<1> load average
先来看一下linux中存活状态下进程的粗略分类:
a. blocking process, 可能在等在IO或者自己调用wait系列的函数
b. runnable process, 所有资源一切就绪,就差cpu了,在任务队列里排队等待cpu资源
c. running process, 正在cpu上运行的进程
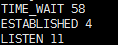
load average 被定义为,在特定的时间间隔,runnable process + running process 的平均数量。这个平均数量是使用cpu平均的。这里cpu应该视为核心,也就是说,两个物理cpu和一个双核cpu是一样的,会被统一当做2个cpu核心来计算负载。常用的获取 load average的方式有top和uptime命令2种。以uptime命令为例:

最开头的一系列信息代表当前时间和机器已经运行的时间(已经运行了1070天零5小时7分钟)。6 users 代表当前一共有6个用户登录。最后3个数字就是 load average, 分别是1分钟,5分钟,15分钟的 load average。
以一颗cpu核心的机器为例。load average 在 0 到 1 之间表示 cpu 还有剩余资源,进程运行通畅。等于1表示系统已经没有剩余的cpu资源了,对于多个进程满打满算刚够用。如果超过1,则说明系统此时正在超负荷运行。load average 一般维持在0.7左右比较好。对于2个cpu核心的机器,那么load average超过2才说明系统正在超负荷运行。其他的以此类推。
<2>查看进程使用的内存大小
a. 直接 cat /proc/$pid/status

VmRss代表进程占用的物理内存。
b. pmap -x $pid
该命令最后一行会输出如下信息,中间的那个数字就是进程占用的物理内存

c. 使用top命令后,按下M,会按照内存使用从大到小进行排序
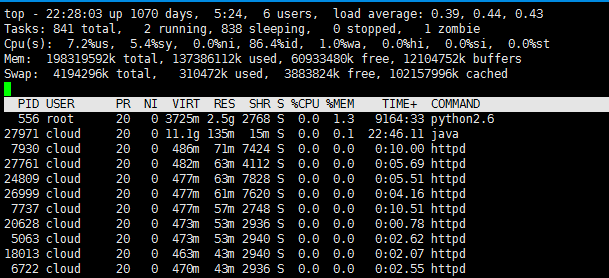
VIRT, RES, SHR 分别代表进程使用的虚拟内存,物理内存,共享内存大小
<3> 机器连接数
主要使用netstat,比如统计连接中各个状态的数量:
netstat -a | awk '/^tcp/ {++STATE[$NF]} END {for(a in STATE) print a, STATE[a]}'