团队项目技术规格说明书
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | BUAA2019软件工程 |
| 这个作业的要求在哪里 | 作业要求 |
| 我们在这个课程的目标是 | 学会团队合作,共同开发一个完整的项目 |
| 这个作业在哪个具体方面帮助我们实现目标 | 项目技术规格制定与说明 |
概述
项目基于 Microsoft OCR Form Labeling Tool 进行开发。
前端
继续使用原项目的 React + Redux 技术栈,基于已有的组件开发 UI,增加新的页面。
- 使用 Create React App 进行开发测试以及发布。
- UI 设计基于 Microsoft Fluent UI 。
后端
原项目的服务完全基于Azure Cognitive Services,我们将在此基础上使用Azure的IaaS,FaaS等服务,开发和部署新的功能。
- 二进制文件存储:Azure Storage
- 数据库:Azure Cosmos DB,Azure SQL Database
- OCR识别:Azure Cognitive Services
- 计算:Azure Functions
后端通过RESTful API提供服务。
产品功能设计
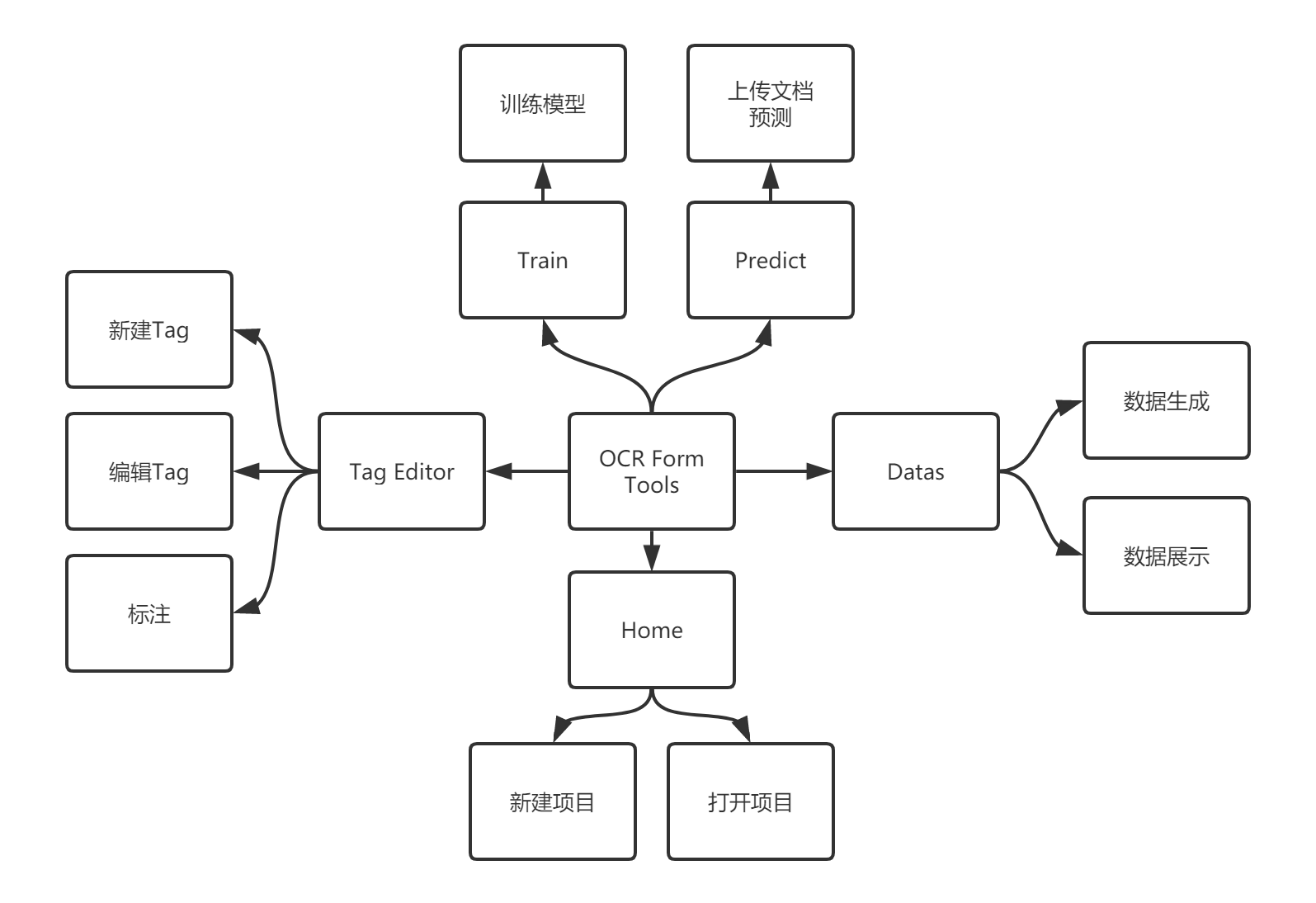
架构设计
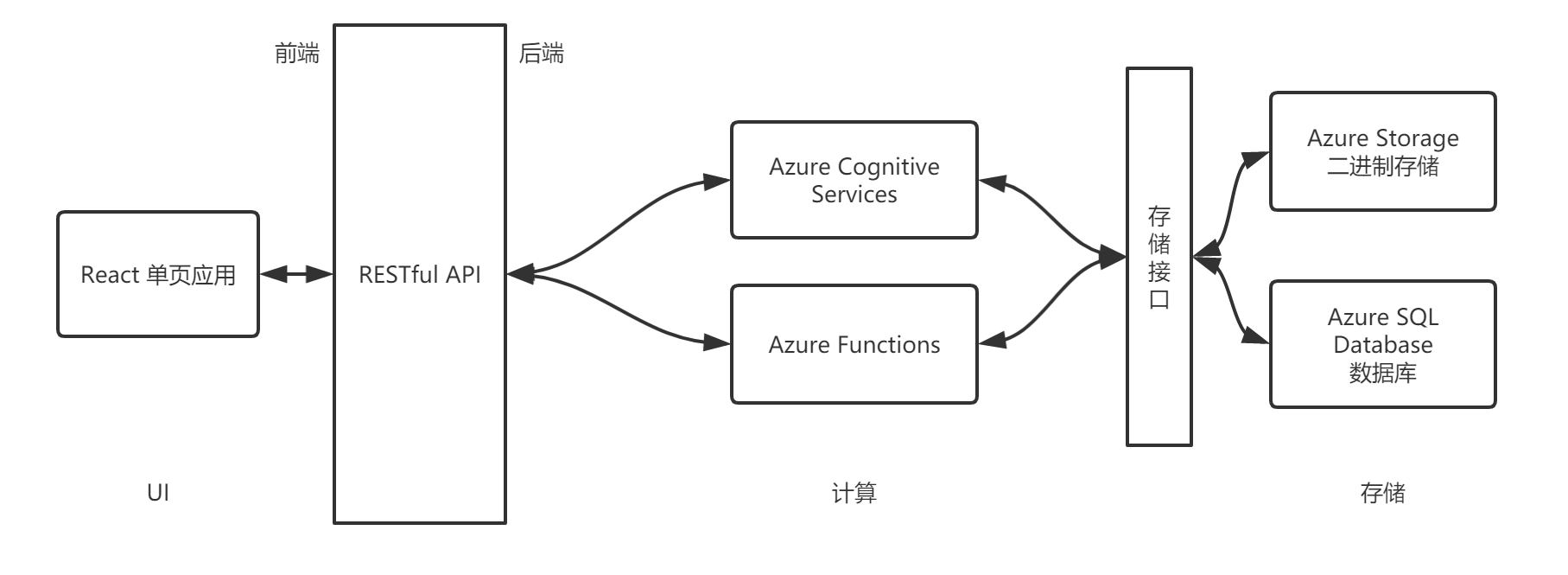
接口规格(暂定)
OCR
| 名称 | 请求方法 | 请求URL | 说明 |
|---|---|---|---|
| Analyze Form | POST | https://endpoint/formrecognizer/v2.0-preview/custom/models/modelId/analyze[?includeTextDetails] | 从表单和图形中提取结构化数据(键值对) |
| Analyze Layout | POST | https://endpoint/formrecognizer/v2.0-preview/layout/analyze | 从表单和图形中提取结构化数据(文本) |
| Analyze Receipt | POST | https://endpoint/formrecognizer/v2.0-preview/prebuilt/receipt/analyze[?includeTextDetails] | 从表单和图形中提取结构化数据(字段文本和语义值) |
