机器学习实战一《序言》
(个人观点,仅供参考。)
一 人工智能,深度学习与机器学习:
时下人工智能(Artificial Intelligence)、机器学习(Machine Learning)、深度学习(Deep learning)的浪潮席卷全球,但是对于其到底意味着什么以及其背后的关系似乎总是似懂非懂。
早在1956年的达特茅斯会议上(聚集了一波伟大的计算机领域的牛人),几个计算机的科学家就提出了‘人工智能的概念’(科学们的聚会总是brain store,菜鸡们往往是王者荣耀)。
定义和概念:.
1、机器学习(ML): 机器学习的最基本的做法使用算法来解析数据、从中学习,然后对真实的世界中的事件作出决策和预测,机器学习往往需要使用大量的数据来进行“”训练“”,通过各种算法从数据中学习完成任务。
例:当我们在浏览淘宝时,经常出现商品推荐的信息,这些信息往往是通过你往期的浏览记录和冗长的收藏清单来识别你所感兴趣的,从而淘宝通过为客户建议并鼓励产品消费。
常见的机器学习的算法包括:决策树、聚类、贝叶斯分类、支持向量积等。
从学习的方法上来分,机器学习可以分为:有监督学习,无监督学习,半监督学习、集成学习、深度学习和强化学习。
2、深度学习(DL):在我的理解来深度学习更像是来实现机器学习的技术。深度学习本身往往需要使用到有监督和无监督学习的方法来训练深度的神经网络。但由于最近一些特有的学习手段想继续被提出(如残差网络)。所以才逐渐成为一门新的学科。
例:无人驾驶、预防性医疗保健等。
3、人工智能(AI): 是指由人工制造出来的系统所表现出来的智能。通常人工智能是指通过普通电脑实现智能。人工智能的研究可以分为许多分支,包括:专家系统、机器学习、进化计算、模糊逻辑、计算机视觉、自然语言处理、推荐系统等等。
关系.
机器学习是实现人工智能的一种方法。机器学习的概念来自早期的人工智能研究者,已经研究出的算法包括决策树学习、归纳逻辑编程、增强学习和贝叶斯网络等。简单来说,机器学习就是使用算法分析数据,从中学习并做出推断或预测。与传统的使用特定指令集手写软件不同,我们使用大量数据和算法来“训练”机器,由此带来机器学习如何完成任务。
深度学习是实现机器学习的一种技术。早期机器学习研究者中还开发了一种叫人工神经网络的算法,但是发明之后数十年都默默无闻。神经网络是受人类大脑的启发而来的:神经元之间的相互连接关系。但是,人类大脑中的神经元可以与特定范围内的任意神经元连接,而人工神经网络中数据传播要经历不同的层,传播方向也不同。
关键术语:
在真正的接触算法之前,最好还是要充的理解一下术语,主要通过一个鸟类分类系统,这个有趣的系统通常被与专家系统相联系,次系统通过创建一个电脑程序来识别鸟类,下表是相关的信息:
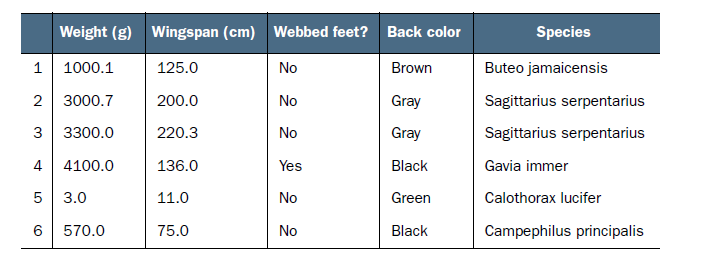
机器学习的一个任务就是分类,我们首先要做的就是训练算法,为此我们需要大量高效的数据作为训练集,训练集是一组带有特征和标签的数据集合,类似于上表中的数据。机器学习通过计算出上述特征属性和标签之间的关系来达到机器学习的目的。为了测试机器学习算法的准确性,我们还学要测试集,测试集的标签数据不提供给程序,算法根据算法自己推导出标签后,与标签进行验证从而验证算法的准确性。
有监督学习(Supervised Learning):通过含有标签的数据集进行学习
无监督学习(Unsupervised Learning):反之
(待补充)
K-Nearest Neighbor:
Navie Bayes:
Support vetor machine:
Decision trees:
Linear:
locally weighted linear:
Ridge:
Lasso:
K-Means:
DBSCAN:
Exoectation maximization:
Parzen window:
选择正确的算法
<> 我们需要根据我们的目标来选择正确的算法 <>
如果我们希望能够预测一个目标值,往往需要选择有监督学习,(反之则选用无监督学习。)如果目标值是离线数据,如:Yes/No、A/B/C等,我们往往选择分类算法,但如果目标变量是连续型的数值,如1~100,则采用的是回归算法。
当我们在使用无监督学习时,如果仅仅需要将数据划分为离散组,那我们则可以采用聚类算范,如果还需要进一步的估计数据与每个分组的相似度,则将会用到密度估计算法。
没有最好的算法,只有最合适的算法。
机器学习的应用步骤
1.收集数据: 可以选择爬虫或者直接调用API接口,数据的选择是无限的,但是为了节省精力,可以使用一些容易获取的公共数据。
2.准备输入数据: 得到数据之后,还应该确保数据的格式是否符合要求。
3.分析输入数据: 人工进行数据分析,检查数据是否存在空值,或者异常值。
4.训练算法: 机器学习的的核心部分,在这一过程中我们将数据输入到算法中,从中抽取只是和信心,这里得到的只是需要存储为计算机的可以处理的格式,方便后续步骤的使用。
5.测试算法: 评估算法的效果。
6.使用算法: 将算法转化为应用程序。
(机器学习菜鸟,望指教。)