Python学习笔记13:异常处理
在编程语言的学习中,异常处理往往是不起眼,但又没法舍弃的部分。
事实上,当时的C++老师说过:异常的诞生是为了增强程序的健壮性,能让程序在出错的时候自动恢复。但很遗憾的是,这种局面从未实现。
所以,不要奢望你学完异常就有一种强大的工具,能大幅度提升代码的健壮性。我更倾向于这是一个讲代码中的错误能集中起来展示和处理,并和正常的业务逻辑区分开的有用的工具,仅此而已。
异常非但没能完成让程序忽视错误正常运行的初衷,反而在某些情况下可能会屏蔽掉一些严重问题,给调试带来麻烦,所以我们使用的时候要谨慎,你需要明白你使用异常的必要性,以及后续如何处理异常。
基本语法
我们先来看下Python中异常的基本语法:
def throwExp():
raise Exception()
try:
throwExp()
except:
print("catch a exception")
如演示的那样,在函数throwExp中可以通过raise语句抛出一个异常。然后在外部使用try/except语句来捕获异常。
不要问我为啥这里不是
throw和catch,我也很纳闷为何python的创造者如此不走寻常路。
在示例中except:将捕获所有类型的异常,如果你需要捕获特定类型的异常,可以这样:
try:
a = 2/0
except ZeroDivisionError:
print("catch a zero division exception")
输出
catch a zero division exception
这里指定了一个除零异常并正常捕获。
当然,我们也可以进一步获取到异常并输出异常的信息:
try:
a = 2/0
except ZeroDivisionError as e:
print("catch a zero division exception")
print(e)
输出
catch a zero division exception
division by zero
可以看到,这里用as语句将捕获的异常赋予变量e,然后就可以针对异常进行进一步处理。
如果我们想获取任意类型的异常,并做进一步处理,可以这样:
try:
a = 2/0
except Exception as e:
print("catch a zero division exception")
print(e)
仅仅需要把异常类型指明为Exception即可,因为这是所有异常类型的基类。
Python内置了数量众多的异常,关于Python异常的继承树可以看这里。
除了以上这些类似其它语言的常规操作,Python还提供内部函数exc_info对输出函数信息提供支持。
from sys import exc_info
try:
a = 2/0
except Exception:
print("catch a zero division exception")
print(exc_info())
输出
catch a zero division exception
(<class 'ZeroDivisionError'>, ZeroDivisionError('division by zero'), <traceback object at 0x0000024172AFDA00>)
可以看出exc_info会返回一个存放当前异常信息的元组,其中包含三个内容:
- 异常类型
- 异常信息
- 异常跟踪链
实际使用
现在我们可以用异常来继续改进我们的web应用。
我们现在的web应用在功能上基本没啥大毛病,但健壮性就不那么乐观了。
在创建一个应用的时候,无论是web应用,还是移动app,或者浏览器内的小应用,都会面临数据存储访问的问题。而数据访问牵扯到很多问题,比如资源存不存在?有没有访问权限?资源是不是被别的应用占用等等。
而每当没有正常获取到资源的时候,你的程序唯一能做的就是crack,而这也正是异常诞生的原因。
虽然就像我之前说到的,即使我们花力气编写额外的异常处理程序,我们也很难在缺乏关键资源的情况下让程序正常的运行,毕竟我们只是程序员,不是上帝。但是我们可以让程序体面地crack。
我们来看下面地例子:
现在我们假设数据库不可用,失联了或者别地什么。如果你和我一样使用的是XAMPP的话这很容易,对控制面板中的MySQL服务点一下stop即可。
现在我们访问一下我们的web应用:
幸运的是首页OK,因为它并不依赖于数据库。
我们点击Do it!
