mysql语句练习
本博文涉及知识点:
- 联表查询(内联表、左联表)
- 分组查询
- 自定义变量 与 SET函数
- DATEDIFF()函数
1,概述
我们日常使用sql数据库,基本都是一些curd,下面是一些语句练习,方便后续进行dba操作
2,数据准备
-- 建表
-- 学生表
CREATE TABLE Student(
s_id VARCHAR(20),
s_name VARCHAR(20) NOT NULL DEFAULT '',
s_birth VARCHAR(20) NOT NULL DEFAULT '',
s_sex VARCHAR(10) NOT NULL DEFAULT '',
PRIMARY KEY(s_id)
);
-- 课程表
CREATE TABLE Course(
c_id VARCHAR(20),
c_name VARCHAR(20) NOT NULL DEFAULT '',
t_id VARCHAR(20) NOT NULL,
PRIMARY KEY(c_id)
);
-- 教师表
CREATE TABLE Teacher(
t_id VARCHAR(20),
t_name VARCHAR(20) NOT NULL DEFAULT '',
PRIMARY KEY(t_id)
);
-- 成绩表
CREATE TABLE Score(
s_id VARCHAR(20),
c_id VARCHAR(20),
s_score INT(3),
PRIMARY KEY(s_id,c_id)
);
-- 插入学生表测试数据
insert into Student values('01' , '赵雷' , '1990-01-01' , '男');
insert into Student values('02' , '钱电' , '1990-12-21' , '男');
insert into Student values('03' , '孙风' , '1990-05-20' , '男');
insert into Student values('04' , '李云' , '1990-08-06' , '男');
insert into Student values('05' , '周梅' , '1991-12-01' , '女');
insert into Student values('06' , '吴兰' , '1992-03-01' , '女');
insert into Student values('07' , '郑竹' , '1989-07-01' , '女');
insert into Student values('08' , '王菊' , '1990-01-20' , '女');
-- 课程表测试数据
insert into Course values('01' , '语文' , '02');
insert into Course values('02' , '数学' , '01');
insert into Course values('03' , '英语' , '03');
-- 教师表测试数据
insert into Teacher values('01' , '张三');
insert into Teacher values('02' , '李四');
insert into Teacher values('03' , '王五');
-- 成绩表测试数据
insert into Score values('01' , '01' , 80);
insert into Score values('01' , '02' , 90);
insert into Score values('01' , '03' , 99);
insert into Score values('02' , '01' , 70);
insert into Score values('02' , '02' , 60);
insert into Score values('02' , '03' , 80);
insert into Score values('03' , '01' , 80);
insert into Score values('03' , '02' , 80);
insert into Score values('03' , '03' , 80);
insert into Score values('04' , '01' , 50);
insert into Score values('04' , '02' , 30);
insert into Score values('04' , '03' , 20);
insert into Score values('05' , '01' , 76);
insert into Score values('05' , '02' , 87);
insert into Score values('06' , '01' , 31);
insert into Score values('06' , '03' , 34);
insert into Score values('07' , '02' , 89);
insert into Score values('07' , '03' , 98);
3,进阶语句
1、查询课程编号为“01”的课程比“02”的课程成绩高的所有学生的学号。
要点:联结
难度:5
-- 直接连表查询
select a.s_id
from Score a
join Score b on a.s_id = b.s_id and a.s_score > b.s_score
where a.c_id = '01'
and b.c_id = '02';
-- 组合成新表查询
select a.s_id
from (select * from Score where c_id = '01') as a
join (select * from Score where c_id = '02') as b
on a.s_id = b.s_id
where a.s_score > b.s_score;
2、查询平均成绩大于60分的学生的学号和平均成绩
难度:3
-- 直接分组进行解决
select s_id,avg(s_score)
from Score group by s_id having avg(s_score)>60;
3、查询所有学生的学号、姓名、选课数、总成绩
要点:内联结
难度:4
select s.s_id as '学号', s.s_name '姓名', sc.count '选课数', sc.sum '总成绩'
from Student s
inner join (select s_id, sum(s_score) as sum, count(s_score) as count
from Score
group by s_id) as sc on sc.s_id = s.s_id;
select Score.s_id AS 学号, s_name AS 姓名, count(c_id) AS 选课数, sum(s_score) AS 总成绩
from Score
join Student on Score.s_id = Student.s_id
group by Score.s_id, s_name;
4、查询姓“张”的老师的个数
难度:2
select count(t_id)
from Teacher
where t_name like '张%';
拓展知识:在进行计数时,
5.查询没学过“张三”老师课的学生的学号、姓名(重点)
要点: 三表联结
难度:5
-- 多次联表查询
select s_id, s_name
from Student
where s_id not in (select S.s_id
from Student
join Score S on Student.s_id = S.s_id
where c_id = (select c_id
from Teacher
join Course C on Teacher.t_id = C.t_id
where t_name = '张三'));
select s_id, s_name
from Student
where s_id not in
(select s_id
from Score
join Course on Score.c_id = Course.c_id
join Teacher on Course.t_id = Teacher.t_id
where t_name = '张三');
6、查询学过“张三”老师所教的所有课的同学的学号、姓名
要点: 同上第5题
难度:5
-- 难点在于如何统计学完所有的课程的学生
-- 例如:张三教学2门课,将
select S.s_id, s_name
from Student
join Score S on Student.s_id = S.s_id
where c_id in (select c_id
from Teacher
join Course C on Teacher.t_id = C.t_id
where t_name = '张三')
group by S.s_id
having count(c_id) = (select count(c_id)
from Teacher
join Course C on Teacher.t_id = C.t_id
where t_name = '张三');
拓展点:我觉得参考链接1中的解答是错误的,我上面给出来的解答才是正确的
他的解答应该是查询 学习过张三老师课程的学生信息,而不是-学过“张三”老师所教的所有课,注意后面的所有课这个限定词!
