参考:https://www.jianshu.com/p/f3b92124cd2b
互信息
衡量两个随机变量之间的相关性,两个随机变量相关信息的多少。
随机变量就是随机试验结果的量的表示,可以理解为按照某个概率分布进行取值的变量,比如袋子里随机抽取一个小球就是一个随机变量,互信息就是对x和y所有可能
的取值的点互信息的加权和。
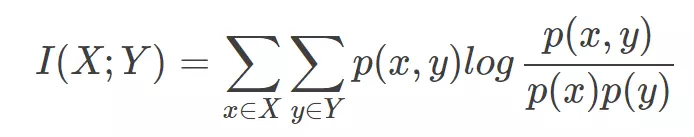
点的互信息PMI从互信息中衍生出来的
PMI用来衡量两个事物之间的相关性,公式![]()
在概率论中,当p(x,y) = p(x) * p(y)我们说x于y相互独立。当概率加上log后,就变成了信息量。
例子:
衡量like这个词的极性(为正向情感还是负向情感),提前调一个正向情感的词如nice,算nice和like的PMI
PMI(like,nice) = log(p(like,nice)/p(like)p(nice))。PMI越大表示两个词的相关性就越大,nice的正向情感就越明显。
编程求解互信息:
1 from sklearn import metrics as mr 2 mr.mutual_info_score([1,2,3,4],[4,3,2,1])
tf-idf
tf:Term Frequency 词频
idf: Inverse Document Frequency逆文档频率
在开始,我们用词频来衡量一个词的重量程度,这一点是不科学的,如进行简历筛选时,大部分人都有的技能并不是HR想要寻找的,反而是那些出现频率低的。
所以就出现了idf。
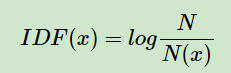
N代表语料库中文本的总数,N(x)代表语料库中包含x的文本数目。可见出现的频率越低,IDF值越大。
避免0概率事件,我们要进行平滑。

右边+1是为了避免该词在所有文本中都出现过,(N(x) = N ,log1=0)。
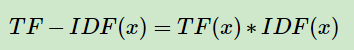
TF(x)指词在当前文本中的词频。
利用sklearn进行统计tfidf值
1 from sklearn.feature_extraction.text import TfidfVectorizer 2 corpus = [ 3 'this is the first document', 4 'this is the second second document', 5 'and the third one', 6 'is this the first document' 7 ] 8 tfidf = TfidfVectorizer() 9 res = tfidf.fit_transform(corpus) 10 print(res)
(0, 8) 0.4387767428592343 (0, 3) 0.4387767428592343 (0, 6) 0.35872873824808993 (0, 2) 0.5419765697264572 (0, 1) 0.4387767428592343 (1, 8) 0.27230146752334033 (1, 3) 0.27230146752334033 (1, 6) 0.2226242923251039 (1, 1) 0.27230146752334033 (1, 5) 0.8532257361452784 (2, 6) 0.2884767487500274 (2, 0) 0.5528053199908667 (2, 7) 0.5528053199908667 (2, 4) 0.5528053199908667 (3, 8) 0.4387767428592343 (3, 3) 0.4387767428592343 (3, 6) 0.35872873824808993 (3, 2) 0.5419765697264572 (3, 1) 0.4387767428592343
输出结果为:(文本id,词id)tfidf值