语言模型:
我 今天 下午 打 篮球
p(S)=p(w1,w2,w3,w4,w5,…,wn)
=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
.
p(S)被称为语言模型,即用来计算一个句子概率的模型
p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)称为条件概率,在w1发生的情况下,发生w2的概率,在w1,w2都发生的情况下w3发生的概率。
每一个词的出现都不是独立的,都跟之前的词有关系。
再将每个概率乘起来,就是这一句话会出现的概率。
语言模型存在的问题:

如果有一段很长的话,那么这个概率将会很小
比如有一句话:我今天要学习深度学习算法,学习的内容是自然语言处理。
wi是最后一个词,处理
那么处理这个词在整句话中出现的概率,就是整句话的概率除以这句话没有出现处理的概率。
这个缺点就是计算量很大,会导致过于稀疏,参数空间会很大。
解决思路:
假设下一个词的出现依赖它前面的一个词:
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
=p(w1)p(w2|w1)p(w3|w2)...p(wn|wn-1)
假设下一个词的出现依赖它前面的两个词:
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|w1,w2,...,wn-1)
=p(w1)p(w2|w1)p(w3|w1,w2)...p(wn|wn-1,wn-2)
这么做的目的不是为了单纯的减少计算量和减少参数空间。
在通常的情况下,一个词的出现也就是跟前2~3个词有很大的关系。
这种模型称作 N-gram模型
例如下面的例子:
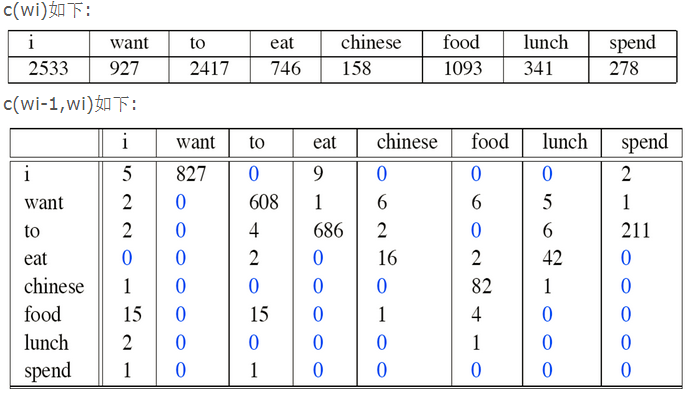
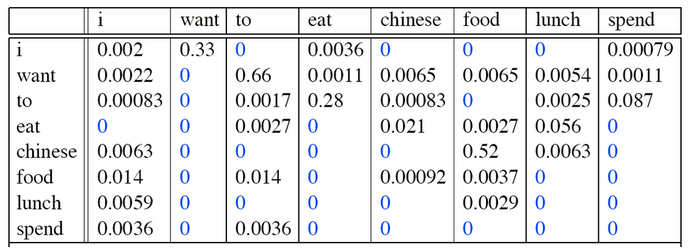
p(I want chinesefood)=
P(I)
×P(want|I)
×P(chinese|want)
×P(food|chinese)
I后面接want的概率就是827/2533=0.33
参数个数:

N表示词典中有多少个词
n表示关联前几个词
词典中自身有 个组合,
个组合,
那么参数的个数: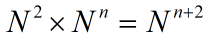
一般n=2,n=3,n=4就可以了