【学习目标】
- Scrapy-redis分布式的运行流程
- Scheduler与Scrapy自带的Scheduler有什么区别
- Duplication Filter作用
- 源码自带三种spider的使用
6. Scrapy-redis分布式组件
Scrapy 和 scrapy-redis的区别
Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件)。
pip install scrapy-redis
Scrapy-redis提供了下面四种组件(components):(四种组件意味着这四个模块都要做相应的修改)
SchedulerDuplication FilterItem PipelineBase Spider
scrapy-redis架构
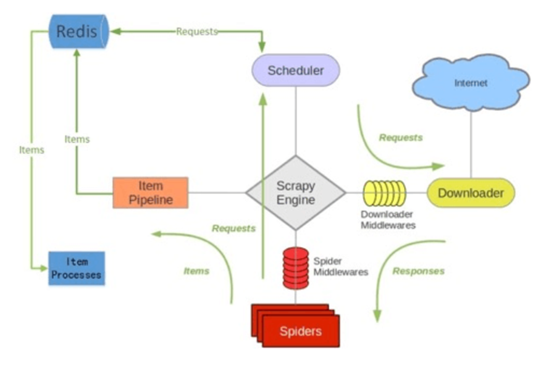
如上图所⽰示,scrapy-redis在scrapy的架构上增加了redis,基于redis的特性拓展了如下组件:
Scheduler:
Scrapy改造了python本来的collection.deque(双向队列)形成了自己的Scrapy queue(https://github.com/scrapy/queuelib/blob/master/queuelib/queue.py)),但是Scrapy多个spider不能共享待爬取队列Scrapy queue, 即Scrapy本身不支持爬虫分布式,scrapy-redis 的解决是把这个Scrapy queue换成redis数据库(也是指redis队列),从同一个redis-server存放要爬取的request,便能让多个spider去同一个数据库里读取。
Scrapy中跟“待爬队列”直接相关的就是调度器Scheduler,它负责对新的request进行入列操作(加入Scrapy queue),取出下一个要爬取的request(从Scrapy queue中取出)等操作。它把待爬队列按照优先级建立了一个字典结构,比如:
{优先级0 : 队列0
优先级1 : 队列1
优先级2 : 队列2
}
然后根据request中的优先级,来决定该入哪个队列,出列时则按优先级较小的优先出列。为了管理这个比较高级的队列字典,Scheduler需要提供一系列的方法。但是原来的Scheduler已经无法使用,所以使用Scrapy-redis的scheduler组件。
Duplication Filter:
Scrapy中用集合实现这个request去重功能,Scrapy中把已经发送的request指纹放入到一个集合中,把下一个request的指纹拿到集合中比对,如果该指纹存在于集合中,说明这个request发送过了,如果没有则继续操作。这个核心的判重功能是这样实现的:
def request_seen(self, request): # self.request_figerprints就是一个指纹集合 fp = self.request_fingerprint(request) # 这就是判重的核心操作 if fp in self.fingerprints: return True self.fingerprints.add(fp) if self.file: self.file.write(fp + os.linesep)
在scrapy-redis中去重是由Duplication Filter组件来实现的,它通过redis的set 不重复的特性,巧妙的实现了Duplication Filter去重。scrapy-redis调度器从引擎接受request,将request的指纹存⼊redis的set检查是否重复,并将不重复的request push写⼊redis的 request queue。
引擎请求request(Spider发出的)时,调度器从redis的request queue队列⾥里根据优先级pop 出⼀个request 返回给引擎,引擎将此request发给spider处理。
Item Pipeline:
引擎将(Spider返回的)爬取到的Item给Item Pipeline,scrapy-redis 的Item Pipeline将爬取到的 Item 存⼊redis的 items queue。
修改过Item Pipeline可以很方便的根据 key 从 items queue 提取item,从⽽实现 items processes集群。
Base Spider:
不再使用scrapy原有的Spider类,重写的RedisSpider继承了Spider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类。
当我们生成一个Spider继承RedisSpider时,调用setup_redis函数,这个函数会去连接redis数据库,然后会设置signals(信号):
- 一个是当spider空闲时候的signal,会调用spider_idle函数,这个函数调用
schedule_next_request函数,保证spider是一直活着的状态,并且抛出DontCloseSpider异常。 - 一个是当抓到一个item时的signal,会调用item_scraped函数,这个函数会调用
schedule_next_request函数,获取下一个request。
6.1. 源码分析参考:Connection
官方站点:https://github.com/rolando/scrapy-redis
scrapy-redis的官方文档写的比较简洁,没有提及其运行原理,所以如果想全面的理解分布式爬虫的运行原理,还是得看scrapy-redis的源代码才行。
scrapy-redis工程的主体还是是redis和scrapy两个库,工程本身实现的东西不是很多,这个工程就像胶水一样,把这两个插件粘结了起来。下面我们来看看,scrapy-redis的每一个源代码文件都实现了什么功能,最后如何实现分布式的爬虫系统:
负责根据setting中配置实例化redis连接。被dupefilter和scheduler调用,总之涉及到redis存取的都要使用到这个模块。


# 这里引入了redis模块,这个是redis-python库的接口,用于通过python访问redis数据库, # 这个文件主要是实现连接redis数据库的功能,这些连接接口在其他文件中经常被用到 import redis import six from scrapy.utils.misc import load_object DEFAULT_REDIS_CLS = redis.StrictRedis # 可以在settings文件中配置套接字的超时时间、等待时间等 # Sane connection defaults. DEFAULT_PARAMS = { 'socket_timeout': 30, 'socket_connect_timeout': 30, 'retry_on_timeout': True, } # 要想连接到redis数据库,和其他数据库差不多,需要一个ip地址、端口号、用户名密码(可选)和一个整形的数据库编号 # Shortcut maps 'setting name' -> 'parmater name'. SETTINGS_PARAMS_MAP = { 'REDIS_URL': 'url', 'REDIS_HOST': 'host', 'REDIS_PORT': 'port', } def get_redis_from_settings(settings): """Returns a redis client instance from given Scrapy settings object. This function uses ``get_client`` to instantiate the client and uses ``DEFAULT_PARAMS`` global as defaults values for the parameters. You can override them using the ``REDIS_PARAMS`` setting. Parameters ---------- settings : Settings A scrapy settings object. See the supported settings below. Returns ------- server Redis client instance. Other Parameters ---------------- REDIS_URL : str, optional Server connection URL. REDIS_HOST : str, optional Server host. REDIS_PORT : str, optional Server port. REDIS_PARAMS : dict, optional Additional