案例1:K-近邻算法预测Facebook签到位置
数据介绍
row_id:登记事件的ID
xy:坐标
准确性:定位准确性
时间:时间戳
place_id:业务的ID,预测目标
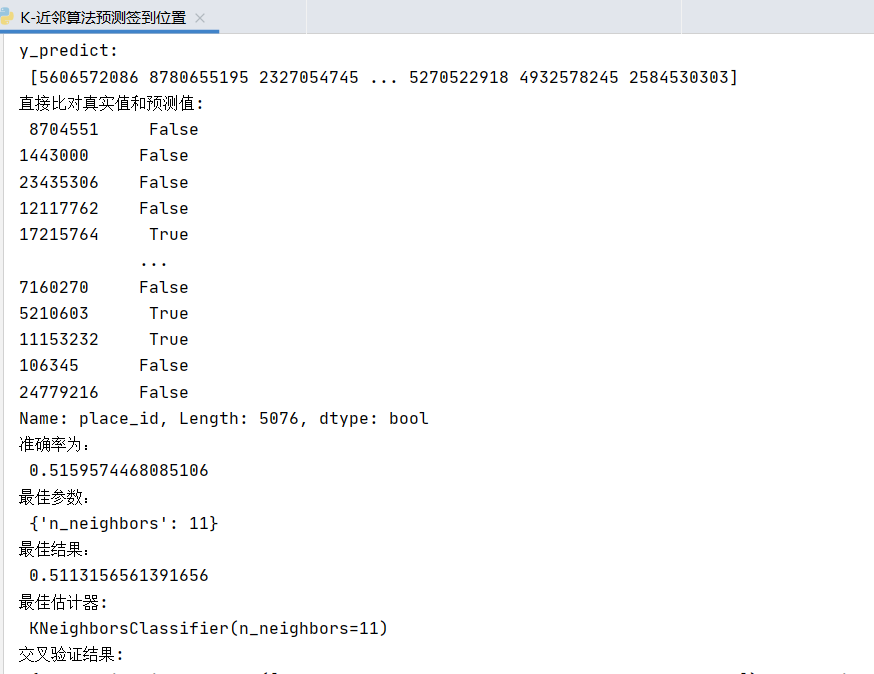
代码
from sklearn.model_selection import train_test_split,GridSearchCV from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier import pandas as pd def knncls(): """ K近邻算法预测入住位置类别 :return: """ # 一、处理数据以及特征工程 # 1、读取收,缩小数据的范围 data = pd.read_csv("../dataset/train.csv") # 数据逻辑筛选操作 df.query() data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75") # 删除time这一列特征 data = data.drop(['time'], axis=1) print(data) # 删除入住次数少于三次位置 place_count = data.groupby('place_id').count() tf = place_count[place_count.row_id > 3].reset_index() data = data[data['place_id'].isin(tf.place_id)] # 3、取出特征值和目标值 y = data['place_id'] # y = data[['place_id']] x = data.drop(['place_id', 'row_id'], axis=1) # 4、数据分割与特征工程 # (1)、数据分割 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3) # (2)、标准化 std = StandardScaler() # 训练集进行标准化操作 x_train = std.fit_transform(x_train) # 进行测试集的标准化操作 x_test = std.transform(x_test) # 4)KNN算法预估器 estimator = KNeighborsClassifier() # 加入网格搜索与交叉验证 # 参数准备 param_dict = {"n_neighbors": [3, 5, 9, 11]} estimator = GridSearchCV(estimator, param_grid=param_dict, cv=2) estimator.fit(x_train, y_train) # 5)模型评估 # 方法1:直接比对真实值和预测值 y_predict = estimator.predict(x_test) print("y_predict: ", y_predict) print("直接比对真实值和预测值: ", y_test == y_predict) # 方法2:计算准确率 score = estimator.score(x_test, y_test) print("准确率为: ", score) # 最佳参数:best_params_ print("最佳参数: ", estimator.best_params_) # 最佳结果:best_score_ print("最佳结果: ", estimator.best_score_) # 最佳估计器:best_estimator_ print("最佳估计器: ", estimator.best_estimator_) # 交叉验证结果:cv_results_ print("交叉验证结果: ", estimator.cv_results_) return None if __name__ == '__main__': knncls()