注:转载地址
https://blog.csdn.net/binjly/article/details/47321043
移动前端手机输入法自带emoji表情字符处理
今天,测试给我提了一个BUG,说移动端输入emoji表情无法提交。很早以前就有思考过,手机输入法里自带的emoji表情,应该是某些特殊字符。既然是字符,那应该都能提交才对,可是为啥会被卡住呢?搜了一下,才发现,原来emoji用到的字符是4字节的utf-16(utf-16有2字节和4字节两种编码),而我们的数据库是采用的utf-8,并且最大只允许3字节的字符。这样冲突就产生了,表单因为这些emoji字符的存在无法提交。
找到原因之后,接下来就要考虑解决方案了。目前考虑到的两种方案,一是让后台处理,把这个utf-16字符做一些转换(这里不做讨论)。第二种办法就是在前端直接转换成实体字符后再提交。这样,后台不用做任何处理,用户的提交的信息也得以保留,是不是一个两全其美的办法呢? 接下来我们要讨论的就是怎么把emoji表情字符转换成实体字符。
接下来我们要讨论的就是怎么把emoji表情字符转换成实体字符。
首先,我们来看看手机输入法里自带的emoji字符是什么样。下面截了一张图,来自 http://computerism.ru/emoji-smiles.htm 。我们看到,每个emoji表情字符对应的实体字符编码都比较大,如第一行的笑脸,实体字符为😊 。而且,我们注意到,后面还有一个16进制的编码 D83DDE0A。那这个编码是干嘛用的?接着往下看。
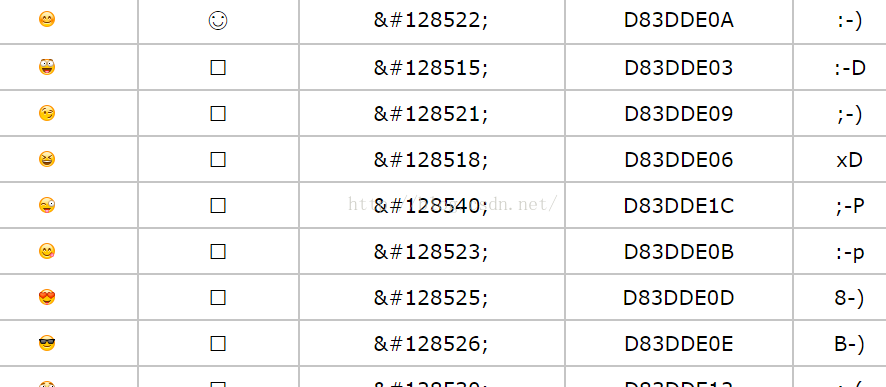
一、字符检测
要想把这些emoji表情字符转换成实体字符,那么就要先把它们检测出来。说到字符检测,我们的正则这时就该上场了。首先我们得确定这些字符的范围。前面我们已经知道,emoji表情字符用的是4字节的utf-16编码,而4字节的utf-16编码不被后台接受。所以,我们的检测范围就变成了把所有4字节的utf-16编码检测出来。我们通过搜索查到,4字节的utf-16编码范围为U+010000到U+10FFFF,那么,我们的正则是不是可以这么写:/[u010000-u10FFFF]/g ? NO,你会发现这个正则完全不能按我们预期工作。这是为什么呢?
上面这个问题,一些童鞋可能已经知道答案了。没错,就是javascript的编码问题引起的。我们知道,javascript采用的是unicode编码,再准确一点说,是ucs-2编码。从名字上,我们就已经知道,这种编码方案是2字节的。在2字节的编码中找4字节的字符,很显然并没那么简单。所以,我们得考虑一下,这个utf-16在ucs-2编码中是如何表示的呢?这里,我搜到了我们可爱的传教士——阮老师的一篇文章 《Unicode与JavaScript详解》(http://www.ruanyifeng.com/blog/2014/12/unicode.html) 。 简单来说,就是把utf-16的4字节字符,拆分成两个ucs-2的2字节字符。具体算法可参考阮老师的上述文章,本文就不详细讨论了。从阮老师的文章中,我们已经知道了,4字节utf-16在js中被用两个字符来表示,高位范围为0xD800 - 0xDBFF,低位范围为0xDC00 - 0xDFFF。那么我们用于检测的正则表达式也就出来了:/[uD800-uDBFF][uDC00-uDFFF]/g 。现在再回过头看看我们第一张图的那串16进制,D83DDE0A、D83DDE03,是不是突然就明白了呢?
二、转换算法
现在,我们已经能够检测出表单里的emoji表情字符。那么,重头戏来了,我们怎么把这个字符转换成实体字符呢?我们知道,实体字符是用来表示单个字符的编码,而我们的emoji表情,在js里,却是用两个字符来表示的。这可怎么办?等等,谁说emoji是两个字符,说好的4字节单字符呢?没错,一开始emoji就是用utf-16表示的啊 这里,我又参考了另一篇文章,http://unicode-table.com/cn/sets/emoji/,以下截了一部分图以做说明。
这里,我又参考了另一篇文章,http://unicode-table.com/cn/sets/emoji/,以下截了一部分图以做说明。
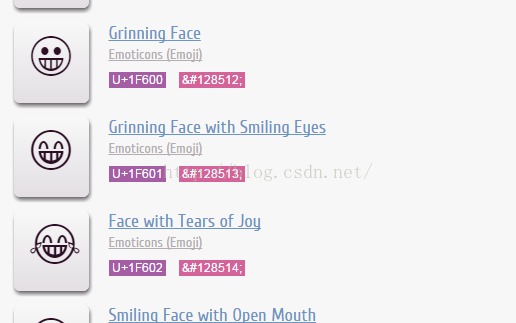
我们还是以那个笑脸的字符为例,其utf-16编码为U+1F600,我们转成十进制看看。
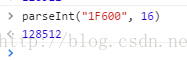
128512不正好是我们的实体编码😀 吗?所以,现在问题又变成了怎么取得emoji表情字符utf-16编码的问题了。可是,可是,我们刚刚已经知道了,在js里,emoji表情也是用ucs-2编码的啊,只不过变成了用两个字符来表示。那么,我们的问题最终演变成了怎么从ucs-2编码转换成utf-16编码的问题。
感谢阮老师,在阮老师的那篇文章中,有提到utf-16转ucs-2(unicode)的公式
- H = Math.floor((c-0x10000) / 0x400)+0xD800 // 高位
- L = (c - 0x10000) % 0x400 + 0xDC00 // 低位
- H = Q - 0x10000 / 0x400 + 0xD800
- L = M - 0x10000 % 0x400 + 0xDC00
- C = Q * 0x400 + M
- // 因为0x10000 % 0x400 = 0,故推得:
- H = Q - 0x10000 / 0x400 + 0xD800
- L = M + 0xDC00
- C = Q * 0x400 + M
- // 根据C的公式,把H*0x400再加L,得到:
- H * 0x400 + L = Q * 0x400 - 0x10000 / 0x400 * 0x400 + 0xD800 * 0x400 + M + 0xDC00
- // 最后把Q * 0x400 + M换成C,得到:
- H * 0x400 + L = C - 0x10000 + 0xD800 * 0x400 + 0xDC00
- // 移项后,我们最终的公式为:
- C = (H - 0xD800) * 0x400 + 0x10000 + L - 0xDC00
- /**
- * 用于把用utf16编码的字符转换成实体字符,以供后台存储
- * @param {string} str 将要转换的字符串,其中含有utf16字符将被自动检出
- * @return {string} 转换后的字符串,utf16字符将被转换成&#xxxx;形式的实体字符
- */
- function utf16toEntities(str) {
- var patt=/[ud800-udbff][udc00-udfff]/g; // 检测utf16字符正则
- str = str.replace(patt, function(char){
- var H, L, code;
- if (char.length===2) {
- H = char.charCodeAt(0); // 取出高位
- L = char.charCodeAt(1); // 取出低位
- code = (H - 0xD800) * 0x400 + 0x10000 + L - 0xDC00; // 转换算法
- return "&#" + code + ";";
- } else {
- return char;
- }
- });
- return str;
- }
运行结果如下:
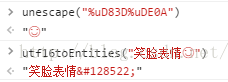
细心的童鞋,在刚刚看那些参考文章的时候,也许已经发现了,其实并不是所有的emoji表情字符都是utf-16编码的,也有一部分落在了ucs-2编码的范围(即只用了两个字节)。不过这都不是重点,重点是,我们已经成功的把utf-16编码部分的emoji表情转换为了实体字符。