client parameters. """ params = DEFAULT_PARAMS.copy() params.update(settings.getdict('REDIS_PARAMS')) # XXX: Deprecate REDIS_* settings. for source, dest in SETTINGS_PARAMS_MAP.items(): val = settings.get(source) if val: params[dest] = val # Allow ``redis_cls`` to be a path to a class. if isinstance(params.get('redis_cls'), six.string_types): params['redis_cls'] = load_object(params['redis_cls']) # 返回的是redis库的Redis对象,可以直接用来进行数据操作的对象 return get_redis(**params) # Backwards compatible alias. from_settings = get_redis_from_settings def get_redis(**kwargs): """Returns a redis client instance. Parameters ---------- redis_cls : class, optional Defaults to ``redis.StrictRedis``. url : str, optional If given, ``redis_cls.from_url`` is used to instantiate the class. **kwargs Extra parameters to be passed to the ``redis_cls`` class. Returns ------- server Redis client instance. """ redis_cls = kwargs.pop('redis_cls', DEFAULT_REDIS_CLS) url = kwargs.pop('url', None) if url: return redis_cls.from_url(url, **kwargs) else: return redis_cls(**kwargs)
6.2. 源码分析参考:Dupefilter
dupefilter.py
负责执行requst的去重,实现的很有技巧性,使用redis的set数据结构。但是注意scheduler并不使用其中用于在这个模块中实现的dupefilter键做request的调度,而是使用queue.py模块中实现的queue。
当request不重复时,将其存入到queue中,调度时将其弹出。
import logging import time from scrapy.dupefilters import BaseDupeFilter from scrapy.utils.request import request_fingerprint from .connection import get_redis_from_settings DEFAULT_DUPEFILTER_KEY = "dupefilter:%(timestamp)s" logger = logging.getLogger(__name__) # TODO: Rename class to RedisDupeFilter. class RFPDupeFilter(BaseDupeFilter): """Redis-based request duplicates filter. This class can also be used with default Scrapy's scheduler. """ logger = logger def __init__(self, server, key, debug=False): """Initialize the duplicates filter. Parameters ---------- server : redis.StrictRedis The redis server instance. key : str Redis key Where to store fingerprints. debug : bool, optional Whether to log filtered requests. """ self.server = server self.key = key self.debug = debug self.logdupes = True @classmethod def from_settings(cls, settings): """Returns an instance from given settings. This uses by default the key ``dupefilter:<timestamp>``. When using the ``scrapy_redis.scheduler.Scheduler`` class, this method is not used as it needs to pass the spider name in the key. Parameters ---------- settings : scrapy.settings.Settings Returns ------- RFPDupeFilter A RFPDupeFilter instance. """ server = get_redis_from_settings(settings) # XXX: This creates one-time key. needed to support to use this # class as standalone dupefilter with scrapy's default scheduler # if scrapy passes spider on open() method this wouldn't be needed # TODO: Use SCRAPY_JOB env as default and fallback to timestamp. key = DEFAULT_DUPEFILTER_KEY % {'timestamp': int(time.time())} debug = settings.getbool('DUPEFILTER_DEBUG') return cls(server, key=key, debug=debug) @classmethod def from_crawler(cls, crawler): """Returns instance from crawler. Parameters ---------- crawler : scrapy.crawler.Crawler Returns ------- RFPDupeFilter Instance of RFPDupeFilter. """ return cls.from_settings(crawler.settings) def request_seen(self, request): """Returns True if request was already seen. Parameters ---------- request : scrapy.http.Request Returns ------- bool """ fp = self.request_fingerprint(request) # This returns the number of values added, zero if already exists. added = self.server.sadd(self.key, fp) return added == 0 def request_fingerprint(self, request): """Returns a fingerprint for a given request. Parameters ---------- request : scrapy.http.Request Returns ------- str """ return request_fingerprint(request) def close(self, reason=''): """Delete data on close. Called by Scrapy's scheduler. Parameters ---------- reason : str, optional """ self.clear() def clear(self): """Clears fingerprints data.""" self.server.delete(self.key) def log(self, request, spider): """Logs given request. Parameters ---------- request : scrapy.http.Request spider : scrapy.spiders.Spider """ if self.debug: msg = "Filtered duplicate request: %(request)s" self.logger.debug(msg, {'request': request}, extra={'spider': spider}) elif self.logdupes: msg = ("Filtered duplicate request %(request)s" " - no more duplicates will be shown" " (see DUPEFILTER_DEBUG to show all duplicates)") msg = "Filtered duplicate request: %(request)s" self.logger.debug(msg, {'request': request}, extra={'spider': spider}) self.logdupes = False
这个文件看起来比较复杂,重写了scrapy本身已经实现的request判重功能。因为本身scrapy单机跑的话,只需要读取内存中的request队列或者持久化的request队列(scrapy默认的持久化似乎是json格式的文件,不是数据库)就能判断这次要发出的request url是否已经请求过或者正在调度(本地读就行了)。而分布式跑的话,就需要各个主机上的scheduler都连接同一个数据库的同一个request池来判断这次的请求是否是重复的了。
在这个文件中,通过继承BaseDupeFilter重写他的方法,实现了基于redis的判重。根据源代码来看,scrapy-redis使用了scrapy本身的一个fingerprint接口request_fingerprint,这个接口很有趣,根据scrapy文档所说,他通过hash来判断两个url是否相同(相同的url会生成相同的hash结果),但是当两个url的地址相同,get型参数相同但是顺序不同时,也会生成相同的hash结果(这个真的比较神奇。。。)所以scrapy-redis依旧使用url的fingerprint来判断request请求是否已经出现过。
这个类通过连接redis,使用一个key来向redis的一个set中插入fingerprint(这个key对于同一种spider是相同的,redis是一个key-value的数据库,如果key是相同的,访问到的值就是相同的,这里使用spider名字+DupeFilter的key就是为了在不同主机上的不同爬虫实例,只要属于同一种spider,就会访问到同一个set,而这个set就是他们的url判重池),如果返回值为0,说明该set中该fingerprint已经存在(因为集合是没有重复值的),则返回False,如果返回值为1,说明添加了一个fingerprint到set中,则说明这个request没有重复,于是返回True,还顺便把新fingerprint加入到数据库中了。 DupeFilter判重会在scheduler类中用到,每一个request在进入调度之前都要进行判重,如果重复就不需要参加调度,直接舍弃就好了,不然就是白白浪费资源。
6.3. 源码分析参考:Picklecompat
picklecompat.py
"""A pickle wrapper module with protocol=-1 by default.""" try: import cPickle as pickle # PY2 except ImportError: import pickle def loads(s): return pickle.loads(s) def dumps(obj): return pickle.dumps(obj, protocol=-1)
这里实现了loads和dumps两个函数,其实就是实现了一个序列化器。
因为redis数据库不能存储复杂对象(key部分只能是字符串,value部分只能是字符串,字符串列表,字符串集合和hash),所以我们存啥都要先串行化成文本才行。
这里使用的就是python的pickle模块,一个兼容py2和py3的串行化工具。这个serializer主要用于一会的scheduler存reuqest对象。
6.4. 源码分析参考:Pipelines
pipelines.py
from scrapy.utils.misc import load_object from scrapy.utils.serialize import ScrapyJSONEncoder from twisted.internet.threads import deferToThread from . import connection default_serialize = ScrapyJSONEncoder().encode class RedisPipeline(object): """Pushes serialized item into a redis list/queue""" def __init__(self, server, key='%(spider)s:items', serialize_func=default_serialize): self.server = server self.key = key self.serialize = serialize_func @classmethod def from_settings(cls, settings): params = { 'server': connection.from_settings(settings), } if settings.get('REDIS_ITEMS_KEY'): params['key'] = settings['REDIS_ITEMS_KEY'] if settings.get('REDIS_ITEMS_SERIALIZER'): params['serialize_func'] = load_object( settings['REDIS_ITEMS_SERIALIZER'] ) return cls(**params) @classmethod def from_crawler(cls, crawler): return cls.from_settings(crawler.settings) def process_item(self, item, spider): return deferToThread(self._process_item, item, spider) def _process_item(self, item, spider): key = self.item_key(item, spider) data = self.serialize(item) self.server.rpush(key, data) return item def item_key(self, item, spider): """Returns redis key based on given spider. Override this function to use a different key depending on the item and/or spider. """ return self.key % {'spider': spider.name}
这是是用来实现分布式处理的作用。它将Item存储在redis中以实现分布式处理。由于在这里需要读取配置,所以就用到了from_crawler()函数。
pipelines文件实现了一个item pipieline类,和scrapy的item pipeline是同一个对象,通过从settings中拿到我们配置的REDIS_ITEMS_KEY作为key,把item串行化之后存入redis数据库对应的value中(这个value可以看出是个list,我们的每个item是这个list中的一个结点),这个pipeline把提取出的item存起来,主要是为了方便我们延后处理数据。
6.5. 源码分析参考:Queue
queue.py
该文件实现了几个容器类,可以看这些容器和redis交互频繁,同时使用了我们上边picklecompat中定义的序列化器。这个文件实现的几个容器大体相同,只不过一个是队列,一个是栈,一个是优先级队列,这三个容器到时候会被scheduler对象实例化,来实现request的调度。比如我们使用SpiderQueue为调度队列的类型,到时候request的调度方法就是先进先出,而实用SpiderStack就是先进后出了。
从SpiderQueue的实现看出来,他的push函数就和其他容器的一样,只不过push进去的request请求先被scrapy的接口request_to_dict变成了一个dict对象(因为request对象实在是比较复杂,有方法有属性不好串行化),之后使用picklecompat中的serializer串行化为字符串,然后使用一个特定的key存入redis中(该key在同一种spider中是相同的)。而调用pop时,其实就是从redis用那个特定的key去读其值(一个list),从list中读取最早进去的那个,于是就先进先出了。 这些容器类都会作为scheduler调度request的容器,scheduler在每个主机上都会实例化一个,并且和spider一一对应,所以分布式运行时会有一个spider的多个实例和一个scheduler的多个实例存在于不同的主机上,但是,因为scheduler都是用相同的容器,而这些容器都连接同一个redis服务器,又都使用spider名加queue来作为key读写数据,所以不同主机上的不同爬虫实例公用一个request调度池,实现了分布式爬虫之间的统一调度。
from scrapy.utils.reqser import request_to_dict, request_from_dict from . import picklecompat class Base(object): """Per-spider queue/stack base class""" def __init__(self, server, spider, key, serializer=None): """Initialize per-spider redis queue. Parameters: server -- redis connection spider -- spider instance key -- key for this queue (e.g. "%(spider)s:queue") """ if serializer is None: # Backward compatibility. # TODO: deprecate pickle. serializer = picklecompat if not hasattr(serializer, 'loads'): raise TypeError("serializer does not implement 'loads' function: %r" % serializer) if not hasattr(serializer, 'dumps'): raise TypeError("serializer '%s' does not implement 'dumps' function: %r" % serializer) self.server = server self.spider = spider self.key = key % {'spider': spider.name} self.serializer = serializer def _encode_request(self, request): """Encode a request object""" obj = request_to_dict(request, self.spider) return self.serializer.dumps(obj) def _decode_request(self, encoded_request): """Decode an request previously encoded""" obj = self.serializer.loads(encoded_request) return request_from_dict(obj, self.spider) def __len__(self): """Return the length of the queue""" raise NotImplementedError def push(self, request): """Push a request""" raise NotImplementedError def pop(self, timeout=0): """Pop a request""" raise NotImplementedError def clear(self): """Clear queue/stack""" self.server.delete(self.key) class SpiderQueue(Base): """Per-spider FIFO queue""" def __len__(self): """Return the length of the queue""" return self.server.llen(self.key) def push(self, request): """Push a request""" self.server.lpush(self.key, self._encode_request(request)) def pop(self, timeout=0): """Pop a request""" if timeout > 0: data = self.server.brpop(self.key, timeout) if isinstance(data, tuple): data = data[1] else: data = self.server.rpop(self.key) if data: return self._decode_request(data) class SpiderPriorityQueue(Base): """Per-spider priority queue abstraction using redis' sorted set""" def __len__(self): """Return the length of the queue""" return self.server.zcard(self.key) def push(self, request): """Push a request""" data = self._encode_request(request) score = -request.priority # We don't use zadd method as the order of arguments change depending on # whether the class is Redis or StrictRedis, and the option of using # kwargs only accepts strings, not bytes. self.server.execute_command('ZADD', self.key, score, data) def pop(self, timeout=0): """ Pop a request timeout not support in this queue class """ # use atomic range/remove using multi/exec pipe = self.server.pipeline() pipe.multi() pipe.zrange(self.key, 0, 0).zremrangebyrank(self.key, 0, 0) results, count = pipe.execute() if results: return self._decode_request(results[0]) class SpiderStack(Base): """Per-spider stack""" def __len__(self): """Return the length of the stack""" return self.server.llen(self.key) def push(self, request): """Push a request""" self.server.lpush(self.key, self._encode_request(request)) def pop(self, timeout=0): """Pop a request""" if timeout > 0: data = self.server.blpop(self.key, timeout) if isinstance(data, tuple): data = data[1] else: data = self.server.lpop(self.key) if data: return self._decode_request(data) __all__ = ['SpiderQueue', 'SpiderPriorityQueue', 'SpiderStack']
6.6. 源码分析参考:Scheduler
scheduler.py