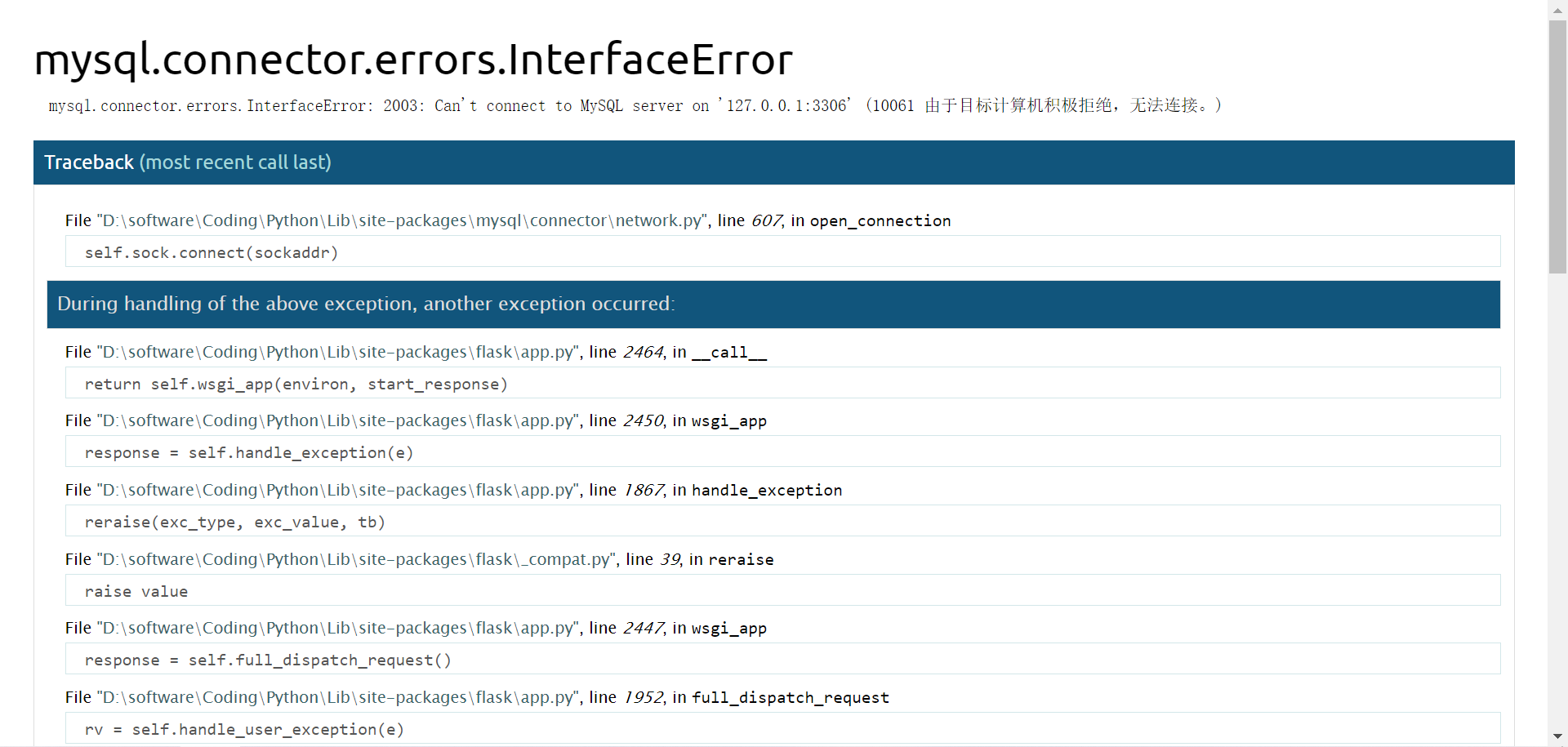
程序crack!
可以看到这是一个MySQL驱动报告的异常,异常类型为InterfaceError。
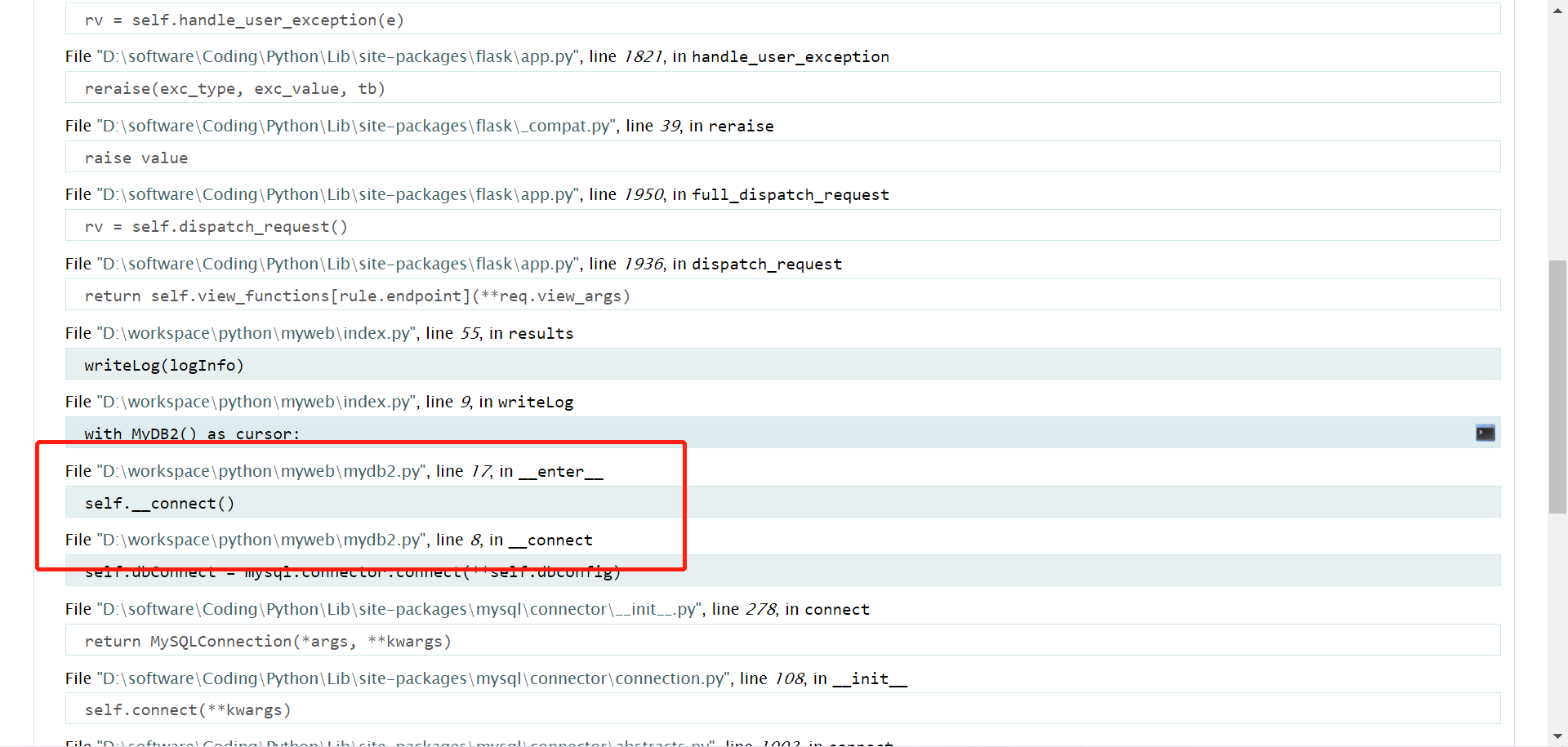
根据页面显示的异常跟踪,我们可以定位到是我们自定义的数据库模块mydb2.py产生的异常,我们需要在这里处理这个异常。
面对异常,我们通常有两种做法:
- 在当前代码处理。
- 将异常原样抛出给外层代码,在外层代码中处理。
乍一看这里抛出给外层程序来处理也没什么大不了的,但是这增加了程序的耦合度。
我们之前说过,之所以封装一个数据库访问层,一是为了代码复用,二是为了降低业务代码与数据库实体的耦合。如果我们将来某一天需要迁移数据库,从MySQL迁移去其它数据库,你当然不希望在所有业务代码中排查一遍对MySQL驱动的特殊调用,而是希望在一个数据库链接层中搞定。
而这里,将一个特定的MySQL驱动自定义异常抛给外部业务代码去处理,显然是增加耦合的做法。当然,你完全可以在外部使用异常基类Exception去接受和处理异常,但那样会减少接受到的异常信息,可能无法实现一些诸如出错重连等复杂的异常处理。
而我更喜欢和常用的做法是定义一个自定义异常,来集中封装和处理应用中的所有异常。
class UserException(Exception):
ERROR_DB_CONNECT = 1
ERROR_DB_OTHER = 2
def __init__(self, code, message=''):
super()
self.__code = code
self.__message = message
def getErrorCode(self):
return self.__code
def getErrorMessage(self):
return self.__message
