一. 查询缓存
1.开启缓存
[root@xuegod64 etc]# vim my.cnf
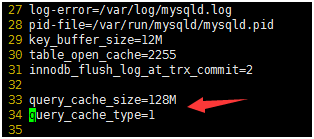
设置了缓存开启,缓存最大限制128M,重启服务后,再次查询
-- 开启查询缓存后 SHOW VARIABLES LIKE '%query_cache%';
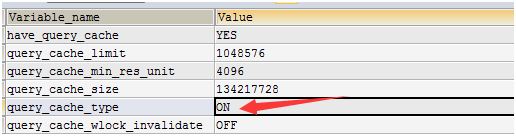
2 测试缓存
现在是缓存2次,命中一次

SELECT ID FROM User1 WHERE ID=2 SELECT Age FROM User1 WHERE ID=2
上面是二个查询sql语句,此时缓存数是4,如下图所示:

--再次查询上面相同的sql语句,此时命中率结果为3,缓存数还是4 SELECT ID FROM User1 WHERE ID=2 SELECT Age FROM User1 WHERE ID=2

--查询相同的sql语句,条件值大小写不一样 SELECT ID FROM User1 WHERE `Name`='Abc' SELECT ID FROM User1 WHERE `Name`='aBc'
此时缓存数是6,说明缓存区分where条件值的大小写。同样也会区分sql关键词的大小写。如下图所示:

设置好query_cache_size值后,重新启动服务初始化时:query_cache_size==Qcache_free_memory的值。
缓存的命中率公式为: Qcache_hits/(Qcache_hits+Qcache_inserts)。
总结:根据MySQL用户手册,使用查询缓冲最多可以达到238%的效率。但开起缓存,前提条件是你有大量的相同或相似的查询,而很少改变表里的数据,否则没有必要使用此功能。