成员
练斐弘 031502518
叶己峰 031502537
Github
问题描述
作业需求
编码实现一个部门与学生的智能匹配的程序。
提供输入包括:
- 20个部门
- 部门编号(唯一确定值),字符;
- 各部门需要学生数的要求的上限,单个,数值,在[10,15]内;
- 各部门的特点标签,多个(两个以上),字符;
- 各部门的常规活动时间段,多个(两个以上),字符。
- 300个学生
- 学生编号(唯一确定值),字符;
- 学生空闲时间段,多个(两个以上),字符;
- 兴趣标签,多个(两个以上),字符(学生的兴趣标签一定是所有部门特点标签其中的一个)
- 每个学生有不多于5个的部门意愿(助教测试时测试数据中部门意愿可能会出现空缺,非空缺的部分一定是部门编号中的一个,并按照优先级从高到底的顺序排序)。
实现一个智能自动分配算法,根据输入信息,输出部门和学生间的匹配信息(一个学生可以确认多个他所申请的部门,一个部门可以分配少于等于其要求的学生数的学生) 及 未被分配到学生的部门 和 未被部门选中的学生。
数据生成
最好的一组数据
过程
在编码开始前,我们原计划所有数据均采用随机生成,如学生学号、部门编号、空闲时间单,通过string数组记下,取出符合条件的使用。然而在生成编号和时间段的时候,我们发现了两个问题:
1、大量数据不符合要求
2、无用的耗时占比大(需要判断是否丢弃重复数据)
参考了网上的一些资料后,再结合我们的实际情况,最后决定采用枚举法 + 随机数rand() + bool数组 生成
考虑因素
- 数据具有随机性
- 数据具有时效性,如部门志愿不能出现无的情况
- 数据具有不重复性,如一个人填的时间段不能有多个相同的
枚举数据
string all_tags[10] = {"reading","programming","film","English","music","dance","basketball","chess","running","swimming"};
string freeweek[7] = {"Mon.","Tues.","Wed.","Thurs.","Fri.","Sat.","Sun."};
string freetimes[8] = {"08:00~10:00","9:00~11:00","10:00~12:00","14:00~16~00","15:00~17:00","18:00~20:00","19:00~21:00","20:00~22:00"};
string all_department_no[20] = {"D001","D002", "D003", "D004", "D005","D006","D007","D008", "D009", "D010","D011","D012","D013","D014","D015","D016", "D017", "D018","D019","D020" };
使用如下条件生成数据
学生方面:
- 编号:参考福大数计学院计算机系学生号码,格式为031502XXX
- 空闲时间:两个小时为一个时间块划分,避免午休和饭点,化为8:0010:00,9:0011:00,14:001600,15:0017:00,18:0020:00,19:0021:00,20:0022:00共7个时间段,按时间块随机取2~7个
- 部门选择意愿:从部门编号中随机选取5个以内,部门编号按题设要求为"D001,D002,D003...."
- 兴趣标签:参考部门特色,选取了英语、编程、阅读、音乐等兴趣
部门方面:
- 部门编号:按题设要求为"D001,D002,D003...."