现在我们在数据库访问层用我们的自定义异常来代替底层驱动异常并抛出:
def __connect(self):
try:
self.dbConnect = mysql.connector.connect(**self.dbconfig)
self.cursor = self.dbConnect.cursor()
except mysql.connector.errors.InterfaceError:
raise UserException(UserException.ERROR_DB_CONNECT,'数据库失连')
except Exception:
raise UserException(UserException.ERROR_DB_OTHER,'数据库未知错误')
我们还要在最外层捕获并处理这个异常:
try:
writeLog(logInfo)
except UserException as e:
with open(file='error.log',mode='a',encoding='UTF-8') as errorLogOpen:
print(e.getErrorCode(),':',e.getErrorMessage(),file=errorLogOpen)
return redirect('/showError/系统出错,请联系管理员/3')
这里我们写入一个错误日志来记录异常信息,并跳转到一个错误显示页面,让用户看到简单的出错信息。
这里只是简单记录了异常编码和消息,通常还应该加入时间和异常追踪链。
这就是所谓的体面地crack。
现在我们再来试一下之前地步骤:

系统并不会直接显示异常并crack了。
但是现在我们只处理了数据库链接部分可能的异常,要知道SQL查询的时候也是可能会发生异常,比如字段不存在,表不存在等等。
而如之前我们所说,为了降低耦合,我们应该尽量避免在外层业务代码中直接捕获底层的数据库驱动异常,那我们应该如何去做?