| Train Custom Model | POST | https://endpoint/formrecognizer/v2.0-preview/custom/models | 创建并训练自定义模型 |
| Get Analyze Form Result | GET | https://endpoint/formrecognizer/v2.0-preview/custom/models/{modelId}/analyzeResults/{resultId} | 获得分析结果 |
| List Custom Models | GET | https://endpoint/formrecognizer/v2.0-preview/custom/models[?op] | 获得所有模型的信息 |
| Get Custom Model | GET | https://endpoint/formrecognizer/v2.0-preview/custom/models/{modelId}[?includeKeys] | 获得一个模型的具体信息 |
存储
| 名称 | 请求方法 | 请求URL | 说明 |
|---|---|---|---|
| Put Blob | PUT | https://endpoint/mycontainer/myblob | 创建新的Blob存储 |
| Get Blob | GET | https://endpoint/mycontainer/myblob | 读取或下载Blob |
| Delete Blob | DELETE | https://endpoint/mycontainer/myblob | 标记特定的Blob为删除 |
其他计算功能
| 名称 | 请求方法 | 请求URL | 说明 |
|---|---|---|---|
| Generate PDF | POST | https://endpoint/generate/pdf | 从模板生成PDF文档与json格式的标注数据 |
| Generate PDF | POST | https://endpoint/download/pdf | 下载生成好的PDF文档与json格式的标注数据 |
分析
抽象
我们的架构进行了两层的抽象,基于MVC模型进行开发,以降低各模块之间的耦合程度,提高封装性,提高开发和维护效率。
-
前后端分离
前后端是完全分离的。前端是一个React应用,最终生成为一个单页应用,通过RESTful与后端进行交互。
前端和后端是单项绑定的,后端的数据变化会引起前端显示的变化。
前端也会调用API使得后端进行数据的处理和生成。
-
计算与存储分离
后端会对存储进行封装,这样不论是云数据库还是自己部署数据库,都可以灵活的进行切换。后端对数据库的使用通过ORM进行,使得各种数据库间也可以灵活的变更和迁移。
