正则化惩罚项:
原先的回归算法算出的$Theta _{1}...Theta _{10}$
如果有2个模型A,B
A有$Theta _{1}...Theta _{10}$
B也有$Theta _{1}...Theta _{10}$
如果两个recall值都是90%,但是分布不同
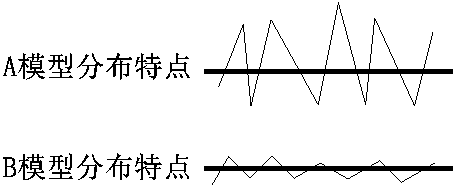
模型的参数浮动的范围越小,过拟合的程度也就越小,过拟合的意思就是在训练集表现的很好,在测试集表现很差,
过拟合是一种非常常见的现象,我们总是希望得到B模型
如何得到B模型?
引入正则化惩罚项,大力度惩罚A的θ,小力度惩罚B的θ
L2正则化:
我们的损失函数(LOSS)应该是越低越好
$L_{2}=LOSS+frac{1}{2}W^{2}$
W表示θ的浮动程度
L1正则化:
$L_{1}=LOSS+frac{1}{2}left | W ight |$
在$L_{1},L_{2}$前加入λ或者C
$lambda L_{1},lambda L_{2}$
表示惩罚力度,0.1、1、10、100
混淆矩阵:
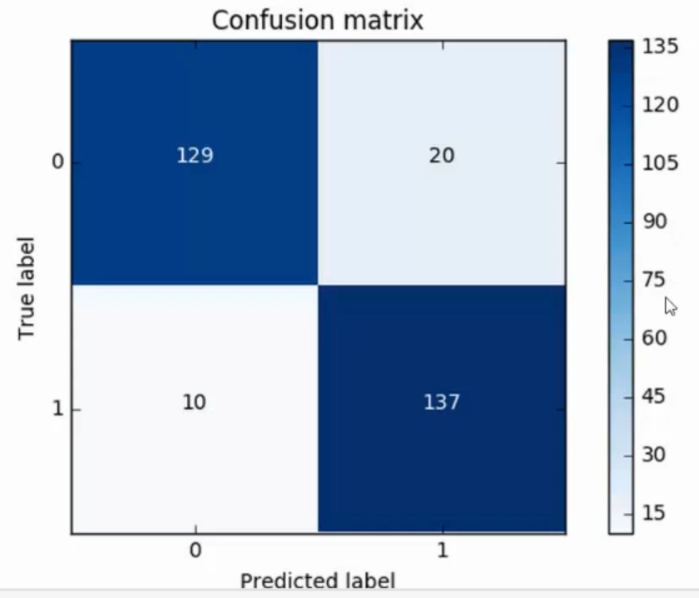
上图是下采样后的混淆矩阵
X轴表示预测值
Y轴表示真实值
此矩阵对应于之前的recall值的分析图
TP = 137
FN = 10
则recall = 137/147 = 0.932
