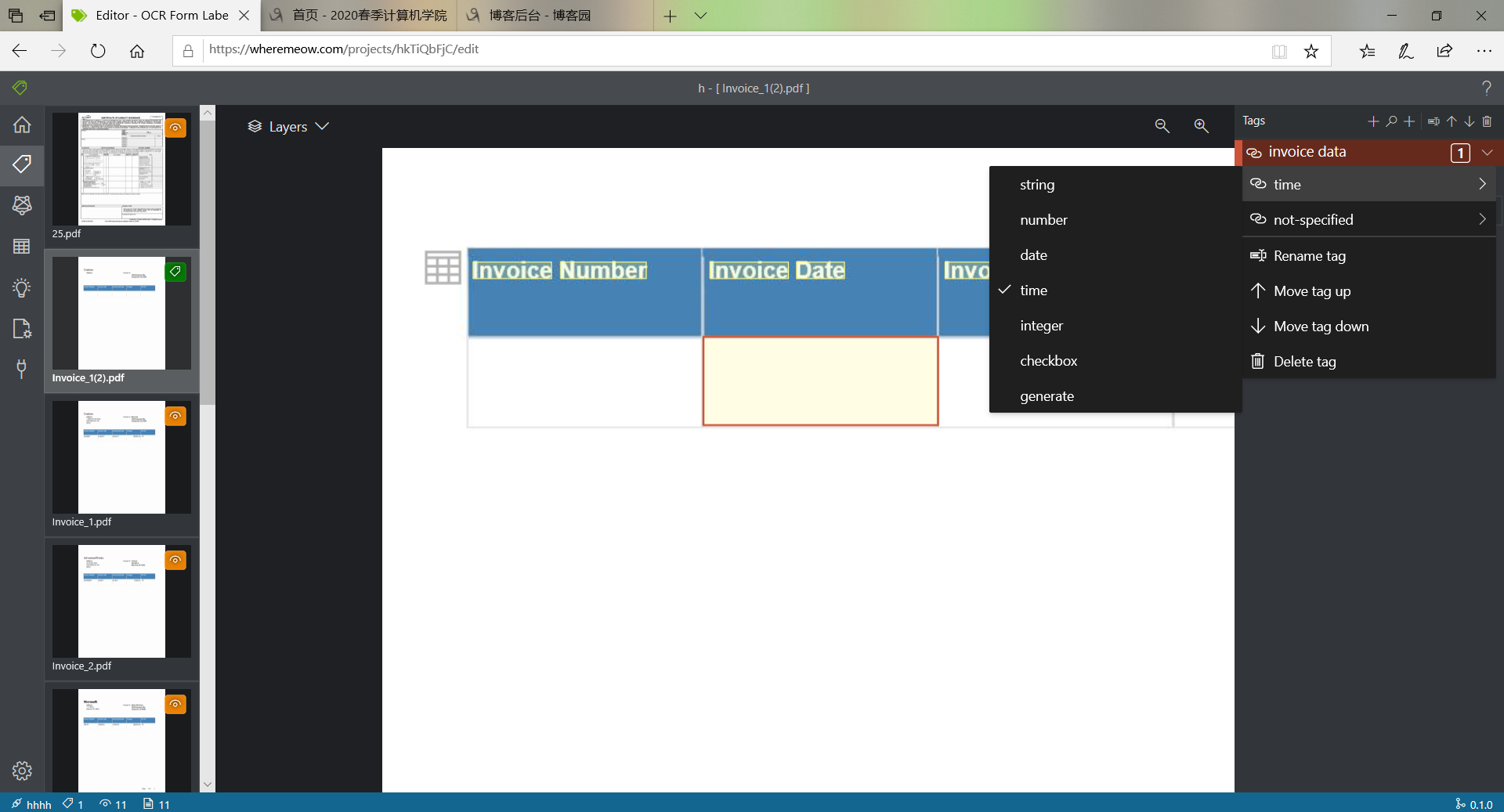
Beta阶段标注页面
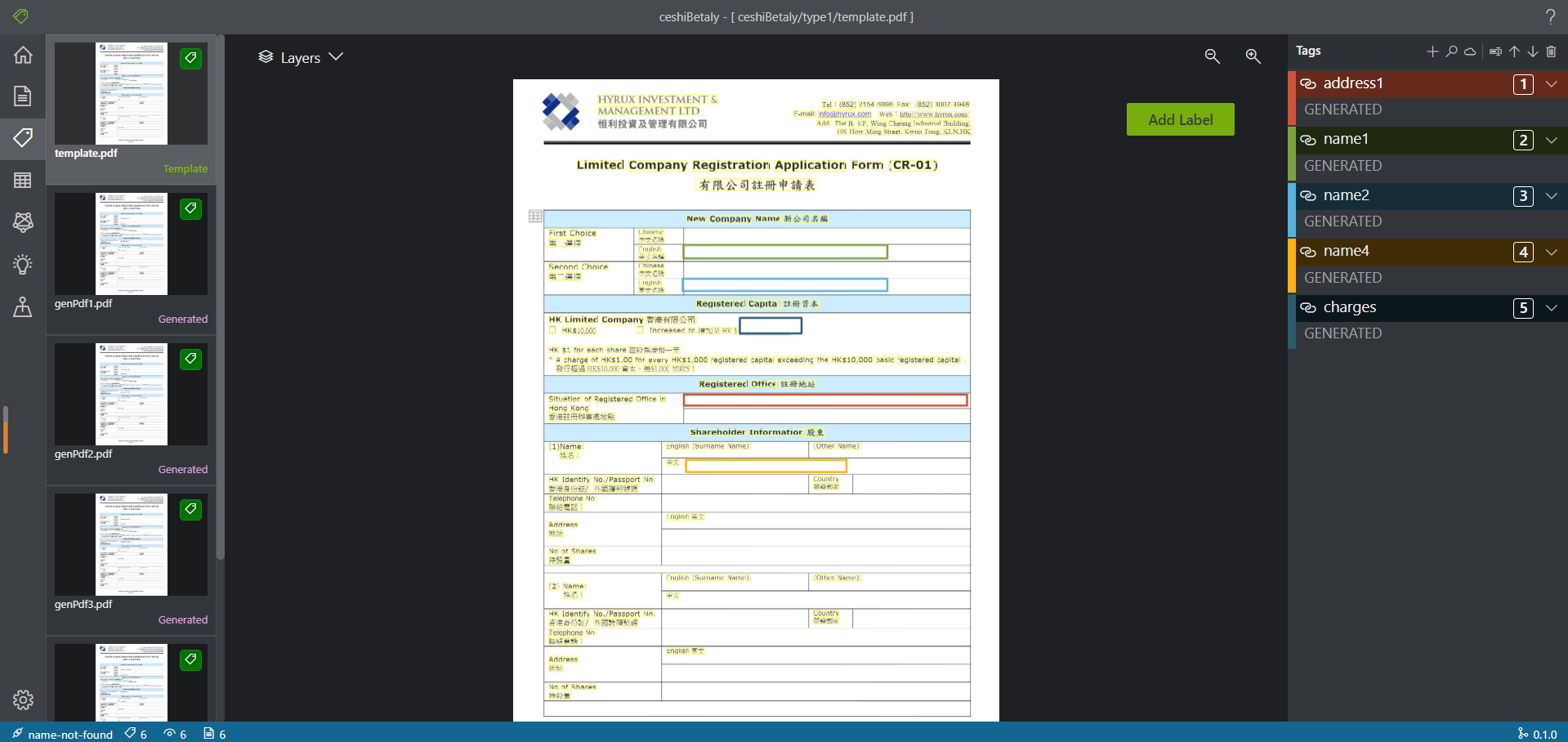
-
新增了自动化训练的功能,省去标注的流程,使得用户使用更方便(具体见上面新功能展示)
-
可视化展示数据,方便用户多维度查看数据(具体见上面新功能展示)
视频对比: