哈夫曼编码测试
测试要求
- 设有字符集:S={a,b,c,d,e,f,g,h,i,j,k,l,m,n.o.p.q,r,s,t,u,v,w,x,y,z}。
给定一个包含26个英文字母的文件,统计每个字符出现的概率,根据计算的概率构造一颗哈夫曼树。
并完成对英文文件的编码和解码。
要求:
- (1)准备一个包含26个英文字母的英文文件(可以不包含标点符号等),统计各个字符的概率
- (2)构造哈夫曼树
- (3)对英文文件进行编码,输出一个编码后的文件
- (4)对编码文件进行解码,输出一个解码后的文件
- (5)撰写博客记录实验的设计和实现过程,并将源代码传到码云
- (6)把实验结果截图上传到云班课
设计思路
- 把字符从文件中取出来,这是以前学过的IO流实现的。
- 统计出现的字符及频率,将各个字符创建为叶子结点,频率为结点的权值,用链表保存这些叶子结点。
- 将所有带权值的结点按权值从小到大排列;
- 依次选取权值最小的结点放在树的底部,权值小的在左边(取出的结点相当于从这些结点的集合中剔除);
- 生成一个新节点作为这两个结点的父节点,且父节点的权值等于这两个结点权值之和,然后要把这个新结点放回我们需要构成树的结点中,继续进行排序;
- 重复上述2、3步骤,直至全部节点形成一棵树,此树便是哈夫曼树,最后生成的结点即为根节点。这样构成的哈夫曼树,所有的存储有信息的结点都在叶子结点上。
- 解码就是在二进制字符串中匹配字符哈夫曼编码,找到对应的字符不断输出。
- 理论上来说就是这么几步了。
操作过程
结点类
- 我是在二叉树结点的基础上修改一下,主要是多定义了节点的哈夫曼编码、节点的权值。
public class HNode {
public String code = "";// 节点的哈夫曼编码
public String data = "";// 节点的数据
public int count;// 节点的权值
public HNode left;
public HNode right;
public HNode(String data, int count) {
this.data = data;
this.count = count;
}
public HNode(int count, HNode lChild, HNode rChild) {
this.count = count;
this.left = lChild;
this.right = rChild;
}
public HNode getLeft() {
return left;
}
public void setLeft(HNode left) {
this.left = left;
}
public HNode getRight() {
return right;
}
public void setRight(HNode right) {
this.right = right;
}
}
哈夫曼树类


private void Sort(LinkedList<HNode> nodelist) {
for (int i = 0; i < nodelist.size() - 1; i++) {
for (int j = i + 1; j < nodelist.size(); j++) {
HNode temp;
if (nodelist.get(i).count > nodelist.get(j).count) {
temp = nodelist.get(i);
nodelist.set(i, nodelist.get(j));
nodelist.set(j, temp);
}
}
}
}`
- 之后取出权值最小的两个节点,生成一个新的父节点,删除权值最小的两个节点,将父节点存放到列表中,并不断重复,直到得到根节点。




- 需要解码的二进制字符串,匹配字符哈夫曼编码,找到对应的字符
测试类
File file = new File("C:\Users\lenovo\IdeaProjects\why20172321\src\week10\哈夫曼树解码\hfm.txt");
Reader reader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(reader);
String data = bufferedReader.readLine();
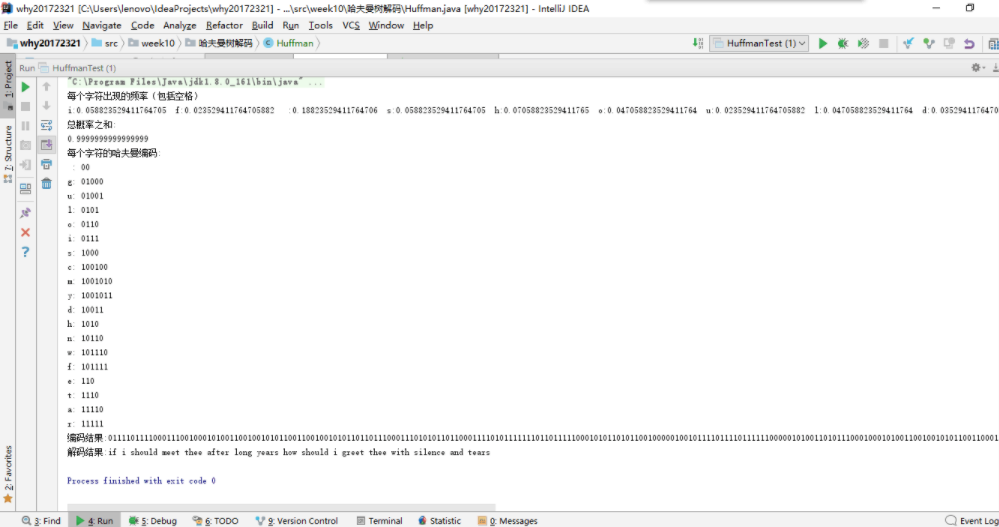
- 输出一下每个数的概率和对应的哈夫曼编码。
- 得到编码结果并输入文件,然后读取文件进行解码,并将解码内容输出。


测试结果