out变量
有一定C#编程经历的园友一定没少写如下这样的代码:
int speed; if (int.TryParse(speedStr, out speed)) speed*=10;
注释:int.TryParse 与 int.Parse 的区别
int.Parse()是一种类容转换;表示将数字内容的字符串转为int类型。
1.如果字符串为空,则抛出ArgumentNullException异常;
2.如果字符串内容不是数字,则抛出FormatException异常;
3.如果字符串内容所表示数字超出int类型可表示的范围,则抛出OverflowException异常;
int.TryParse 与 int.Parse 又较为类似,但它不会产生异常,转换成功返回 true,转换失败返回 false。最后一个参数为输出值。
为了增加程序的健壮性,在进行类型转换时使用TryXXX方法是很好的实践。
但由于这样的写法实在太显啰嗦,所以常常我们认为转换一定能正确进行时就会偷懒直接用Parse了事,当然这样就给程序留下了出现异常的隐患。
现在有了out变量支持,可以以如下方式编写安全的转换:
if (int.TryParse(speedStr, out int speed)) speed*=10;
虽然if还在,但少了孤零零的变量声明,代码看起来已经很美观了,终于可以快乐的编写健壮的代码了。
out变量也支持类型推导,把out后面的int换成var也是完全可以了。另外speed变量的作用域不限于if内,在if外也是可以使用的。
除了Parse类方法,许多Get类方法也从中受益,比如从Dictionary中按key取值:
if (!dstDic.TryGetValue(fileName, out var dstFile)) { ... }
而且自定义的out参数也可以享受这样的便利。
值元组
值元组是博主认为C# 7带来的比较重要的改进之一。因为之前Tuple虽好,但写起来实在是太罗嗦。而值元组的出现使C#在元组的使用方面有这么一点点接近Python(虽然在类型方面灵活性还差了这么一丢丢)。
值元组的类型ValueTuple在.NET Framework 4.7中首发,博主一度认为只有基于.NET Framework 4.7的项目才能享受值元组的便利,甚至为此感到遗憾(目前工作中大部分项目都是.NET Framework 4.5/4.6或.NETCore1.1/2.0)后来看到官方文档才知道微软单独提供了一份System.ValueTuple的程序集供没有原生ValueTuple类型的框架使用。
下面将通过与传统元组对比的方式,让各位领略值元组的简练。
首先在元组类型对象的创建方面,ValueTuple看起来更简洁。
// 创建Tuple的两种方式 var tuple1 = Tuple.Create(1, "小明"); var tuple2 = new Tuple<int, string>(2, "小明"); // 创建ValueTuple var valueTuple1 = (1, "小明");
而在使用方面,Tuple使用以Item1,Item2...为名的属性来访问相应位置的对象。ValueTuple也支持同样的方式:
// Tuple Console.WriteLine($"{tuple1.Item1}-{tuple1.Item2}"); // ValueTuple Console.WriteLine($"{valueTuple1.Item1}-{valueTuple1.Item2}");
当然ValueTuple之所以好用,就是因为它有更方便的成员的访问方式,可以在构造一个ValueTuple时指定相应成员的访问名称:
var valueTuple1 = (Id: 1, Name: "小明"); Console.WriteLine($"{valueTuple1.Id}-{valueTuple1.Name}");
在C#7.1中,如果使用变量构造ValueTuple会自动推断元组成员的名称,如上面的代码改造一下:
// C#7.1有效 var Id = 1; var Name = "小明"; var valueTuple1 = (Id, Name); Console.WriteLine($"{valueTuple1.Id}-{valueTuple1.Name}");
如果不在构造时指定访问名称,也可以在声明变量时使用下面这样的类型:
(int Id, string Name) vt = (1, "小明"); Console.WriteLine($"{vt.Id}-{vt.Name}");
(int Id, string Name)这样的类型声明是C#语法为了对值元组进行支持带来的最大的改进。
’在之前,如果不使用var类型推断则只能使用Tuple<int,string>这样冗长的类型来进行声明(值元组也支持ValueTuple<int,string>这样的类型声明,但由于有了新的语法,这种方式基本没有人用,(int,string)就是ValueTuple<int,string>等价的语法糖)。
另外一个语法级的值元组支持就是元组析构(不得不说这种翻译很容易混淆),如:
(var id, var name) = (1, "小明"); // 也可以写成 var (id,name) = (1, "小明"); Console.WriteLine($"{id}-{name}");
可以在元组析构时,使用_来表示放弃(可能你已经在模式匹配、lambda表达式创建等地方见到过_符号的踪迹),如上面的例子,我们只需要值元组中的一部分:
(var id, _) = (1, "小明"); // 等效于 var (id, _) = (1, "小明"); Console.WriteLine($"{id}");
C# 7还给自定义类型也带来扩展类似元组析构功能的方法,下面的例子是来自MSDN(改了一丢丢)
public class Point { public double X { get; set; } public double Y { get; set; } public void Deconstruct(out double x, out double y) { x = this.X; y = this.Y; } } // 析构 var p = new Point(){X=1,Y = 2}; var (x1, y1) = p;
实现的关键就是自定义Deconstruct函数,由例子可见x1与out参数x没有关系,析构过程定义的变量可以取任意名字。
基本上值元组的用法就是上面所述,值得多说的一点,当值元组应用在方法中时,可以给返回多个值的操作提供极大的遍历:
private static (int, string) NewStudent() { return (1, "小明"); } // 使用 (int Id, string Name) = NewStudent(); Console.WriteLine($"{Id}-{Name}");
或者
private static (int Id, string Name) NewStudent() { return (1, "小明"); } var stu = NewStudent(); Console.WriteLine($"{stu.Id}-{stu.Name}");
就是这么灵活。好了,值元组部分就到这里。
本地函数
本地函数是一种嵌套在函数内部的函数。在本地函数出现之前要想在函数内实现一个可以被重复调用的函数一般只能选择lambda表达式。
下面展示一个博主写代码时遇到的例子,也是在写这段代码时博主才知道了本地函数的存在。
先来看一段代码,代码中使用TaskCompletionSource将一段调用喷码机的EAP异步代码包装为async/await代码:
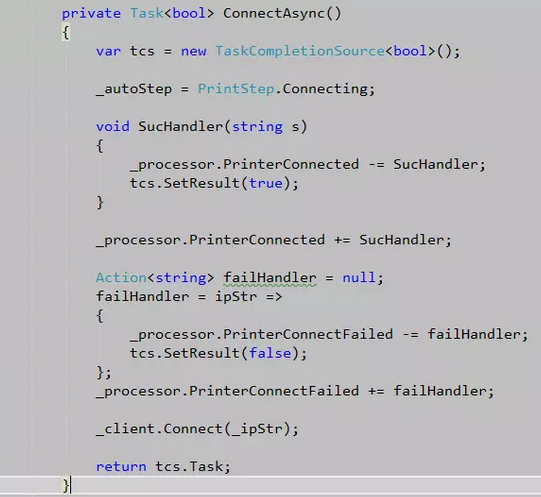
值得注意的是我们需要在异步处理结束前取消事件的注册,不然当这个函数被再次调用时TaskCompletionSource会抛出System.InvalidOperationException,异常消息为:“在已经完成任务后,尝试将任务转换为最终状态。”。
解决办法就是在事件处理函数中取消事件订阅,在本地函数出现之前做法如上图的代码。
先声明一下一个lambda表达式,然后去编写lambda表达式的实现,在实现中取消对lambda的订阅。一定要把声明和赋值分开,不然无法取消订阅。
这种实现是完全没有问题的。那博主是怎么发现本地函数这个特性的呢。这要感谢大神级插件,站在宇宙第一IDE肩膀上的宇宙第一插件 - ReSharper。
仔细观察在failHandler这个表示lambda表达式的变量下有一条绿色的下划线,这是ReSharper在提示有更好的写法
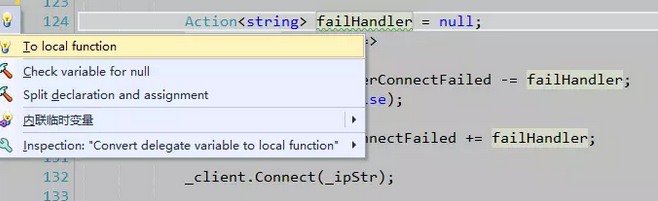
楼主第一次看到也是比较愣。“local function”是什么东西。试着点击后发现代码被改写为下面的样子:
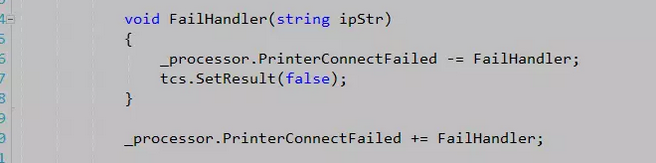
在ConnectAsync函数中又出现了一个函数。然后不免一番搜索后发现这是C# 7的一个新特性 - 本地函数。而这段代码又正好是本地函数一个比较好的使用例子。
模式匹配
C# 6中出现的异常过滤器有一点点模式匹配的味道。