此扩展是对scrapy中自带的scheduler的替代(在settings的SCHEDULER变量中指出),正是利用此扩展实现crawler的分布式调度。其利用的数据结构来自于queue中实现的数据结构。
scrapy-redis所实现的两种分布式:爬虫分布式以及item处理分布式就是由模块scheduler和模块pipelines实现。上述其它模块作为为二者辅助的功能模块
import importlib import six from scrapy.utils.misc import load_object from . import connection # TODO: add SCRAPY_JOB support. class Scheduler(object): """Redis-based scheduler""" def __init__(self, server, persist=False, flush_on_start=False, queue_key='%(spider)s:requests', queue_cls='scrapy_redis.queue.SpiderPriorityQueue', dupefilter_key='%(spider)s:dupefilter', dupefilter_cls='scrapy_redis.dupefilter.RFPDupeFilter', idle_before_close=0, serializer=None): """Initialize scheduler. Parameters ---------- server : Redis The redis server instance. persist : bool Whether to flush requests when closing. Default is False. flush_on_start : bool Whether to flush requests on start. Default is False. queue_key : str Requests queue key. queue_cls : str Importable path to the queue class. dupefilter_key : str Duplicates filter key. dupefilter_cls : str Importable path to the dupefilter class. idle_before_close : int Timeout before giving up. """ if idle_before_close < 0: raise TypeError("idle_before_close cannot be negative") self.server = server self.persist = persist self.flush_on_start = flush_on_start self.queue_key = queue_key self.queue_cls = queue_cls self.dupefilter_cls = dupefilter_cls self.dupefilter_key = dupefilter_key self.idle_before_close = idle_before_close self.serializer = serializer self.stats = None def __len__(self): return len(self.queue) @classmethod def from_settings(cls, settings): kwargs = { 'persist': settings.getbool('SCHEDULER_PERSIST'), 'flush_on_start': settings.getbool('SCHEDULER_FLUSH_ON_START'), 'idle_before_close': settings.getint('SCHEDULER_IDLE_BEFORE_CLOSE'), } # If these values are missing, it means we want to use the defaults. optional = { # TODO: Use custom prefixes for this settings to note that are # specific to scrapy-redis. 'queue_key': 'SCHEDULER_QUEUE_KEY', 'queue_cls': 'SCHEDULER_QUEUE_CLASS', 'dupefilter_key': 'SCHEDULER_DUPEFILTER_KEY', # We use the default setting name to keep compatibility. 'dupefilter_cls': 'DUPEFILTER_CLASS', 'serializer': 'SCHEDULER_SERIALIZER', } for name, setting_name in optional.items(): val = settings.get(setting_name) if val: kwargs[name] = val # Support serializer as a path to a module. if isinstance(kwargs.get('serializer'), six.string_types): kwargs['serializer'] = importlib.import_module(kwargs['serializer']) server = connection.from_settings(settings) # Ensure the connection is working. server.ping() return cls(server=server, **kwargs) @classmethod def from_crawler(cls, crawler): instance = cls.from_settings(crawler.settings) # FIXME: for now, stats are only supported from this constructor instance.stats = crawler.stats return instance def open(self, spider): self.spider = spider try: self.queue = load_object(self.queue_cls)( server=self.server, spider=spider, key=self.queue_key % {'spider': spider.name}, serializer=self.serializer, ) except TypeError as e: raise ValueError("Failed to instantiate queue class '%s': %s", self.queue_cls, e) try: self.df = load_object(self.dupefilter_cls)( server=self.server, key=self.dupefilter_key % {'spider': spider.name}, debug=spider.settings.getbool('DUPEFILTER_DEBUG'), ) except TypeError as e: raise ValueError("Failed to instantiate dupefilter class '%s': %s", self.dupefilter_cls, e) if self.flush_on_start: self.flush() # notice if there are requests already in the queue to resume the crawl if len(self.queue): spider.log("Resuming crawl (%d requests scheduled)" % len(self.queue)) def close(self, reason): if not self.persist: self.flush() def flush(self): self.df.clear() self.queue.clear() def enqueue_request(self, request): if not request.dont_filter and self.df.request_seen(request): self.df.log(request, self.spider) return False if self.stats: self.stats.inc_value('scheduler/enqueued/redis', spider=self.spider) self.queue.push(request) return True def next_request(self): block_pop_timeout = self.idle_before_close request = self.queue.pop(block_pop_timeout) if request and self.stats: self.stats.inc_value('scheduler/dequeued/redis', spider=self.spider) return request def has_pending_requests(self): return len(self) > 0
这个文件重写了scheduler类,用来代替scrapy.core.scheduler的原有调度器。其实对原有调度器的逻辑没有很大的改变,主要是使用了redis作为数据存储的媒介,以达到各个爬虫之间的统一调度。 scheduler负责调度各个spider的request请求,scheduler初始化时,通过settings文件读取queue和dupefilters的类型(一般就用上边默认的),配置queue和dupefilters使用的key(一般就是spider name加上queue或者dupefilters,这样对于同一种spider的不同实例,就会使用相同的数据块了)。每当一个request要被调度时,enqueue_request被调用,scheduler使用dupefilters来判断这个url是否重复,如果不重复,就添加到queue的容器中(先进先出,先进后出和优先级都可以,可以在settings中配置)。当调度完成时,next_request被调用,scheduler就通过queue容器的接口,取出一个request,把他发送给相应的spider,让spider进行爬取工作。
6.7. 源码分析参考:Spider
spider.py
设计的这个spider从redis中读取要爬的url,然后执行爬取,若爬取过程中返回更多的url,那么继续进行直至所有的request完成。之后继续从redis中读取url,循环这个过程。
分析:在这个spider中通过connect signals.spider_idle信号实现对crawler状态的监视。当idle时,返回新的make_requests_from_url(url)给引擎,进而交给调度器调度。
from scrapy import signals from scrapy.exceptions import DontCloseSpider from scrapy.spiders import Spider, CrawlSpider from . import connection # Default batch size matches default concurrent requests setting. DEFAULT_START_URLS_BATCH_SIZE = 16 DEFAULT_START_URLS_KEY = '%(name)s:start_urls' class RedisMixin(object): """Mixin class to implement reading urls from a redis queue.""" # Per spider redis key, default to DEFAULT_START_URLS_KEY. redis_key = None # Fetch this amount of start urls when idle. Default to DEFAULT_START_URLS_BATCH_SIZE. redis_batch_size = None # Redis client instance. server = None def start_requests(self): """Returns a batch of start requests from redis.""" return self.next_requests() def setup_redis(self, crawler=None): """Setup redis connection and idle signal. This should be called after the spider has set its crawler object. """ if self.server is not None: return if crawler is None: # We allow optional crawler argument to keep backwards # compatibility. # XXX: Raise a deprecation warning. crawler = getattr(self, 'crawler', None) if crawler is None: raise ValueError("crawler is required") settings = crawler.settings if self.redis_key is None: self.redis_key = settings.get( 'REDIS_START_URLS_KEY', DEFAULT_START_URLS_KEY, ) self.redis_key = self.redis_key % {'name': self.name} if not self.redis_key.strip(): raise ValueError("redis_key must not be empty") if self.redis_batch_size is None: self.redis_batch_size = settings.getint( 'REDIS_START_URLS_BATCH_SIZE', DEFAULT_START_URLS_BATCH_SIZE, ) try: self.redis_batch_size = int(self.redis_batch_size) except (TypeError, ValueError): raise ValueError("redis_batch_size must be an integer") self.logger.info("Reading start URLs from redis key '%(redis_key)s' " "(batch size: %(redis_batch_size)s)", self.__dict__) self.server = connection.from_settings(crawler.settings) # The idle signal is called when the spider has no requests left, # that's when we will schedule new requests from redis queue crawler.signals.connect(self.spider_idle, signal=signals.spider_idle) def next_requests(self): """Returns a request to be scheduled or none.""" use_set = self.settings.getbool('REDIS_START_URLS_AS_SET') fetch_one = self.server.spop if use_set else self.server.lpop # XXX: Do we need to use a timeout here? found = 0 while found < self.redis_batch_size: data = fetch_one(self.redis_key) if not data: # Queue empty. break req = self.make_request_from_data(data) if req: yield req found += 1 else: self.logger.debug("Request not made from data: %r", data) if found: self.logger.debug("Read %s requests from '%s'", found, self.redis_key) def make_request_from_data(self, data): # By default, data is an URL. if '://' in data: return self.make_requests_from_url(data) else: self.logger.error("Unexpected URL from '%s': %r", self.redis_key, data) def schedule_next_requests(self): """Schedules a request if available""" for req in self.next_requests(): self.crawler.engine.crawl(req, spider=self) def spider_idle(self): """Schedules a request if available, otherwise waits.""" # XXX: Handle a sentinel to close the spider. self.schedule_next_requests() raise DontCloseSpider class RedisSpider(RedisMixin, Spider): """Spider that reads urls from redis queue when idle.""" @classmethod def from_crawler(self, crawler, *args, **kwargs): obj = super(RedisSpider, self).from_crawler(crawler, *args, **kwargs) obj.setup_redis(crawler) return obj class RedisCrawlSpider(RedisMixin, CrawlSpider): """Spider that reads urls from redis queue when idle.""" @classmethod def from_crawler(self, crawler, *args, **kwargs): obj = super(RedisCrawlSpider, self).from_crawler(crawler, *args, **kwargs) obj.setup_redis(crawler) return obj
spider的改动也不是很大,主要是通过connect接口,给spider绑定了spider_idle信号,spider初始化时,通过setup_redis函数初始化好和redis的连接,之后通过next_requests函数从redis中取出strat url,使用的key是settings中REDIS_START_URLS_AS_SET定义的(注意了这里的初始化url池和我们上边的queue的url池不是一个东西,queue的池是用于调度的,初始化url池是存放入口url的,他们都存在redis中,但是使用不同的key来区分,就当成是不同的表吧),spider使用少量的start url,可以发展出很多新的url,这些url会进入scheduler进行判重和调度。直到spider跑到调度池内没有url的时候,会触发spider_idle信号,从而触发spider的next_requests函数,再次从redis的start url池中读取一些url。
总结
最后总结一下scrapy-redis的总体思路:这个工程通过重写scheduler和spider类,实现了调度、spider启动和redis的交互。实现新的dupefilter和queue类,达到了判重和调度容器和redis的交互,因为每个主机上的爬虫进程都访问同一个redis数据库,所以调度和判重都统一进行统一管理,达到了分布式爬虫的目的。 当spider被初始化时,同时会初始化一个对应的scheduler对象,这个调度器对象通过读取settings,配置好自己的调度容器queue和判重工具dupefilter。每当一个spider产出一个request的时候,scrapy内核会把这个reuqest递交给这个spider对应的scheduler对象进行调度,scheduler对象通过访问redis对request进行判重,如果不重复就把他添加进redis中的调度池。当调度条件满足时,scheduler对象就从redis的调度池中取出一个request发送给spider,让他爬取。当spider爬取的所有暂时可用url之后,scheduler发现这个spider对应的redis的调度池空了,于是触发信号spider_idle,spider收到这个信号之后,直接连接redis读取strart url池,拿去新的一批url入口,然后再次重复上边的工作。
7. Scrapy-redis实战
从零搭建Redis-Scrapy分布式爬虫
Scrapy-Redis分布式策略:
假设有三台电脑:Windows 10、Ubuntu 16.04、Windows 10,任意一台电脑都可以作为 Master端 或 Slaver端,比如:
l Master端(核心服务器) :使用 Windows 10,搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储
l Slaver端(爬虫程序执行端) :使用 Ubuntu 16.04、Windows 10,负责执行爬虫程序,运行过程中提交新的Request给Master

- 首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
- Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
一、安装Redis
安装Redis:https://github.com/MSOpenTech/redis
安装完成后,拷贝一份Redis安装目录下的redis.conf到任意目录,建议保存到:/etc/redis/redis.conf (Windows系统可以无需变动)
二、修改配置文件 redis.conf
打开你的redis.conf配置文件,示例:
l 非Windows系统: sudo vi /etc/redis/redis.conf
l Windows系统:C:IntelRedisconf
edis.conf
- Master端redis.conf里注释
bind 127.0.0.1,Slave端才能远程连接到Master端的Redis数据库。

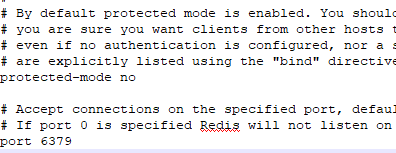
- 在redis3.2之后,redis增加了protected-mode,在这个模式下,即使注释掉了bind 127.0.0.1,再访问redis的时候还是报错,如下:

有两种解决方法:一种是设置protected-mode no,如下:
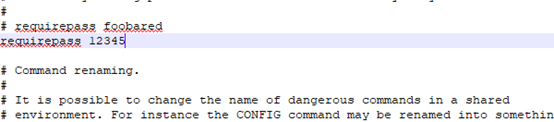
另一种是设置登录Ridis的密码,如下:
三、测试Slave端远程连接Master端
测试中,Master端Windows 10 的IP地址为:192.168.199.108
- Master端按指定配置文件启动
redis-server,示例:
l 非Windows系统:sudo redis-server /etc/redis/redis/conf
l Windows系统:命令提示符(管理员)模式下执行 redis-server.exe redis.windows.conf读取默认配置即可。
- Master端启动本地
redis-cli:
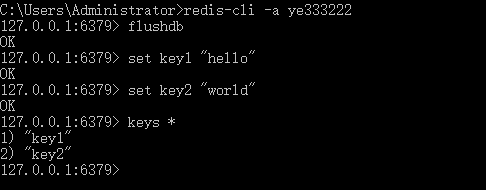
- slave端启动
redis-cli -h 192.168.0.113 –a ye333222,-h参数表示连接到指定主机的redis数据库, -a参数表示需要密码
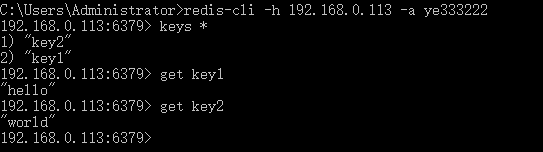
注意:Slave端无需启动redis-server,Master端启动即可。只要 Slave 端读取到了 Master 端的 Redis 数据库,则表示能够连接成功,可以实施分布式。
四、Redis数据库桌面管理工具
这里推荐 Redis Desktop Manager,支持 Windows、Mac OS X、Linux 等平台:
下载地址:https://redisdesktop.com/download


7.1. 源码自带项目说明
使用scrapy-redis的example来修改
先从github上拿到scrapy-redis的示例,然后将里面的example-project目录移到指定的地址:
# clone github scrapy-redis源码文件
git clone https://github.com/rolando/scrapy-redis.git
# 直接拿官方的项目范例,改名为自己的项目用(针对懒癌患者)
mv scrapy-redis/example-project ~/scrapyredis-project