- 活动时间段:同样以两个小时为一个时间块划分,避免午休和饭点,化为8:0010:00,9:0011:00,14:001600,15:0017:00,18:0020:00,19:0021:00,20:0022:00共7个时间段
- 特色标签:从标签池中选若干个,参考部门特色
- 人数上限:参考部门实际需求,院级学生部门的人数区间在[10,15]范围中
数据建模及匹配程序的思路及实现方式
1、程序模型
主要由三部分组成:生成数据程序、匹配算法程序、json格式输入输出程序
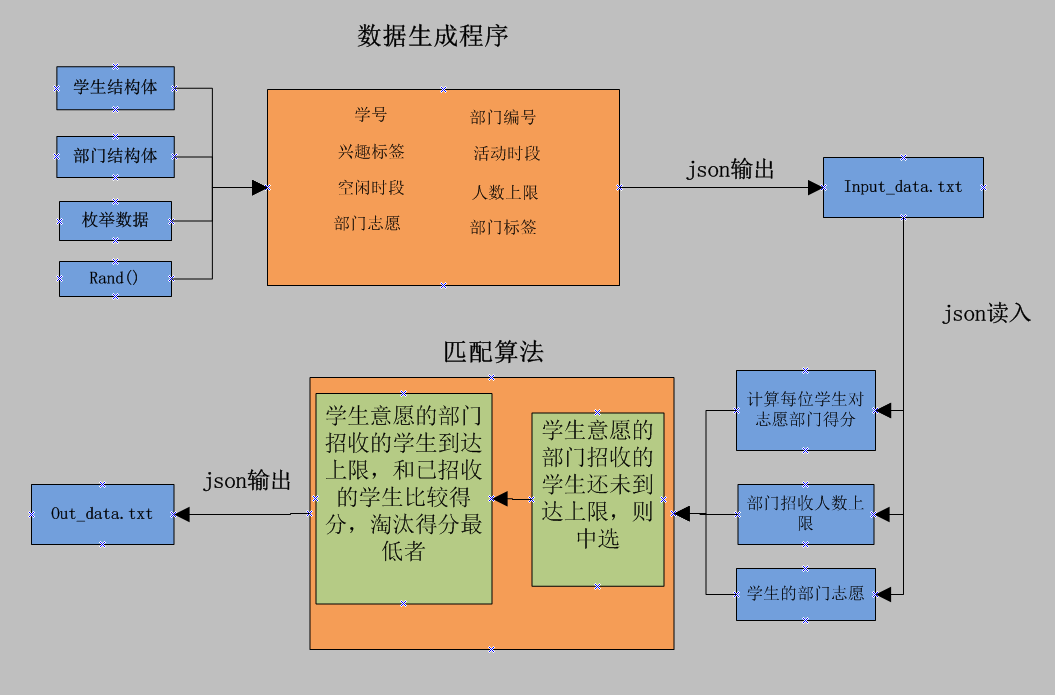
2、数据模型
- 学生模型:
- 1)学号:按顺序生成
- 2)空闲时段:从枚举的日期和时间段中组合,用bool数组标记
- 3)空闲时段个数
- 4)兴趣标签:从枚举的兴趣标签中挑选,用bool数组标记
- 5)兴趣标签个数
- 6)部门意愿:从枚举的部门意愿中挑选,用string数组记录
- 7)部门意愿个数
- 8)加入的部门个数
- 9)在所意愿的部门中综合得分:计算方法在后面匹配算法中提到
- 部门模型:
- 1)部门编号:按顺序生成
- 2)招收学生数的上限
- 3)兴趣标签:从枚举的兴趣标签中挑选,用bool数组标记
- 4)兴趣标签个数
- 5)空闲时段:从枚举的日期和时间段中组合,用bool数组标记
- 6)空闲时段个数
3、匹配程序的思路
-
- 先列出当初我们讨论的头脑风暴(注:由于我们算法能力不足,并没有完全解决所提出的问题)
- a) 基于学生在每个意愿部门上的得分来进行分配,显然更加简洁明了
- b) 计算学生对每个部门的相应得分要考虑: 这个部门在学生部门意愿优先度、 部门活动时间和学生空闲时间的重合度、部门标签和学生兴趣标签重合度、 当前学生已加入的部门个数(加入个数越多得分越低);
- c) 当学生因为得分最低而被淘汰时,其得分全都要重新计算;
- d) 当学生的一个空闲时间段和两个意愿部门的活动时间重叠时,则该时间段计算到意愿优先度高的部门;
- e) 当学生的部门意愿为空或者学生一个部门意愿都没中选,考虑把学生分配给部门意愿外的部门;
- f) 当学生的空闲时段和部门活动时段没有一个重合时,该学生的得分应该置0。
-
- 计算得分的规则:
-
部门意愿优先度得分:第一意愿部门得50分,第二意愿部门得30分,第三、四、五意愿部门得10,7,3分。站在学生角度上,第一个意愿部门应该在得分中占较大比重。
-
时间重叠度得分:用1小时来考虑,重叠1小时得40分,2小时得50分,3小时以上得55分,如果一次都没有分数置为0。学生必须得有时间来参加部门活动,所以时间重合度也应占较大比重,但同时学生也不要把太多时间用于部门,所以当时间重合超过3小时以上得分不变。
-
标签重合度得分:重合一个标签相符得10分,标签越多,就越和部门志趣相投,所以成正比;
-
- 实现方法:
该匹配算法目的为得到一个让学生和部门都尽量满意的分配方案。
首先从学生的第一意愿部门出发,如果该部门招收学生人数未到上限,那么就中选;如果招收学生人数已达上限,那就得分和已招收的学生中最低得分比较,高于最低得分就取代最低得分的那个同学,低于最低得分那该第一意愿就废弃。
同理,再从第二意愿出发... ...