7、查询学过编号为“01”的课程并且也学过编号为“02”的课程的学生的学号、姓名
难度:5
-- 直接分组,然后使用count限定一下个数
select Student.s_id, s_name
from Student
join Score S on Student.s_id = S.s_id
where c_id in ('01', '02')
group by s_name, S.s_id
having count(c_id) = 2;
-- 直接分别查询,然后联表
select s_id, s_name
from Student
where s_id in
(select a.s_id from
(select s_id from Score where c_id = '01') as a
join (select s_id from Score where c_id ='02') as b
on a.s_id= b.s_id);
-- 直接查询,然后过滤
select s_id, s_name
from Student
where s_id in
(select s_id from Score where c_id = '01')
AND s_id in
(select s_id from Score where c_id = '02');
-- 直接联表筛选
select a.s_id, a.s_name
from Student a
JOIN Score b ON a.s_id = b.s_id
JOIN Score c ON a.s_id = c.s_id
where b.c_id = '01'
and c.c_id = '02'
and b.s_id = c.s_id;
8、查询课程编号为“02”的总成绩
要点:聚合
难度:2
-- 很简单直接查询即可
select sum(s_score)
from Score
where c_id = '02'
9、查询所有课程成绩小于60分的学生的学号、姓名
难度:5
-- 直接联表后进行条件过滤
select distinct S.s_id, s_name
from Student
join Score S on Student.s_id = S.s_id
where s_score < 60;
10、查询没有学全所有课的学生的学号、姓名
难度:5
-- 直接分组,然后联表查询
select S.s_id, s_name
from Student
join Score S on Student.s_id = S.s_id
group by S.s_id, s_name
having count(c_id) < (select count(c_id)
from Course);
-- 整体的解体思路就是需要分组
select s_id, s_name
from Student
where s_id IN (SELECT s_id
FROM Score
group by s_id
having count(c_id) < (select count(c_id) from Course));
11、查询至少有一门课与学号为“01”的学生所学课程相同的学生的学号和姓名
要点:联结
难度:5
-- 直接查询即可,注意需要排除01自身数据
select distinct S.s_id, s_name
from Student
join Score S on Student.s_id = S.s_id
where c_id in (select c_id
from Score
where s_id = '01')
and S.s_id <> '01';
12、查询和“01”号同学所学课程完全相同的其他同学的学号
难度:5
-- 分组、联表
select s_id
from Score
where c_id in
(select c_id from Score where s_id = '01')
and s_id <> '01'
group by s_id
having count(c_id) = (select count(c_id) from Score where s_id = '01');
13、把“SCORE”表中“张三”老师教的课的成绩都更改为此课程的平均成绩
难度:5
-- 难度相对较大,但是仔细拆分后也很简单
update Score
set s_score = (select avg_score
from (select c_id, avg(s_score) as avg_score
from Score
where c_id in (select c_id
from Teacher
join Course C on Teacher.t_id = C.t_id
where t_name = '张三')
group by c_id) as avg
where Score.c_id = avg.c_id)
where c_id in (select c_id
from Teacher
join Course C on Teacher.t_id = C.t_id
where t_name = '张三');
-- 这种解法更优!update语句中进行联表查询
update Score as a join
(select avg(s_score) as t, Score.c_id
from Score
join Course on Score.c_id = Course.c_id
join Teacher on Teacher.t_id = Course.t_id
where t_name = '张三'
group by c_id) as b#张三老师教的课与平均分
on a.c_id = b.c_id
set a.s_score= b.t;
14、查询和“02”号的同学学习的课程完全相同的其他同学学号和姓名(同12题,略)
难度:5
15、删除学习“张三”老师课的SC表记录
难度:5
delete
from Score
where c_id in (select c_id
from Teacher
join Course C on Teacher.t_id = C.t_id
where t_name = '张三');
17、按平均成绩从高到低显示所有学生的语文,数学,英语三门的课程成绩,按如下形式显示:学生ID,语文,数学,英语,有效课程数,有效平均分
难度:5
-- 需要额外拆分进行查询
-- 1,先根据分组来进行计数和计算平均值
-- 2,需要左联表查询,因为某些课程null值也需要显示出来
select avg.s_id as 学生ID, s1.s_score 语文, s2.s_score 数学, s3.s_score 外语, avg.cnt 有效课程数, avg.avg 有效平均分
from (select Score.s_id,
count(c_id) as cnt,
avg(s_score) as avg
from Score
group by Score.s_id
order by avg(s_score) DESC) avg
left join (select s_id, s_score from Score where c_id = '01') as s1 on avg.s_id = s1.s_id
left join (select s_id, s_score from Score where c_id = '02') as s2 on avg.s_id = s2.s_id
left join (select s_id, s_score from Score where c_id = '03') as s3 on avg.s_id = s3.s_id;
-- 这种解法也是正确的
select s_id as 学生ID,
(select s_score from Score where Score.s_id = 学生ID and c_id='01') as 语文,
(select s_score from Score where Score.s_id = 学生ID and c_id='02') as 数学,
(select s_score from Score where Score.s_id = 学生ID and c_id='03') as 英语,
count(c_id) as 有效课程数,
avg(s_score) as 有效平均分
from Score
group by s_id
order by avg(s_score) DESC;
-- 原参考链接1中,给出的查询语句(下面的就是)好像是错误的
-- 错误原因是:他给出的是分组查询,但是又使用到没有在group by中的字段,所以有问题 todo 后续再次检查该解法
select s_id as ‘学生ID’,
(case when c_id='01' then s_score else NULL end) as 语文,
(case when c_id='02' then s_score else NULL end) as 数学,
(case when c_id='03' then s_score else NULL end) as 英语,
count(c_id) as 有效课程数,
avg(s_score) as 有效平均分
from Score
group by s_id
order by avg(s_score) DESC;
18、查询各科成绩最高和最低的分: 以如下的形式显示:课程ID,最高分,最低分
难度:3
-- 直接使用group by相关的函数解决(bytedance preview)
select c_id 课程ID, max(s_score) 最高分, min(s_score) 最低分
from Score
group by c_id;
19、按各科平均成绩从低到高和及格率的百分数从高到低排列,以如下形式显示:课程号,课程名,平均成绩,及格百分数
要点:关联查询
难度:5
-- 需要额外注意,及格数据的统计
select Score.c_id 课程号,
C.c_name 课程名,
avg(s_score) 平均成绩,
concat(sum(case when s_score >= 60 then 1 else 0 end) / count(s_score) * 100, '%') 及格百分数
from Score
join Course C on Score.c_id = C.c_id
group by Score.c_id, C.c_name
order by 平均成绩, 及格百分数 DESC;
-- 另外一种解法
select a.c_id as 课程号,c_name as 课程名,avg(s_score) as 平均成绩,
concat((select count(b.s_score) from Score b where b.s_score>=60 and a.c_id=b.c_id)/
(select count(b.s_score) from Score b where a.c_id=b.c_id)*100,'%') as 及格百分数
from Score a join Course c
on a.c_id=c.c_id
group by a.c_id,c_name
order by 平均成绩, 及格百分数 DESC;
20、查询如下课程平均成绩和及格率的百分数(用1行显示),其中企业管理为001,马克思为002,UML为003,数据库为004
题目的本质就是19题的基础上进行一次结果筛选
21、查询不同老师所教不同课程平均分从高到低显示
要点:联结
难度:4
select T.t_id, T.t_name, C.c_name, AVG(S.s_score) 平均成绩
from Teacher T
join Course C on T.t_id = C.t_id
join Score S on C.c_id = S.c_id
group by T.t_id, T.t_name, C.c_name
order by 平均成绩 desc;
22、查询如下课程成绩第3名到第6名的学生成绩单,其中企业管理为001,马克思为002,UML为003,数据库为004,以如下形式显示:
学生ID学生姓名企业管理马克思UML数据库平均成绩
select s_id,
(select s_score from Score where c_id = '01' and Student.s_id = Score.s_id) 语文,
(select s_score from Score where c_id = '02' and Student.s_id = Score.s_id) 数学,
(select s_score from Score where c_id = '03' and Student.s_id = Score.s_id) 英语,
(select avg.avg
from (select s_id, avg(s_score) avg
from Score
where c_id in ('01', '02', '03')
group by s_id) avg
where Student.s_id = avg.s_id) 平均分数
from Student;
23、使用分段[100-85],[85-70],[70-60],[<60]来统计各科成绩,分别统计各分数段人数:课程ID和课程名称
要点:case
难度:5
select S.c_id,
c_name,
sum(case when s_score >= 85 then 1 else 0 end) as '[100-85]',
sum(case when s_score >= 70 and s_score < 85 then 1 else 0 end) as '[85-70]',
sum(case when s_score >= 60 and s_score < 70 then 1 else 0 end) as '[70-60]',
sum(case when s_score < 60 then 1 else 0 end) as '[<60]'
from Course
join Score S on Course.c_id = S.c_id
group by S.c_id, c_name;
24、查询学生平均成绩及其名次
要点:算出在所有同学中有几个同学的平均分高于某个ID,然后+1,就是名次
难度:5
-- 解法1:直接使用自定义变量(有缺陷:如果存在同分数的情况这个是无法解决的)
SET @row_number = 0;
select (@row_number := @row_number +1) as 名次 ,avg.s_id 学号,avg.avg 平均成绩
from (select s_id,avg(s_score) avg
from Score
group by s_id order by avg desc) avg;
-- 这个解法是正确的,会有成绩排名一样的同学
select a.s_id as 学号,
a.平均成绩,
(select count(1) + 1
from (SELECT s_id, AVG(s_score) AS 平均成绩
FROM Score
GROUP BY s_id) AS b
where b.平均成绩 > a.平均成绩) as 名次
from (select s_id, avg(S_score) as 平均成绩 from Score group by s_id order by 平均成绩 desc) as a;
25、查询各科成绩前三名的记录(不考虑成绩并列情况)需要时常review
要点:超过当前ID的人最多2人
难度:5
SELECT c_id, s_id, s_score
FROM Score a
WHERE (SELECT COUNT(*) FROM Score b WHERE a.c_id = b.c_id AND a.s_score < b.s_score) <= 2
ORDER BY c_id ASC, s_score DESC
26、查询每门课程被选修的学生数
难度:2
select C.c_id, c_name, count(s_id)
from Score
join Course C on Score.c_id = C.c_id
group by c_id, c_name;
27、查询出只选修了两门课程的全部学生的学号和姓名
难度:3
-- 解法1:直接联表筛选
select S.s_id, s_name
from Score
join Student S on Score.s_id = S.s_id
group by S.s_id, s_name
having count(c_id) = 2;
-- 解法2:二次筛选
select s_id, s_name
from Student
where s_id in (select s_id from Score group by s_id having count(c_id) = 2);
28、查询男生、女生人数
难度:3
-- 解法1:直接查询
select (select count(*) from Student where s_sex = '男') as 男生人数,
(select count(*) from Student where s_sex = '女') as 女生人数;
-- 解法2:直接分组(更优一些)
select s_sex, count(*)
from Student
group by s_sex;
29、查询名字中含有“风”字的学生信息
难度:2
-- 模糊查询
select *
from Student
where s_name like '%风%';
-- 拓展知识
如果这里的s_name建立过索引,那么此处会出现索引失效的情况,原因 模糊查询的时候,如果存在%前缀会查询全表all不走索引
30、查询同名同姓学生名单并统计同名人数
难度:3
select s1.*
from Student s1
join Student s2 on s1.s_name = s2.s_name and s1.s_id <> s2.s_id;
-- 直接分组解决
select s_name, count(s_id)
from Student
group by s_name
having count(s_id) > 1;
31、1990年出生的学生名单(注:Student表中s_birth列的类型是datetime)
难度:3
-- 解法1:直接过滤通过
select *
from Student
where s_birth=1990;
-- 模糊搜索的解法
select s_name
from Student
where s_birth like '1990%';
-- format格式化的解法
select s_name
from Student
where year(s_birth)=1990;
-- 拓展:12月出生的同学
select s_name
from Student
where month(s_birth)=12;
-- 21日出生的同学
select s_name
from Student
where day(s_birth)=21;
32、查询平均成绩大于85的所有学生的学号、姓名和平均成绩
难度:3
select S.s_id, s_name, avg(s_score) as avg
from Student
join Score S on Student.s_id = S.s_id
group by S.s_id, s_name
having avg > 85;
33、查询每门课程的平均成绩,结果按平均成绩升序排序,平均成绩相同时,按课程号降序排列
难度:3
select c_id, avg(s_score) avg
from Score
group by c_id
order by avg asc, c_id desc;
34、查询课程名称为“数学”且分数低于60的学生姓名和分数
难度:3
-- 核心解决思路就是拆解然后组合
select Student.s_name, filer.s_score
from Student
join (select s_score, s_id
from Score
join Course C on Score.c_id = C.c_id
where c_name = '数学'
and s_score < 60) as filer on filer.s_id = Student.s_id;
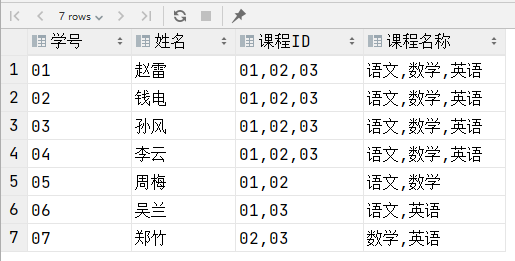
35、查询所有学生的选课情况
难度:3
-- 直接使用GROUP_CONCAT
select Student.s_id 学号, s_name 姓名, curseIdArray as 课程ID, curseArray as 课程名称
from Student
join (select s_id,
GROUP_CONCAT(c_name order by C.c_id) curseArray,
GROUP_CONCAT(C.c_id order by C.c_id) curseIdArray
from Score
join Course C on Score.c_id = C.c_id
group by s_id) array on array.s_id = Student.s_id;
-- 原始答案如下:其也解决了问题,但是感觉有点冗余
select a.s_id as 学号, s_name as 姓名, c.c_id as 课程号, c_name as 课程名称
from Student a
join Score b on a.s_id = b.s_id
join Course c on b.c_id = c.c_id
36、查询任何一门课程成绩在70分以上的姓名、课程名称和分数
难度:3
select s_name, c_name, s_score
from Score
join Course C on Score.c_id = C.c_id
join Student S on Score.s_id = S.s_id
where s_score > 70;
37、查询不及格的课程并按课程号从大到小排列
难度:3
select C.c_id, s_score
from Score
join Course C on Score.c_id = C.c_id
where s_score < 60
order by c_id desc;
38、查询课程编号为03且课程成绩在80分以上的学生的学号和姓名
难度:4
-- 直接联表
select S.s_id, s_name
from Score
join Course C on Score.c_id = C.c_id
join Student S on Score.s_id = S.s_id
where s_score >= 80
and C.c_id = '03';
-- 二次过滤
select s_id as 学号, s_name as 姓名
from Student
where s_id IN (SELECT s_id
FROM Score
WHERE c_id = '03'
and s_score > 80);
-- 拓展知识:联表与二次过滤谁的速度快?
多次过滤要优一些,具体原因如下:
- 让缓存的效率更高。因为联表查询需要全表进行处理
- 减少锁竞争
- 在应用层做关联,可以更容易对数据库进行拆分(分库、分表)
- 提升查询效率
- 减少冗余记录的查询
- 应用中实现了哈希关联,而不是使用mysql的嵌套环关联。某些场景下效率要高很多
39、查询选了课程的学生人数
难度:2
select count(s.s_id) 学生人数
from (select distinct s_id
from Score
group by s_id) as s;
-- 该种解法更优
select count(DISTINCT s_id) as 学生人数
from Score;
40、查询选修“张三”老师所授课程的学生中成绩最高的学生姓名及其成绩
难度:5
-- 解法比较复杂:但是这个应该是正确的,可以解决一个老师教多门科目的情况
select s1.c_id, s_name, s_score
from Student s0
join Score s1 on s0.s_id = s1.s_id,
(select s0.c_id,
max(s_score) as max
from Score s0
where c_id in (select c_id
from Course
where t_id in (select t_id
from Teacher
where t_name = '张三'))
group by s0.c_id) s2
where s1.c_id = s2.c_id
and s1.s_score = s2.max;
-- 原有解法有点问题:张三老师如果教2门课呢?
select s_name as 学生姓名, s_score as 成绩
from Student a
join Score b on a.s_id = b.s_id
join Course c on c.c_id = b.c_id
join Teacher d on d.t_id = c.t_id
where t_name = '张三'
order by s_score DESC
limit 1;
41、查询各个课程及相应的选修人数
难度:2
select C.c_id, c_name, count(s_score)
from Score
join Course C on Score.c_id = C.c_id
group by C.c_id;
42、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
难度:5
-- 单表自联查
select distinct a.s_id as 学生编号 ,a.c_id as 课程编号,a.s_score as 学生成绩
from Score a join Score b
on a.s_id=b.s_id and a.c_id<> b.c_id
where a.s_score=b.s_score;
43、查询每门课程成绩最好的前两名,同25题
难度:5
-- 最为核心的是过滤条件
select a.c_id 课程号, C.c_name 课程名称, s_name 姓名, a.s_score 成绩
from Score a
join Course C on a.c_id = C.c_id
join Student S on a.s_id = S.s_id
where (select count(*) from Score b where a.c_id = b.c_id and a.s_score < b.s_score) < 3
order by a.c_id;
44、统计每门课程的学生选修人数(超过5人的课程才统计)。要求输出课程号和选修人数,查询结果按人数降序排序,若人数相同,按课程号升序排序
要点:分组,排序
难度:3
select c_id 课程号, count(s_score) 选修人数
from Score
group by c_id
having 选修人数 > 5
order by 选修人数 desc, c_id;
45、查询至少选修两门课程的学生学号
难度:2
select s_id
from Score
group by s_id
having count(c_id) >= 2;
46、查询选修了全部课程的学生信息
难度:4
-- 相当于3次查询
select *
from Student
where s_id in (select s_id
from Score
group by s_id
having count(c_id) = (select count(*) from Course));
-- 该解法有问题:如果有一门课,没有任何人选修呢?score里面也没有它的信息,那不是GG?
