数据操作
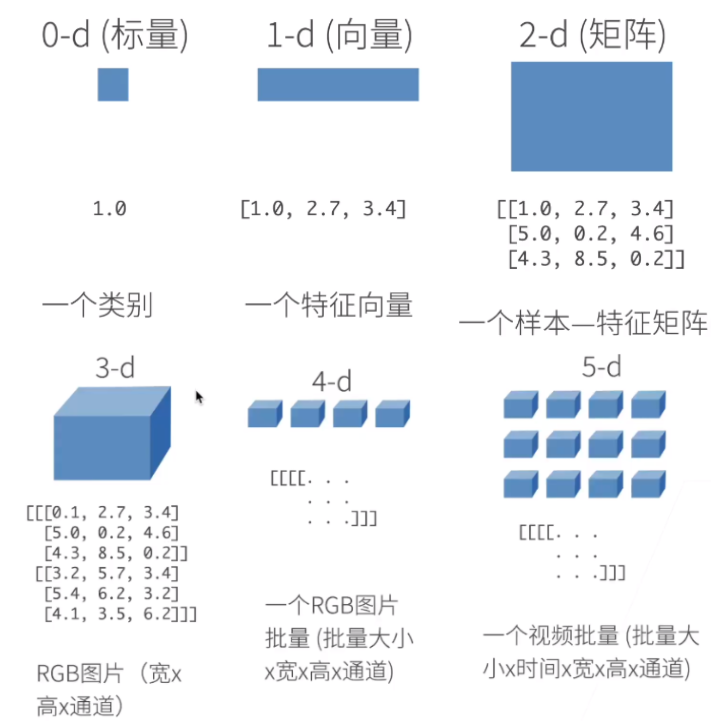
1. N维数组样例
- N维数组是机器学习和神经网络的主要数据结构
2. 创建数组及数组操作
- 创建数组需要、
- 形状:比如说创建一个三行四列(3×4)的矩阵
- 每个元素的数据类型:比如创建一个32位浮点数
- 每个元素具备的初始值
导包
import torch
张量表示一个数值组成的数组,这个数组可能有多个维度
x = torch.arange(12)
x
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
通过张量的shape和numel属性来访问张量的形状和张量中的元素的总数
x.shape
torch.Size([12])
x.numel()
12
改变一个张量的形状而不改变元素数量和元素值,采用reshape
x = x.reshape(3,4)
x
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
使用全0、全1、其他常量或者从特定分布中随机采样的数字
torch.zeros((2,3,4))
tensor([[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]])
torch.ones((2,3,4))
tensor([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
通过提供包含数值的Python列表为张量中的元素赋值
torch.tensor([[2,1,4,3],[1,2,3,4],[4,3,2,1]])
tensor([[2, 1, 4, 3],
[1, 2, 3, 4],
[4, 3, 2, 1]])
常见标准算术运算符都可以按元素运算
x = torch.tensor([1.0,2,4,8])
y = torch.tensor([2,2,2,2])
print(x+y)
print(x-y)
print(x*y)
print(x/y)
print(x**y)
tensor([ 3., 4., 6., 10.])
tensor([-1., 0., 2., 6.])
tensor([ 2., 4., 8., 16.])
tensor([0.5000, 1.0000, 2.0000, 4.0000])
tensor([ 1., 4., 16., 64.])
按元素应用其他计算,如:取对数运算
torch.exp(x)
tensor([2.7183e+00, 7.3891e+00, 5.4598e+01, 2.9810e+03])
多个张量的连结
X = torch.arange(12,dtype = torch.float32).reshape(3,4)
Y = torch.tensor([[2.0,1,4,3],[1,2,3,4],[4,3,2,1]])
torch.cat((X,Y),dim = 0)
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[ 2., 1., 4., 3.],
[ 1., 2., 3., 4.],
[ 4., 3., 2., 1.]])
torch.cat((X,Y),dim = 1)
tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],
[ 4., 5., 6., 7., 1., 2., 3., 4.],
[ 8., 9., 10., 11., 4., 3., 2., 1.]])
通过逻辑运算符构建二元张量
X == Y
tensor([[False, True, False, True],
[False, False, False, False],
[False, False, False, False]])
对张量中的所有元素进行求和会产生一个只有一个元素的张量
X.sum()
tensor(66.)
即使形状不同,我们仍然可以通过调用广播机制来执行按元素操作
a = torch.arange(3).reshape((3,1))
b = torch.arange(2).reshape((1,2))
a,b
(tensor([[0],
[1],
[2]]),
tensor([[0, 1]]))
a+b
tensor([[0, 1],
[1, 2],
[2, 3]])
元素访问
X[-1],X[1:3]
(tensor([ 8., 9., 10., 11.]),
tensor([[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]]))
指定索引向矩阵中写入元素
X[1,2] = 9
X
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 9., 7.],
[ 8., 9., 10., 11.]])
运行一些操作可能会导致为新结果分配内存
id用来存储的obj在python中的唯一标识号
before = id(Y)
Y = Y + X
id(Y) == before
False
执行原地操作
Z = torch.zeros_like(Y)
print('id(Z):',id(Z))
Z[:] = X + Y
print('id(Z):',id(Z))
id(Z): 2254377056704
id(Z): 2254377056704
如果后续计算中没有重复使用X,我们可以使用X[:] = X+Y或X += Y来减少操作的内存开销
before = id(X)
X += Y
id(X) == before
True
转换为NumPy张量
A = X.numpy()
B = torch.tensor(A)
type(A),type(B)
(numpy.ndarray, torch.Tensor)
将大小为1的张量转换为Python标量
a = torch.tensor([3.5])
a,a.item(),float(a),int(a)
(tensor([3.5000]), 3.5, 3.5, 3)
3. 数据预处理
创建一个人工数据集,并存储在csv(逗号分隔值)文件
import os
os.makedirs(os.path.join('..','data'), exist_ok = True)
data_file = os.path.join('..','data','house_tiny.csv')
with open(data_file,'w') as f:
f.write('NumRooms,Alley,Price
') #列名
f.write('NA,Pave,127500
') #每行表示一个数据样本
f.write('2,NA,106000
')
f.write('4,NA,178100
')
f.write('NA,NA,140000
')
从创建的csv文件中加载原始数据集
import pandas as pd
data = pd.read_csv(data_file)
print(data)
NumRooms Alley Price
0 NaN Pave 127500
1 2.0 NaN 106000
2 4.0 NaN 178100
3 NaN NaN 140000
为了处理缺失的数据,典型的方法包括插值和删除,这里我们考虑插值。
inputs,outputs = data.iloc[:,0:2],data.iloc[:,2]
inputs = inputs.fillna(inputs.mean())
print(inputs)
NumRooms Alley
0 3.0 Pave
1 2.0 NaN
2 4.0 NaN
3 3.0 NaN
对于inputs中的类别值或离散值,我们将"NaN"视为一个类别
#将类别变成数值特征
inputs = pd.get_dummies(inputs,dummy_na=True)
print(inputs)
NumRooms Alley_Pave Alley_nan
0 3.0 1 0
1 2.0 0 1
2 4.0 0 1
3 3.0 0 1
现在inputs和outputs中所有条目都是数值类型,它们可以转换成张量格式
import torch
x,y = torch.tensor(inputs.values),torch.tensor(outputs.values)
print(x,y)
tensor([[3., 1., 0.],
[2., 0., 1.],
[4., 0., 1.],
[3., 0., 1.]], dtype=torch.float64) tensor([127500, 106000, 178100, 140000])