使用这种方式可以确保部门招收的同学都是排名前列的,同时同学的每个意愿都经过考虑不会有遗漏。
- 实现方法:
-
4)结果分析:
大体上看,其结果还是满足预期的。但是就是未得到分配的学生有点多,这是因为我们算法是根据学生的部门意愿来进行分配的,一旦300个人都选择热门部门,就一定会有大量的人落选,要想解决这个问题就需要改进算法,实现想法 e)考虑把学生分配给部门意愿外的部门。希望后面能有时间把想法都实现了。
有学生申请的部门的申请列表中,将学生先按时间符合排序,再按标签符合排序,取所有可取的,且少于部员数量限制的学生,加入 matched 数组,否则再将申请列表剩下的学生按时间符合排序,取所有可取的,且少于部员数量限制的学生,加入 matched 数组。
代码规范
本次结对作业用github进行代码管理,两人统一使用叶己峰的账号进行提交。
主要遵循以下几个规范
- 对变量名命名使用驼峰式(json数据的用下划线衔接单词),且变量名有意义,不乱取
- if、for、do、while、case、switch、default等语句自占一行
- 程序块采用缩进风格编写,缩进的空格数为4个
//部门结构体
struct Department
{
string department_no; //部门编号(唯一确定值),字符
int member_limit; //各部门需要学生数的要求的上限,单个,数值,在[10,15]内;
int tags_num; //部门的特点标签个数
int tags[10]; //各部门的特点标签,多个(两个以上),字符;
int event_schedules_num; //各部门的常规活动时间段个数
int event_schedules[7][8]; //各部门的常规活动时间段,多个(两个以上),字符。
};
//常规活动时间段
dep[i].event_schedules_num = unsigned(rand()%6) + 2;
for(int j = 0; j < dep[i].event_schedules_num; j++)
{
int t1 = unsigned(rand()%7);
int t2 = unsigned(rand()%8);
if(dep[i].event_schedules[t1][t2]==1)
j--;
else
dep[i].event_schedules[t1][t2] = 1;
}
结对感受
刚看到题目的时候,我意识到了这次作业的工作量远远大于前几次软工实践作业,然而完成效果却会比前几次的差很多,原因主要是国庆放假回家的缘故了,由于家里学习条件较差,主要工作都是在假期前和回到学校后完成的。我们在放假回家前先大致讨论过了思路和方案,两人的分工大致是,练斐弘负责json数据的读入和输出,叶己峰负责匹配算法,剩下的细节由两人共同讨论完成。我本以为关于json数据这部分会较轻松些,因为之前玩过前端,用javascript来处理json数据听方便的。没想到却碰上了大麻烦,在读入的问题上,卡了有两天时间,最初采用cjson来读取数据,可是编译器频频报错cjson的函数undefined,检查了几遍头文件的引入,都没找到问题,又上网找了资料,仍然无法解决,无奈弃坑,转用比较多人使用的jsoncpp,相对于cjson来说,jsoncpp函数的调用更简洁明了一些,然而在jsoncpp的配置中,还是碰到了一些坑,幸运的是,在网上找到了一份教程,也算是找到了个小捷径。这里,也要向队友表达谢意和歉意,叶己峰同学做事严谨认真,本来可以早些提交代码的,他还审核过了多次,debug了挺久,才得到我们最后更好的作品,而相比之下,我感觉我要学习和努力的还有更多。
本次结对作业虽然感觉完成情况不好,但是还是有些收获,主要如下几点
- 看到报错信息,不要马上复制黏贴问百度,先翻译!自己解决!网上很多论坛的答案也不是正确的,盲目照改会出现很大问题
- 编码规范还是很重要的,在没注释的情况下,看懂队友的代码是一件非常痛苦的事情,先树立规范,再编写代码,磨刀不误砍柴工。
- 不同语言对于同样数据的处理是有很大区别的!比如json数据,不能盲目用老方法处理,否则会吃大亏。