一、基本信息
1.1作者及其他
#编译环境:pycharm2017 python3.6 #项目:结对项目之词频统计——增强功能 #作者:1613072034 陈原 # 1613072035 周怡峰 #编程日期:2018年11月29日
1.2本次作业地址
https://edu.cnblogs.com/campus/ntu/Embedded_Application/homework/2088
二、项目分析
1.步骤:
(1)按照作业要求将函数封装成类,以便让使用不同环境的用户(例如,命令行、Windows图形界面程序,网页程序,手机App)进行方便的调用。
import re class WordCount(): def __init__(self, dst, m, n, o): # dst:文件路径;m:每个词组长度;n:输出的单词数量;o:设定生成文件的存储路径 self.dst = dst self.m = m self.n = n self.o = o def process_file(self): # 读取文件 d = open(self.dst, "r") bvffer = d.read() return bvffer def process_rowCount(self, bvffer): # 计算文章的行数 if bvffer: count = 1 for word in bvffer: # 开始计数 if word == ' ': count = count + 1 return count def process_wordNumber(self, bvffer): if bvffer: bvffer = bvffer.lower() # 将文本中的大写字母转换为小写 for ch in '{}!"#%()*+-,-./:;<=>?&@“”[]^_|': bvffer = bvffer.replace(ch, " ") # 将文本中非法字符转化为空格 words = bvffer.split() # 用空格分割字符串 if words: wordNew = [] words_select = '[a-z]{4}(w)*' for i in range(len(words)): word = re.match(words_select, words[i]) # 如果不匹配,返回NULL类型 if word: wordNew.append(word.group()) word_freq = {} for word in wordNew: # 将正则匹配的结果进行统计 word_freq[word] = word_freq.get(word, 0) + 1 return wordNew, word_freq def process_MPhrase(self, bvffer): # 查找m个单词组成的词组 if bvffer: model = '' for i in range(self.m): model += '[a-z]+' if i < self.m - 1: model += 's' result = re.findall(model, bvffer) # 正则查找词组 word_freq = {} for word in result: # 将正则匹配的结果进行统计 word_freq[word] = word_freq.get(word, 0) + 1 return word_freq def output_result(self, word_freq): if word_freq: sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:self.n]: # 输出前n个频率最高的单词 print('<' + str(item[0]) + '>:' + str(item[1])) return sorted_word_freq[:self.n] def print_result(self): print('查询路径为:' + str(self.dst) + '的文本') print('统计词组长度为:' + str(self.m) + '且词频前' + str(self.n) + '的单词') bvffer = WordCount.process_file(self) # 文件读入缓冲区 lines = WordCount.process_rowCount(self, bvffer) # 计算文章的行数 wordNew, word_freq = WordCount.process_wordNumber(self, bvffer) # 筛选出符合单词标准的单词词组 sum_words = len(wordNew) # 计算出符合单词标准的单词数量 phrase_freq = WordCount.process_MPhrase(self, bvffer) show_sum_words = 'words:' + str(sum_words) show_lines = 'lines:' + str(lines) print(show_sum_words) # 显示文章单词总数 print(show_lines) # 显示文章的行数 itemsWord = WordCount.output_result(self, word_freq) itemsPhrase = WordCount.output_result(self, phrase_freq) with open(self.o, 'w+') as w: w.write(show_lines + ' ') w.write(show_sum_words + ' ') # 单词的可视化输出 for itemWord in itemsWord: item = '<' + str(itemWord[0]) + '>:' + str(itemWord[1]) + ' ' w.write(item) # 词组的可视化输出 for itemPhrase in itemsPhrase: item = '<' + str(itemPhrase[0]) + '>:' + str(itemPhrase[1]) + ' ' w.write(item) print('写入' + self.o + '文件已完成!') w.close()
(2)我们现在pycharm里试验一下能否成功统计词频(文本文件使用的是同一路径下的“Gone_with_the_wind.txt”,在主函数中预设统计3个单词组成的词组和输出出现频率最高的4个单词,并将结果保存成re.txt)
if __name__ == '__main__': obj = WordCount('src/Gone_with_the_wind.txt', 3, 4, 'src/re.txt') obj.print_result()
我们可以看见按照要求输出

(3)想要实现按照用户的要求对用户指定文本进行分析,就需要学习parserm模块中的add_agrumen函数,将你想输入的文本,要求规定到parser中,然后类似参数传递一样传递到class类中的各个函数得以实现。