select a.s_id, s_name, s_birth, s_sex
from Student a
join Score b on a.s_id = b.s_id
group by a.s_id
having count(b.c_id) = (select count(distinct c_id) from Score);
47、查询没学过“张三”老师讲授的任一门课程的学生姓名
要点:三表联结
难度:4
-- 直接进行筛选
select s_name
from Student
where s_id not in (select distinct S.s_id
from Teacher
join Course C on Teacher.t_id = C.t_id
join Score S on C.c_id = S.c_id
where t_name = '张三');
48、查询两门以上不及格课程的同学的学号及其平均成绩
要点:执行顺序
难度:4
-- 核心解决思路就是拆解
select S.s_id, avg(s_score)
from Student
join Score S on Student.s_id = S.s_id
where S.s_id in (select distinct s_id
from Score a
where (select count(*) from Score b where a.s_id = b.s_id and b.s_score < 60) >= 2)
group by S.s_id;
49、检索课程编号为“04”且分数小于60的学生学号,结果按按分数降序排列
难度:2
select s_id
from Score
where c_id = '04'
and s_score < 60
order by s_score desc;
50、删除学生编号为“02”的课程编号为“01”的成绩
难度:2
delete
from Score
where s_id = '02'
and c_id = '01';
4,LeetCode题目
LeetCode上面有将近200道数据库相关的题目
175. 组合两个表
select p.firstName,p.lastName,a.city,a.state
from Person p left join Address a on p.personId=a.personId;
176. 第二高的薪水
-- 解法1:直接查询
select (select DISTINCT Salary
from Employee
order by Salary desc limit 1 offset 1) as SecondHighestSalary;
-- 错误解法 该语句输出[],不是null
select DISTINCT Salary as SecondHighestSalary
from Employee
order by Salary desc limit 1 offset 1;
-- 解法2:使用IFNULL(a,b)函数
SELECT IFNULL(
(SELECT DISTINCT Salary
FROM Employee
ORDER BY Salary DESC
LIMIT 1 OFFSET 1),
NULL) AS SecondHighestSalary
177. 第N高的薪水
-- 解法1:直接去重获取第N高数据,注意里面的N数值改动
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
SET N:=N-1;
RETURN (
# Write your MySQL query statement below.
select (select DISTINCT Salary
from Employee a
ORDER BY Salary desc limit N,1)
);
END
-- 解法2:直接利用分组去重
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
SET N:=N-1;
RETURN (
# Write your MySQL query statement below.
select (select Salary
from Employee a
group BY Salary
order by Salary desc limit N,1)
);
END
-- 解法3:直接使用自表查询
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
select (select distinct Salary
from Employee a
where (select count(distinct Salary) from Employee b where b.Salary>a.Salary)=N-1)
);
END
-- 解法4:
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
SELECT
e1.salary
FROM
employee e1, employee e2
WHERE
e1.salary <= e2.salary
GROUP BY
e1.salary
HAVING
count(DISTINCT e2.salary) = N
);
END
-- 解法5:
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
SELECT
DISTINCT salary
FROM
(SELECT
salary, @r:=IF(@p=salary, @r, @r+1) AS rnk, @p:= salary
FROM
employee, (SELECT @r:=0, @p:=NULL)init
ORDER BY
salary DESC) tmp
WHERE rnk = N
);
END
-- 解法6:窗口函数
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
SELECT
DISTINCT salary
FROM
(SELECT
salary, dense_rank() over(ORDER BY salary DESC) AS rnk
FROM
employee) tmp
WHERE rnk = N
);
END
拓展知识:
实际上,在mysql8.0中有相关的内置函数,而且考虑了各种排名问题:
- row_number(): 同薪不同名,相当于行号,例如3000、2000、2000、1000排名后为1、2、3、4
- rank(): 同薪同名,有跳级,例如3000、2000、2000、1000排名后为1、2、2、4
- dense_rank(): 同薪同名,无跳级,例如3000、2000、2000、1000排名后为1、2、2、3
- ntile(): 分桶排名,即首先按桶的个数分出第一二三桶,然后各桶内从1排名,实际不是很常用
- 显然,本题是要用第三个函数。
- 另外这三个函数必须要要与其搭档over()配套使用,over()中的参数常见的有两个,分别是
partition by,按某字段切分
order by,与常规order by用法一致,也区分ASC(默认)和DESC,因为排名总得有个依据
178. 分数排名
-- 直接利用mysql自带的窗函数来解决
select score, dense_rank() over(order by score desc) as 'rank'
from Scores
order by score desc;
180. 连续出现的数字
todo 需要额外学习
-- 解法1:利用mysql的 lag,lead函数
select distinct num as ConsecutiveNums
from (select num,
lag(num, 1, null) over (order by id) lag_num,
lead(num, 1, null) over (order by id) lead_num
from logs) l
where l.Num = l.lag_num
and l.Num = l.lead_num
-- 解法2:
-- 外部排重(如果是要记连续次数的情况,就进行套一层Group By Num)
SELECT DISTINCT Num "ConsecutiveNums"
FROM (
SELECT Num,
/*
* 连续出现的数特点为:[行号] - [组内行号] = k
*/
(row_number() OVER (ORDER BY id ASC) -
row_number() OVER (PARTITION BY Num ORDER BY id ASC)) AS series_id
FROM Logs
) tab
-- 根据每个连续情况进行分组,e.g. 开头的1 1 1连续会被记为{数值Num:1, 行号与组内行号差值:0}组
GROUP BY Num, series_id
HAVING COUNT(1) >= 3 -- 连续重复次数
181. 超过经理收入的员工
-- 解法1:直接使用内连接
select a.name as 'Employee'
from Employee a
join Employee b on a.managerId = b.id
where a.salary >b.salary;
-- 解法2:自筛选
select a.name as 'Employee'
from Employee a
where (select count(*) from Employee b where a.managerId = b.id and a.salary >b.salary)>0;
182. 查找重复的电子邮箱
-- 解法1:自己利用分组即可
select Email
from Person
group by Email having count(Id)>1;
-- 解法2:自筛选
select distinct Email
from Person a
where (select count(*) from Person b where a.id<>b.id and a.Email=b.Email)>0;
183. 从不订购的客户
-- 解法1:直接筛选
select name as 'Customers'
from Customers
where id not in (select CustomerId from Orders );
184. 部门工资最高的员工
-- 先分组查询每个部门的最大薪水信息,然后联表获取其他信息
select b.name as 'Department',a.name as 'Employee',c.maxSalary as 'Salary'
FROM Employee a
JOIN Department b ON a.departmentId = b.id
JOIN (select departmentId ,max(salary) maxSalary
from Employee
group by departmentId) c on c.departmentId=b.id and c.maxSalary=a.Salary;
185. 部门工资前三高的所有员工
select c.name as Department,d.name as Employee,d.Salary
from Department c
join (select *
from Employee a
where (select count(distinct b.salary) from Employee b where a.departmentId =b.departmentId and a.salary<b.salary)<3) d
on c.id=d.departmentId;
196. 删除重复的电子邮箱
-- 直接利用分组,查询最小id,然后删除所有不是最小id就可以了
DELETE from Person a
where a.id not in (
SELECT c.id from (SELECT min(id) as id
from Person b
group by b.email) c
);
-- 官方解法
DELETE p1 FROM Person p1,
Person p2
WHERE
p1.Email = p2.Email AND p1.Id > p2.Id
拓展:
官方的写法相当不好,自己联自己,产生笛卡尔积结果,然后直接筛选临时结果看起来很好很方便 但是如果条件区分度不够,数据又不少,直接会组合出相当大的临时表 (650条记录,6种种类做类似Email的条件区分,一下子查出1W5的临时数据, 而实际使用中很容易就是万为单位的数据量,直接会爆炸的!)
from-fogcoding
197. 上升的温度
-- 有疑问 为什么 day(a.recordDate)-day(b.recordDate)=1不行?
select a.id
from Weather a
join Weather b on DATEDIFF(a.recordDate, b.recordDate) = 1 and a.Temperature >b.Temperature ;
4,拓展语句
4.1,递归查询
postgres数据库的递归查询与此基本一致
-- 数据准备
drop table department;
CREATE TABLE department
(
id bigint,
name VARCHAR(20) NOT NULL DEFAULT '',
pid bigint,
PRIMARY KEY (id)
) engine = innodb;
INSERT INTO `20220419practice`.department (id, name, pid)
VALUES (1, '开发部', 0),
(1001, '产品组', 1),
(1001001, '产品1组', 1001),
(1001002, '产品1组', 1001),
(1001003, '产品1组', 1001),
(1002, '前端组', 1),
(1002001, '前端1组', 1002),
(1002002, '前端2组', 1002),
(1002003, '前端3组', 1002),
(1003, '后端组', 1),
(1003001, '后端1组', 1003),
(1003002, '后端2组', 1003),
(1003003, '后端3组', 1003),
(1004, '测试组', 1),
(1004001, '测试1组', 1004),
(1004002, '测试2组', 1004),
(1004003, '测试3组', 1004),
(2, '营销部', 0),
(2001, '大中华区', 2),
(2002, '东南亚区', 2),
(3, '人力资源部', 0),
(3001, '财务', 3),
(3002, '招聘', 3),
(3003, '培训', 3);
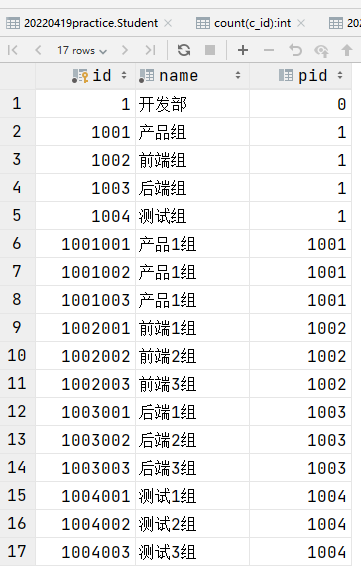
-- 向下递归查询
WITH recursive temp AS(
SELECT * FROM department WHERE id=1
UNION ALL
SELECT u.* FROM department u,temp t WHERE u.pid=t.id
)
SELECT * FROM temp;
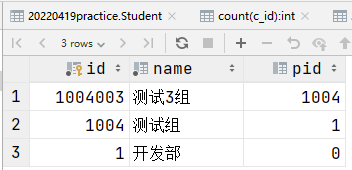
-- 向上递归查询
WITH recursive temp AS(
SELECT * FROM department WHERE id=1004003
UNION ALL
SELECT u.* FROM department u,temp t WHERE u.id=t.pid
)
SELECT * FROM temp;
向下递归查询结果
向上递归查询结果
4.2,自定义函数
样例:177. 第N高的薪水
模板:
CREATE FUNCTION yourFunctionName(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
);
END
测试样例:
set global log_bin_trust_function_creators=TRUE;
CREATE FUNCTION doubleNum(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
select (N+N)
);
END;
SELECT doubleNum(5);
拓展:
之前,自己测试的时候没有设置 set global log_bin_trust_function_creators=TRUE;导致一直报错:
[HY000][1418]
This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)
其中的原因是:mysql的设置默认是不允许创建函数
解决方法:
- 直接执行命令
SET GLOBAL log_bin_trust_function_creators = 1; 但是mysql重启后就会失效 - 在 my.cnf 里添加
log-bin-trust-function-creators=1,然后重启 mysql
4.3,lag、lead函数
样例:180. 连续出现的数字
这边展示一下功能
select *, lag(id, 1, null) over (order by id) as "lag", lead(id, 1, null) over (order by id) as 'lead'
from department
where id < 10000;
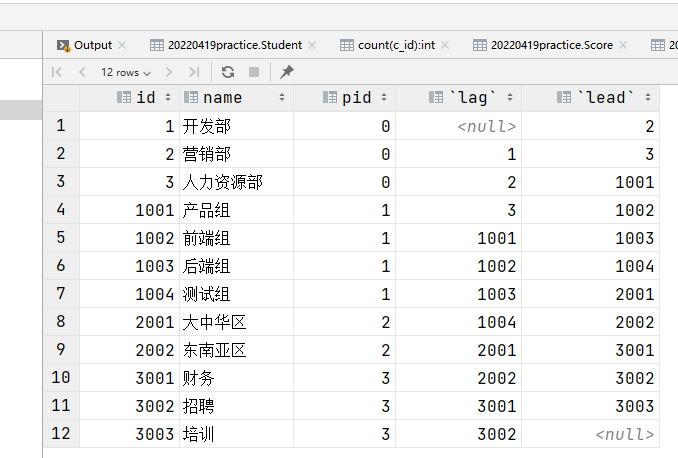
解析:相当于在结果集中,使用id字段进行前后移位的操作!
4.4,排序函数
排序函数命令
- row_number(): 同薪不同名,相当于行号,例如3000、2000、2000、1000排名后为1、2、3、4
- rank(): 同薪同名,有跳级,例如3000、2000、2000、1000排名后为1、2、2、4
- dense_rank(): 同薪同名,无跳级,例如3000、2000、2000、1000排名后为1、2、2、3
- ntile(): 分桶排名,即首先按桶的个数分出第一二三桶,然后各桶内从1排名,实际不是很常用