内聚/耦合/模块化
通过两次的抽象和分离,UI,计算和存储层(即MVC模型)可以在内部专注于自身的工作,并且各层之间实现解耦。做到高内聚和低耦合。
View和Controller都是无状态的,可以很容易进行扩展。因为进行了Model的抽象,实现了模块化,容易在Controller对Model的功能进行复用,实现新的功能。
信息隐藏和封装
通过MVC模型在各层之间实现了封装和隐藏,各层之间通过API进行交互。例如UI可以通过API获取后端的文档数据,但不能随意的进行修改,只能通过调用相应的API,通过后端的计算模块进行限制性的文档处理和修改。
此外在各层内部。React框架通过组件进行设计,各组件之间存在着信息的隐藏和封装,只能按照接口进行数据的传递。计算模块则本身是分离的,每个计算功能是单独实现的,相互之间没有直接交互,只能通过数据层进行间接的交互。
界面和实现的分离
前后端使用 RESTful API 交互,界面和实现是完全分离的。前端的UI专注与数据的显示和可视化,通过RESTful API完成前后端的数据同步,以在后端进行数据的生成,或在前端完成数据的显示。
界面和实现的分离使得后续可以没有障碍的进行其他平台(例如移动端)的UI和App开发。
如何处理错误情况
错误情况由API的条件进行约束,包括输入输出参数,以及环境(存储的数据)决定。分为以下几个部分。
-
UI操作错误
- 用户使用上的错误应当尽可能控制在前端,通过界面显示给用户。
-
请求错误
- 参数错误:http请求中的参数不符合API,后端将返回错误码和信息
- 内部错误:后端在执行中发现错误,向前端返回错误码。
-
内部错误
- 后端程序在计算或数据存储过程中发现错误,将通过log进行记录,并向前端返回错误码。
应对变化的灵活性
因为实现了良好的抽象,信息隐藏和封装,各层之间的分离,可以很容易的进行扩展和修改。后端的计算部分是无状态的,只在相应前端请求时进行数据的读写,因此容易添加新的功能,并且可以轻松的在多个服务器上进行部署,并进行负载均衡。前端的React框架是组件式的设计,容易进行复用,组合和扩展,也具有很好的灵活性。在封装的基础上,后端的存储数据库和基础设施也容易进行迁移和替换。
对大量数据的处理能力
我们的处理都是基于Azure的Serverless服务,因此是不受用户数量,存储容量,性能约束的。这是一种基于用量的服务,Azure会根据使用情况,自动的完成服务的弹性伸缩和负载均衡,因此可以做到对大量数据的处理能力。
此外我们的前端也会部署在云服务上,因为是静态的Web单页应用,可以通过CDN实现低延迟和大规模的访问。