C# 7全面引入的模式匹配,表现在对switch case和is进行了扩展,从而让C#对类型的处理更加优雅。首先来看一下对switch case的扩展,下面这段方法依然是来自最近完成的一个项目中。
这个方法是一个访问WebAPI服务获取数据的本地代理的一部分,受到Jeffcky这篇博文的启发,决定尝试使用Polly库完成超时重试等功能,同时使用Polly优雅的封装异常,从而使调用方可以安心的去调用。
var oc = policyRet.Outcome; if (oc == OutcomeType.Successful) { resultStr = policyRet.Result; } else { switch (policyRet.FinalException) { case WebException _: case HttpRequestException _: resultStatus = ResultStatus.NetFailed; break; case HttpStatusErrorException statusEx when statusEx.HttpStatus == 404: resultStatus = ResultStatus.PageNotFound; break; case HttpStatusErrorException statusEx when statusEx.HttpStatus == 500: resultStatus = ResultStatus.ServerError; break; case UriFormatException _: resultStatus = ResultStatus.UriError; break; case TaskCanceledException _: resultStatus = ResultStatus.TimeOut; break; case null: default: resultStatus = ResultStatus.Unknown; resultStr = $"{policyRet.FinalException?.GetType()}:{policyRet.FinalException?.Message}"; break; } }
oc对象是Polly的执行返回结果,代码中使用模式匹配加持过的switch来进行异常类型的处理。
传统的switch不能处理除了数值类型和字符串以外的其它类型的对象。而模式匹配的出现使switch成为一个可以取代if ... else if ...的存在。
现在case中可以对switch内传入的对象进行类型判断并进入相应的分支,相当于以前这样的判断语句:
if (obj is Type) { ... }
现在写成swtich case的形式,代码看起来更加简洁优雅。同时case分支中还新支持使用when关键字对类型匹配的对象进行进一步过滤。如上面代码中第三与第四条case。
对于不需要进一步对象属性过滤的类型判断,可以直接使用_作为占位符,_占位符这个语法在lambda表达式等中出现过。
甚至case语句还可以直接对null进行判断,我们可以放心的把可能为空的对象直接传入switch中。(上面代码由于default分支的存在,case null:是可以省略的,这样写是为了展示null的操作)
模式匹配的另一个方面是体现在对is关键字的扩展,之前版本的C#将一个泛化的类型的对象转为具体类型的对象免不了写以下这样的代码(伪代码):
if (obj is TypeA) { (TypeA)obj; //或 var objA = obj as TypeA; }
现在可以把类型判断与转换合二为一了:
if (obj is TypeA objA) Console.WriteLine(objA.Name);
返回结果引用
说起引用ref,这可能是C#出现最早,但博主使用频率最低的一个特性。由于这些年写过的代码很少是性能敏感型的,很少有意的去注意使用一些ref参数。
之前ref只适用于方法的参数,现在7.0版本的C#将ref拓展到方法的返回值。
同样博主目前没有在任何代码中用过这个特性,下面所写的内容也是在学习这个特性的过程中才了解到。
返回结果引用也是为了在一些性能敏感的场景,还是以一个例子来给读者一个初印象:
public class Sample { long[] _bigArr = { 11, 22, 33, 44, 55 }; private ref long ReturnRef(int idx) { if (idx >= _bigArr.Length) throw new ArgumentOutOfRangeException(); return ref _bigArr[idx]; } private void TestReturnRef() { ref var refVal = ref ReturnRef(2); } }
例子中ReturnRef就是返回引用的函数,包括调用在内的整段代码中ref关键字一共出现了4次。前两个出现在方法声明和return语句中。后两个分别是引用变量的声明和表示以引用方式调用函数。它们一个都不能少。
refVal作为一个引用变量,必须在声明的时候直接赋值,如上面代码中那样,否则是不能通过编译的。refVal这个引用变量和C++中的引用非常类似,对其赋值会修改其所指向的位置所存储的值,如:
ref var refVal = ref ReturnRef(2); refVal = 100; Console.WriteLine(_bigArr[2]);
这段代码输出100,即修改后的值。
如果调用语句写成如下这样:
private void TestReturnNoRef() { var val = ReturnRef(2); }
这样也可以执行,但这无异于调用一个返回普通值的方法,val只是一个普通的本地变量,修改它不会导致引用位置的值被修改:
ref varval = ref ReturnRef(2); val = 100; Console.WriteLine(_bigArr[2]);
这段代码将输出33。
MSDN中给出了返回引用的函数的三种使用限制,其中只有第二条,即“不能将引用返回给其生存期不超出方法执行的变量。
(英文原文:You cannot return a ref to a variable whose lifetime does not extend beyond the execution of the method. ps.翻译有问题...)”需要注意,其余两条会引起编译失败可以不提。那这最难理解的第二条是什么意思的呢,还是以上面的例子来描述,我们返回的引用来自类成员变量,其生命周期大于函数的声明周期,这是合理的,如果_bigArr是在ReturnRef方法内部声明的本地变量,虽然不会报错,但并没有实际的使用价值,从而被列入使用限制中。
返回引用的方法这个新特性就介绍到此。更多引用方面的增强见C#7.2部分。
一些其它小改进
表达式体可应用于更多场景
介绍了可以使用表达式体(expression-bodied)的一些场景,如方法实现,只读属性的实现。
C#7中扩展了表达式体可应用的场景:
-
构造函数及析构函数
-
属性和索引器的get/set访问器
如:
private Dictionary<int,string> _students = new Dictionary<int, string>(); public string this[int id] { get => _students[id]; set => _students[id] = value ?? "no name"; }
新的异步返回类型 - ValueTask
C#7.0之前异步方法支持Task、Task<T>和void三种返回类型,而7.0开始语言层面支持一个新增的ValueTask<T>(需要自行添加Nuget包才能使用)作为异步方法的返回类型。ValueTask<T>是值类型,在一些需要频繁创建Task的场景中比引用类型的Task<T>性能更好。如:
public ValueTask<int> GetConstVal() { return new ValueTask<int>(100); }
相信一个经常使用异步方法的程序猿肯定常遇到需要像上面这样返回一个值的异步方法。MSDN给出的一个例子是包装获取缓存值的异步方法。
这时用ValueTask<T>有可能获得更好的性能。
throw表达式
C#中throw作为作为最早一批语句出现,用于抛出异常。而C#7中throw多了一个孪生兄弟,作为表达式的throw。
这样throw就可用于像是之前介绍的表达式体中。值得注意是像是上小节介绍的将表达式体用于构造函数,属性初始化等场景中,如果用throw表达式抛出异常,则直接会导致对象构造失败,最坏情况下会导致全局未处理异常,而使程序意外退出。
一个合理的使用方式如下,改自上面表达式体使用的示例:
public string this[int id] { get => _students[id]; set => _students[id] = value ?? throw new Exception("name can't be null"); }
数值字面量改进
这个特性包括两部分,一是使用_作为数字间的分隔符,以使数值可读性更好。且可以同时应用于整数与浮点数。如:
var num1 = 123_456_789L; var num2 = 0.123_456_789D;
另一部分,就是C#终于开始支持二进制字面量,使用0b开头表示这是一个二进制数值。
同时也支持_作为数字间的分隔符。在7.0中不允许0b与数字间有_,C#7.2开始则接受0b与最高位数字间有_(十进制或十六进制数字字面量也可以以_开头)。
var num1 = 0b0001_0011; // C#7.0 var num2 = 0b_0001_0011; // C#7.2 var num5 = _123_456; // C#7.2 var num3 = 0x_00AA_00BB; // C#7.2
C# 7.1
最近一两年来,C#的步伐明显加快,C#第一次出现了0.1这样的小版本号。可能和新的编译器的出现及开源有关系,另外这也是第一次实现VS与语言版本的分开,之前版本的VS虽然可以兼容不同版本的.NET Framework,但都只对应特定版本的C#(编译器),从现在开始可以独立设置项目所使用C#语言版本。
7.x版本新增的特性与7.0版本相关的部分在上文已经一并介绍了。这里把其它一些改进也列出来。
首先介绍下如何去设置VS中项目所使用的语言版本。如下图,在生成选项卡中点高级,弹出的对话框中,通过语言版本的下拉菜单可以选择语言版本。
默认项是“C#最新主要版本”,主要版本即对应7.0这种大版本。如果选择色“C#最新的次要版本”则表示使用当前VS支持的最新语言版本,对于博主使用的VS15.4.3来说即7.1。
另外这个设置是配置敏感的,也就是说对于Debug和Release要进行同样的设置,否则在进行不同的配置的生成时会出现问题。
异步入口方法
在之前版本的C#中入口方法即Main方法不能是异步的,所以在某些需要在Main中调用异步方法的情况下就不得不使用Wait()或.GetAwaiter().GetResult()来将异步方法转为同步调用。
而在某些情况下这可能导致死锁。(控制台程序可以直接Wait异步方法而不会死锁)
所以新版本带来了支持异步的Main方法,这样再也不用怕异步向上传播了。
// 无返回值 static async Task Main(string[] args) { await DoSomeTask(); } // 返回int static async Task<int> Main(string[] args) { return await GetTaskResult(); }
增强的default
如果你常需要写支持泛型的代码,肯定对default这样的用法不陌生:
public T GetSomething<T>() { return default(T); }
C#7.1开始极大的简化了default的使用并扩展了default的由于范围。
首先现在default可以对后面的类型自动自行对推断,上面的返回语句可以直接写为return default。
同样下面的简化也可以:
(int, string) student = default((int,string)); // 简化为 (int, string) student = default;
在扩展方面,现在可以使用default初始化参数默认值,如:
public NewStudent(int id, string name = default) { // ... }
而在之前,声明string类型的默认参数只能用""。在调用方法时,可以传入default表示相应的参数使用默认值(参数是否声明为可选参数没有关系)。
private static (int Id, string Name) NewStudent(int id, string name) { return (id, name); } // 调用 NewStudent(1, default);
对于返回默认值的场景也可以直接简单的使用default。
private (int Id, string Name) NewStudent(int id, string name) { if (!string.IsNullOrEmpty(name)) return (id, name); return default; }
C# 7.2
值类型的引用增强
in参数
之前版本的C#对于通过引用传递值类型的参数提供了ref和out两种方式,各位应该也都或多或少的用过,而且也肯定知道如果不使用任何修饰来传入值类型参数则会导致复制从而产生性能开销。
C#7.2开始新提供了in关键字来通过引用的方式进行值类型参数的传递。in与ref有一定的相似性,有一定限制,同时也更灵活。
in类型的参数最大的特点(一定意义上也是限制)就是不能在方法内修改in参数的值,也就是说其在方法作用域内是只读的,这也是in参数最大特点所在。编译器可以保证in参数的只读,对于in参数的赋值或对于in参数(结构体)成员的赋值都是无法通过编译的。
in最大的作用是传递比较大的结构体时可以减少内存开支,相对而言比如传递int时用不用in参数都没有更多益处,因为int所占的空间与引用(地址)所占的空间差不多。另外in也可用于引用类型参数,但同样没有太多益处。
in类型参数相对ref另一个大不同就是只需要在形参中使用in标明参数类型,在传入实参时不需要再次添加in关键字。
in类型的参数支持默认值,支持实参为常量或字面量。
in的出现,加上之前的ref与out,使C#在通过引用传入传出值类型方面功能就很完备了。
与ref和out一样也不能通过in来区分函数的不同重载。
ref readonly返回
当希望使用(只读)引用方式来提供一个值访问的时候可以使用7.2中新增的ref readonly变量。这个特性解释起来很简单,直接照搬MSDN的示例代码:
private static Point3D origin = new Point3D(); public static ref readonly Point3D Origin => ref origin;
代码中Point3D是一个结构体,Origin就是结构体实例的一个只读引用。使用这个引用有两种方式:
var originValue = Point3D.Origin; ref readonly var originReference = ref Point3D.Origin;
第一行代码通过拷贝方式生产了一个Origin的副本。而第二行代码传递的为引用,这也是我们希望ref readonly所发挥的作用。同时,注意对originReference的访问都是只读的。
readonly struct类型
新增的只读的struct可以保证struct中的每个成员都不可修改,所以只读的struct很适合与上面介绍的in参数或ref readonly返回共同使用。
由于只读struct的特性,编译器不用再做其它工作来保证struct的成员不可变。同时当使用struct的成员时,编译器会自动采用in参数的处理方式从而节省复制开销。
只读struct只需要struct声明的最前面加上readonly关键字即可。
ref struct类型
新增的ref struct类型用于定义保证在栈空间内分配的值类型,这就意味着这中类型不能被装箱,即不能作为class的成员等。
ref struct类型的一个作用就是声明ReadOnlySpan<T>这个类型,ref struct的特性保证了ReadOnlySpan<T>内索引操作的句对安全。
关于Span<T>系类型推荐《.NET Core中使用ref和Span<T>提高程序性能》这篇文章
灵活的命名参数位置
C# 4.0增加的命名参数有一个限制,就是当普通参数与命名参数混合使用时,名命参数必须位于最后。
C#7.2中这个限制被放开,命名参数可以位于任意位置,但要求其它位置的参数必须在恰当的顺位上。
继续借用MSDN的示例,来看看对于C#7.2什么样的调用是合法什么是不合法。
// 被调用的函数 static void PrintOrderDetails(string sellerName, int orderNum, string productName) { // 省略... } // C#7.2之前,混合使用时,只允许命名参数放在最后 PrintOrderDetails("Gift Shop", 31, productName: "Red Mug"); // C#7.2,混合使用,命名参数可以在任意位置,普通参数需位于恰当的顺位 PrintOrderDetails(sellerName: "Gift Shop", 31, productName: "Red Mug"); // 31对应形参orderNum // C#7.2非法示例 // PrintOrderDetails(productName: "Red Mug", 31, "Gift Shop"); // 31, "Gift Shop"无正确对应的形参,编译不通过
Private Protected修饰符
新增的private pretected修饰符表示被修饰的成员可以在下范围内访问:
-
在其所在的类内部
-
与其所在类位于同一个程序集的所在类的子类内部
值得注意的就是区分之前存在的protected internal修饰符,后者表示访问范围在当前程序集内部所有类以及所在类的子类(主要指那些与所在类不在同一个程序集的子类)。这么来看它们的区别还是很大的。