那么在原始数据集上的混淆矩阵是

这里存在为了找135个违规的,误杀了8581个正常的
下采样的缺点就是误杀有些大
可以改变sigmoid函数的阈值,进行减少误杀
下图是将阈值从0.1~0.9设置之后的recall值

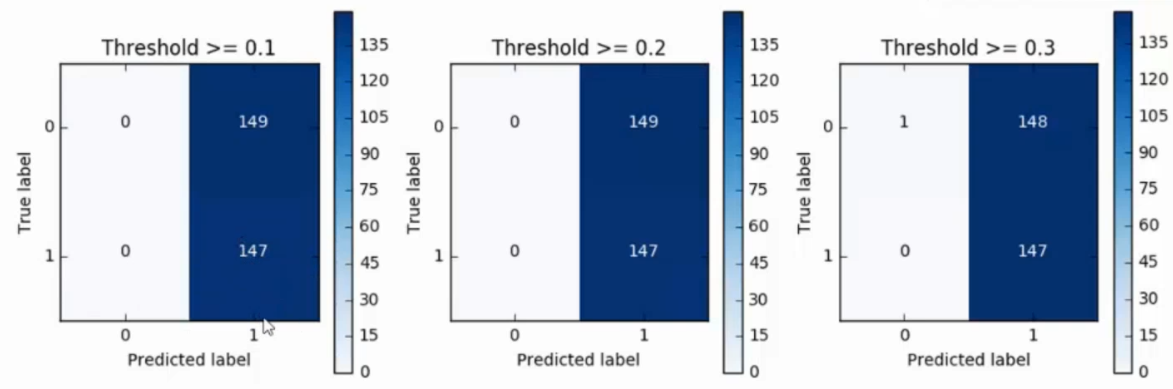
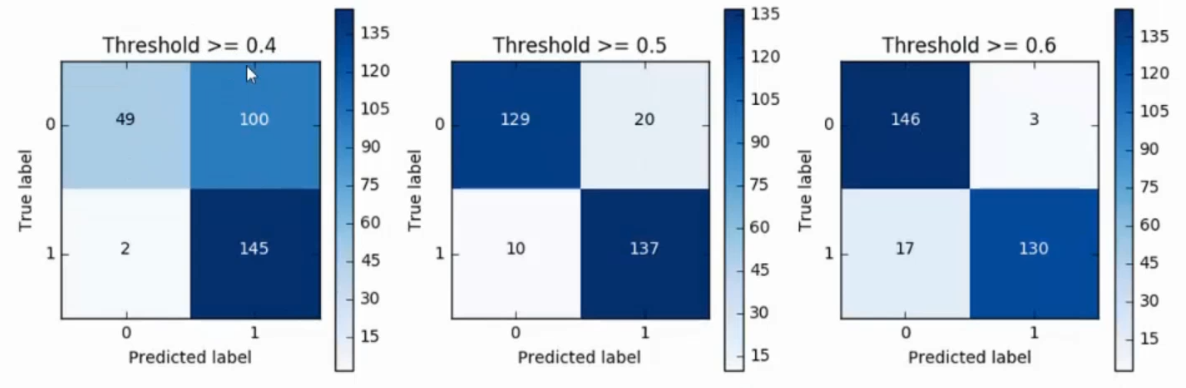
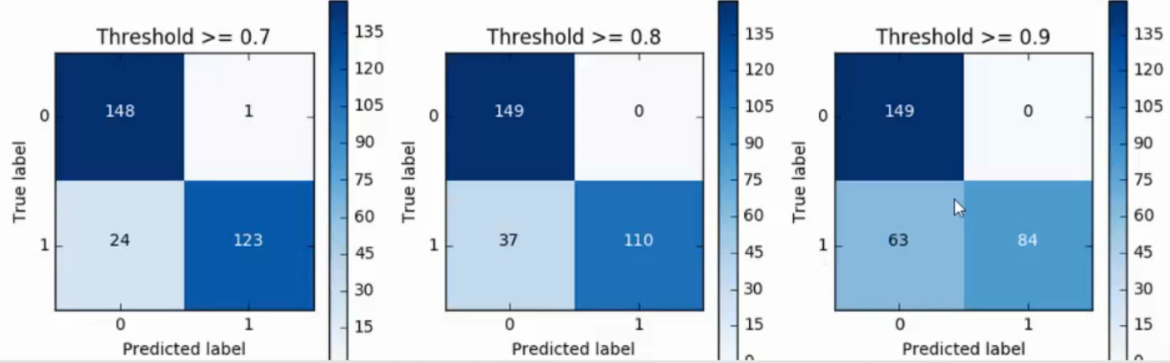
不可能有完美的模型,如果精度和recall值达到要求即可
过采样:
SMOTE算法:
找到少数类的样本,计算少数类样本到其他所有样本的一个距离,将所有计算出的距离进行排序,生成原始数据的多少倍,就选前多少个距离
$x_{new}=x+rand(0,1) imes ( ilde{x}-x)$
x表示样本
x~表示距离
SMOTE只生成训练集的数据,测试集不要生成
过采样的混淆矩阵
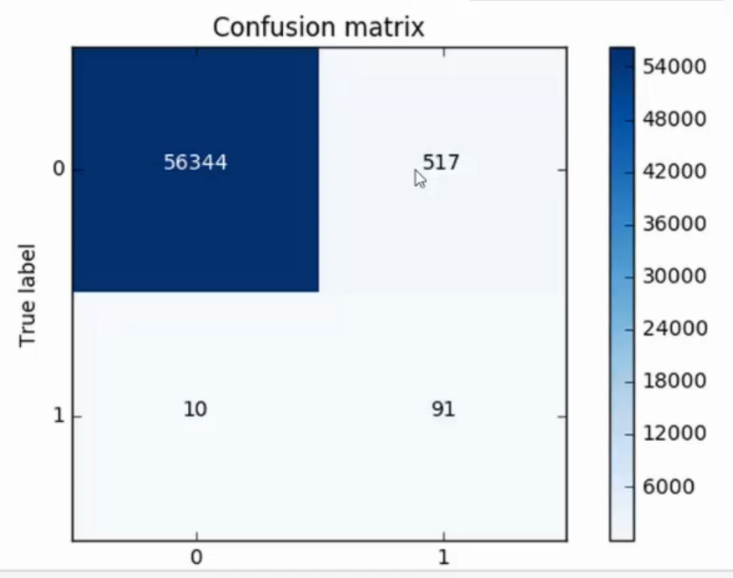
误杀值稍微降低,但是模型的精度偏高了
经验:
对于样本 不均衡的数据,能利用多的数据就利用多的数据,能利用生成的方式就利用生成的方式,
整体流程:
观察数据,
提取特征(特征工程,今后会讲),
标准化数据
下采样/过采样(SMOTE算法)
交叉验证获取最优参数
混淆矩阵和模型评估标准
sigmoid函数阈值改变后比较