我们clone到的 scrapy-redis 源码中有自带一个example-project项目,这个项目包含3个spider,分别是dmoz, myspider_redis,mycrawler_redis。
一、dmoz (class DmozSpider(CrawlSpider))
这个爬虫继承的是CrawlSpider,它是用来说明Redis的持续性,当我们第一次运行dmoz爬虫,然后Ctrl + C停掉之后,再运行dmoz爬虫,之前的爬取记录是保留在Redis里的。
分析起来,其实这就是一个 scrapy-redis 版 CrawlSpider 类,需要设置Rule规则,以及callback不能写parse()方法。
# 执行方式:scrapy crawl dmoz from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class DmozSpider(CrawlSpider): """Follow categories and extract links.""" name = 'dmoz' allowed_domains = [' dmoztools.net'] start_urls = [' http://dmoztools.net/'] rules = [ Rule(LinkExtractor( restrict_css=('.top-cat', '.sub-cat', '.cat-item') ), callback='parse_directory', follow=True), ] def parse_directory(self, response): for div in response.css('.title-and-desc'): yield { 'name': div.css('.site-title::text').extract_first(), 'description': div.css('.site-descr::text').extract_first().strip(), 'link': div.css('a::attr(href)').extract_first(), }
二、myspider_redis (class MySpider(RedisSpider))
这个爬虫继承了RedisSpider, 它能够支持分布式的抓取,采用的是basic spider,需要写parse函数。
其次就是不再有start_urls了,取而代之的是redis_key,scrapy-redis将key从Redis里pop出来,成为请求的url地址。
from scrapy_redis.spiders import RedisSpider class MySpider(RedisSpider): """Spider that reads urls from redis queue (myspider:start_urls).""" name = 'myspider_redis' # 注意redis-key的格式: redis_key = 'myspider:start_urls' # 可选:等效于allowd_domains(),__init__方法按规定格式写,使用时只需要修改super()里的类名参数即可 def __init__(self, *args, **kwargs): # Dynamically define the allowed domains list. domain = kwargs.pop('domain', '') self.allowed_domains = filter(None, domain.split(',')) # 修改这里的类名为当前类名 super(MySpider, self).__init__(*args, **kwargs) def parse(self, response): return { 'name': response.css('title::text').extract_first(), 'url': response.url, }
注意:
RedisSpider类 不需要写allowd_domains和start_urls:
- scrapy-redis将从在构造方法
__init__()里动态定义爬虫爬取域范围,也可以选择直接写allowd_domains。 - 必须指定redis_key,即启动爬虫的命令,参考格式:redis_key = 'myspider:start_urls'
- 根据指定的格式,start_urls将在 Master端的 redis-cli 里 lpush 到 Redis数据库里,RedisSpider 将在数据库里获取start_urls。
执行方式:
- 通过runspider方法执行爬虫的py文件(也可以分次执行多条),爬虫(们)将处于等待准备状态:
scrapy runspider myspider_redis.py - 在Master端的redis-cli输入push指令,参考格式:
$redis > lpush myspider:start_urls http://dmoztools.net/ - Slaver端爬虫获取到请求,开始爬取。
三、mycrawler_redis (class MyCrawler(RedisCrawlSpider))
这个RedisCrawlSpider类爬虫继承了RedisCrawlSpider,能够支持分布式的抓取。因为采用的是crawlSpider,所以需要遵守Rule规则,以及callback不能写parse()方法。
同样也不再有start_urls了,取而代之的是redis_key,scrapy-redis将key从Redis里pop出来,成为请求的url地址。
from scrapy.spiders import Rule from scrapy.linkextractors import LinkExtractor from scrapy_redis.spiders import RedisCrawlSpider class MyCrawler(RedisCrawlSpider): """Spider that reads urls from redis queue (myspider:start_urls).""" name = 'mycrawler_redis' redis_key = 'mycrawler:start_urls' rules = ( # follow all links Rule(LinkExtractor(), callback='parse_page', follow=True), ) # __init__方法必须按规定写,使用时只需要修改super()里的类名参数即可 def __init__(self, *args, **kwargs): # Dynamically define the allowed domains list. domain = kwargs.pop('domain', '') self.allowed_domains = filter(None, domain.split(',')) # 修改这里的类名为当前类名 super(MyCrawler, self).__init__(*args, **kwargs) def parse_page(self, response): return { 'name': response.css('title::text').extract_first(), 'url': response.url, }
注意:
同样的,RedisCrawlSpider类不需要写allowd_domains和start_urls:
- scrapy-redis将从在构造方法
__init__()里动态定义爬虫爬取域范围,也可以选择直接写allowd_domains。 - 必须指定redis_key,即启动爬虫的命令,参考格式:
redis_key = 'mycrawl:start_urls' - 根据指定的格式,
start_urls将在 Master端的 redis-cli 里 lpush 到 Redis数据库里,RedisSpider 将在数据库里获取start_urls。
执行方式:
- 通过runspider方法执行爬虫的py文件(也可以分次执行多条),爬虫(们)将处于等待准备状态:
scrapy runspider mycrawler_redis.py - 在Master端的redis-cli输入push指令,参考格式:
$redis > lpush mycrawler:start_urls http://dmoztools.net/ - 爬虫获取url,开始执行。
总结:
- 如果只是用到Redis的去重和保存功能,就选第一种;
- 如果要写分布式,则根据情况,选择第二种、第三种;
- 通常情况下,会选择用第三种方式编写深度聚焦爬虫。
- Redis数据库的使用
- RedisSpider类的使用
【重点总结】
- Redis数据库的使用
- RedisSpider类的使用