def main(): parser = argparse.ArgumentParser(description="your script description") # description参数可以用于插入描述脚本用途的信息,可以为空 parser.add_argument('--i', '-i', type=str, default='src/Gone_with_the_wind.txt', help="读取文件路径") parser.add_argument('--m', '-m', type=int, default=3, help="输出的单个词组数量") parser.add_argument('--n', '-n', type=int, default=4, help="输出的频率前n个的单词和词组数量") parser.add_argument('--o', '-o', type=str, default='src/result.txt', help="读取文件路径") args = parser.parse_args() # 将变量以键-值的字典形式存入args字典 dst = args.i m = args.m n = args.n o = args.o obj =WordCount.WordCount(dst, m, n, o) obj.print_result()
(4)在Dos命令提示符中传递参数
1.指定文本分析 -i 参数设定读入的文件路径(先前在声明中有默认值,所以不指定其他要求程序会按默认值执行)
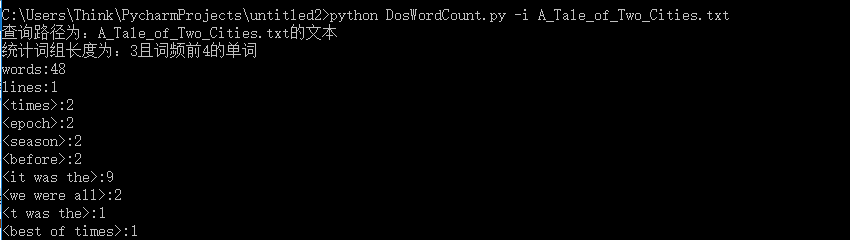
2.指定统计词组长度为4 -m 参数设定统计的词组长度
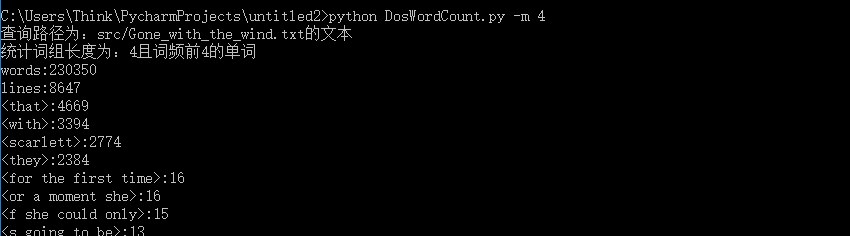
3.指定统计出现频率最高的2个单词 -n 参数设定输出的单词数量

4. -o 参数设定生成文件的存储路径
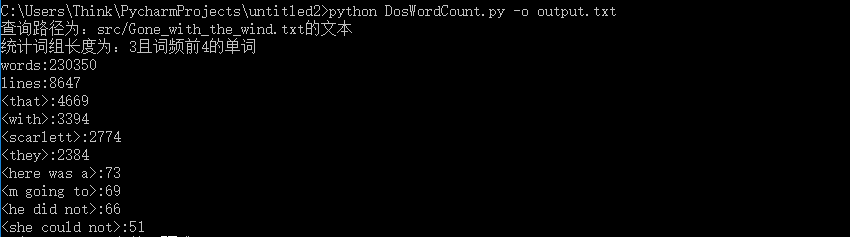

5.总结性的一次性传递所有参数 多参数的混合使用(input.txt是自己弄的一个文本文档)

三、性能分析
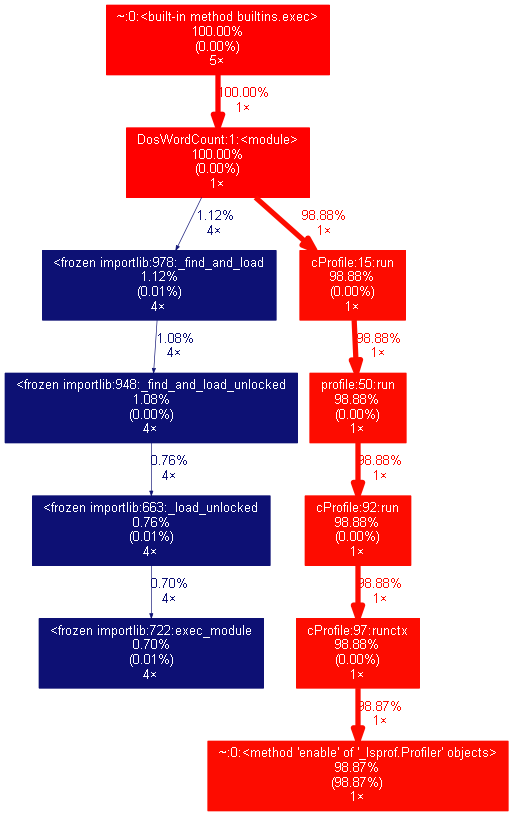
四、PSP 表格
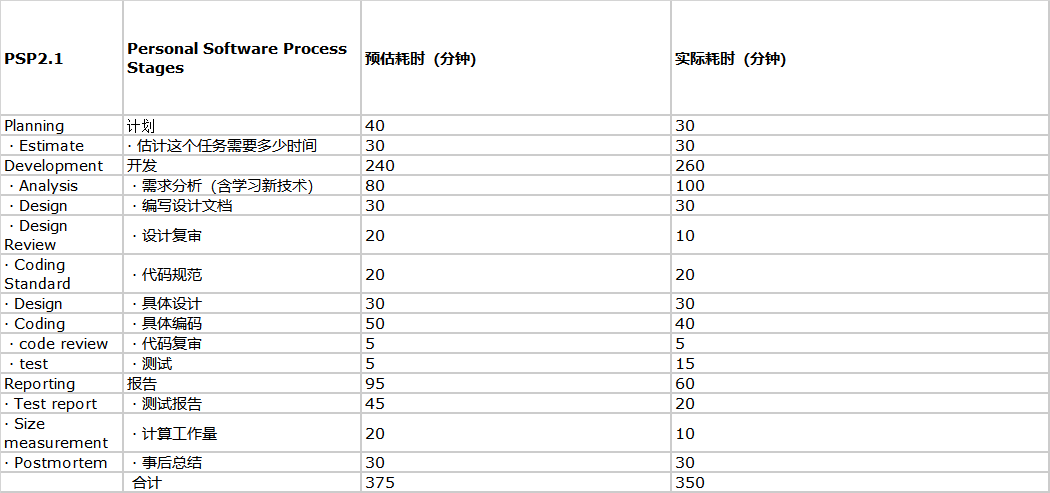
五、事后分析与总结
(1)针对某个问题的讨论决策过程:我们对API接口着重分析,我们两个也分成了两个方向进行研究,陈原主要针对类分装做一个接口在命令行进行输入参数;周怡峰主要是想在web窗口上做一个接口进行输入参数。最终我们讨论的结果是还是在命令行上进行输入参数做一个接口。
(2)评价对方:请评价一下你的合作伙伴,又哪些具体的优点和需要改进的地方。 这个部分两人都要提供自己的看法。
周怡峰:陈原非常循循善诱,我不会的地方很耐心的指导,善于思考并且能付诸行动,希望对git指令了解更多。
陈原:周怡峰非常认真,非常负责任,python的基础也是相当不错的,对于新接触的知识,立刻会付出行动进行验证,对我们的结对编程做出了巨大的贡献。
(3)评价整个过程:关于结对过程的建议
结对编程不仅考研了编程能力,也考验了合作能力,我们在编程过程中相互鼓励,分工合作,因为一旦某个功能实现不了,一个人的话很容易暴躁,自闭。两个人可以相互鼓励,也同时形成一种良性竞争,比如这个方法是其中一个人想出来的,另一个人就会去思考有没有更快的方法。希望有机会可以再次结对编程,
(4)结对编程照片