其实很简单,还记得我们的数据库访问层已经是一个上下文协议了吗,而上下文协议本身已经包含了对包裹其中的业务代码的异常捕获部分:
def __exit__(self, expType, expVal, expTrace):
self.__close()
如果其中的业务代码产生异常,程序会直接跳转到__exit__中,并以expType,expVal,expTrack的方式传递异常信息。如果程序正常执行,没有异常,则这三者都会是None。
我们现在需要做的就是在__exit__中加入可能的异常捕获:
def __exit__(self, expType, expVal, expTrace):
self.__close()
if expType != None:
raise UserException(UserException.ERROR_SQL_EXECUTE, 'sql执行出错')
应该注意到,这里没有判断异常类型就简单认为异常为SQL执行错误其实并不准确,因为上下文中的业务代码完全可以产生其它的数据库无关的异常,但这里只做简单演示。
需要注意的是,我们的异常处理部分是放在__exit__的最后,这是因为虽然是上下文内部产生异常,但其__enter__部分的代码已经正常执行,所以我们至少应该尝试先进行收尾动作,再来处理异常。
现在无需改变外部代码的情况下,凡是使用数据库上下文协议的,产生的异常都已被我们用自定义异常取代。而剩下的工作就是在外部的数据库操作中加入异常捕获和处理。
但不得不说在所有涉及数据库操作的地方加入try/except和处理代码是件枯燥乏味的事情,是不是有办法简化一下?
当然,是时候祭出我们的函数修饰符了。
在这里,当然可以考虑利用现成的函数修饰符,在其中加入异常捕获处理逻辑。但是我们目前的登录检测修饰符一来并不是所有页面都使用,二来和登录检测逻辑绑定并不合适,并不是所有需要检测登录的页面才需要异常处理。
所以我们新建一个专门用于异常处理的函数修饰符。
from functools import wraps
from user_exception import UserException
from flask import redirect
def excetpionDeal(webRouteFunc):
@wraps(webRouteFunc)
def exceptionWrap(*params, **kvParams):
try:
return webRouteFunc()
except UserException as e:
with open(file='error.log', mode='a', encoding='UTF-8') as errorLogOpen:
print(e.getErrorCode(), ':',
e.getErrorMessage(), file=errorLogOpen)
return redirect('/showError/系统出错,请联系管理员/3')
except Exception as e:
with open(file='error.log', mode='a', encoding='UTF-8') as errorLogOpen:
print(e, file=errorLogOpen)
return redirect('/showError/系统出错,请联系管理员/3')
return exceptionWrap
可以看到,在这个函数修饰符中,如果捕获到异常,我们就写错误日志,并跳转到错误页面。
剩下的就简单了,我们在所有页面入口加入函数修饰符:
@web.route("/login", methods=["GET"])
@excetpionDeal
def login():
'''登录页面'''
return render_template('login.html')
@web.route("/logout", methods=["GET"])
@excetpionDeal
def logout():
'''登出'''
session['uid'] = 0
session['name'] = ''
return redirect('/login')
这里只展示其中一部分。
需要注意的是错误显示页面不能加,否则会无限套娃无限跳转,具体原因我还没有头绪。
这里有意思的是日志页面:
@web.route('/log')
@excetpionDeal
@loginCheck
def showLog() -> 'html':
"""展示日志页面"""
logList = getLog()
return render_template("log.html", the_title="服务器日志", log_list=logList)
可以看出它用了三层函数修饰符,最外部的是flask框架的,用途是进行http响应,并处理返回渲染之类的。中间一层是我们的异常处理,最里层的是登录检测。而这个顺序也是合理的。
好了,关于异常的话题可以告一段落了,看着蛮简单的,一写博客梳理就觉得好累。。。
最后老规矩,附上所有工程文件:
链接:https://pan.baidu.com/s/1c5vsBkknkaqKxtzf_IL_rg
提取码:rchj
复制这段内容后打开百度网盘手机App,操作更方便哦