本文主要是对神经网络模型的基本工作原理做一下简明扼要的阐述,便于快速复习与回顾之需。
背景
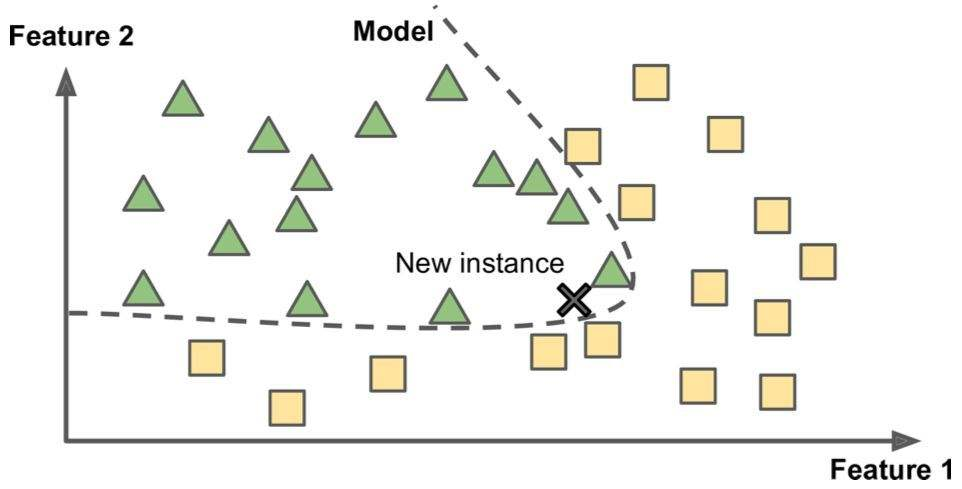
神经网络模型最主要的功能之一是完成分类任务,这里为了引入工作原理,先设置一个任务背景:将下面的这幅图中的三角形和正方形分开,也就是一个典型的二维数据(两个特征)的二分类问题。我们用肉眼能很轻松的得出结论:无法用一条直线将这两种图形完全分开。
组成结构
神经元
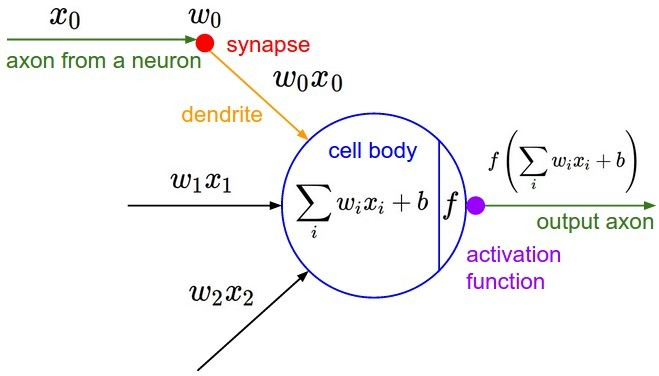
如上图是神经网络中一个典型的神经元设计,它完全仿照人类大脑中神经元之间传递数据的模式设计。大脑中,神经元通过若干树突(dendrite)的突触(synapse),接受其他神经元的轴突(axon)或树突传递来的消息,而后经过处理再由轴突输出。
在这里,诸$x_i$是其他神经元的轴突传来的消息,诸$w_i$是突触对消息的影响,诸$w_ix_i$则是神经元树突上传递的消息。这些消息经由神经元整合后$(z(\vec x; \vec w, b) = \sum_i w_ix_i + b)$再激活输出$(f(z))$。这里,整合的过程是线性加权的过程,各输入特征$x_i$之间没有相互作用。激活函数(active function)一般来说则是非线性的,各输入特征$x_i$在此处相互作用。
单层感知器
神经网络最简单的结构就是单输出的单层感知机,单层感知机只有输入层和输出层,分别代表了神经感受器和神经中枢。下图是一个只有2个输入单元和1个输出单元的简单单层感知机。图中$x1、x2$代表神经网络的输入神经元受到的刺激,$w1、w2$代表输入神经元和输出神经元间连接的紧密程度,$b$代表输出神经元的兴奋阈值,$y$为输出神经元的输出。我们使用该单层感知机划出一条线将*面分割开,如图所示:
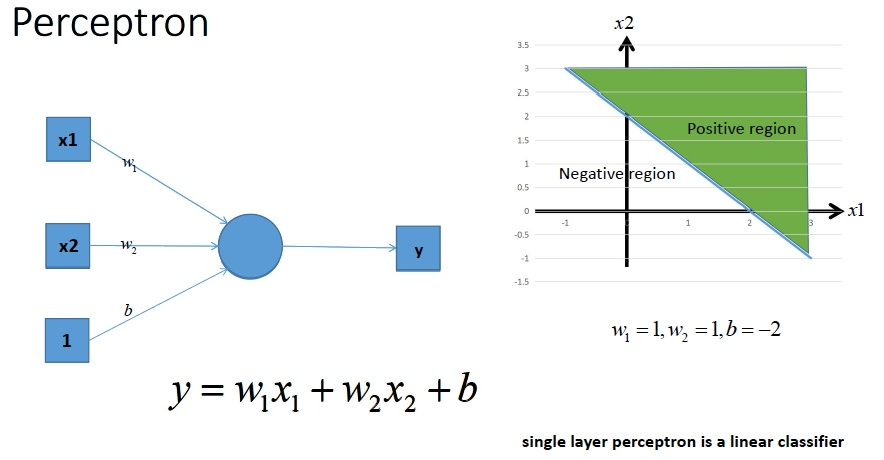
方程:$y = w_ix_1 + w_2x_2 + b$就是上图右边的直线。同理,我们也可以将多个感知机(注意,不是多层感知机)进行组合获得更强的*面分类能力:
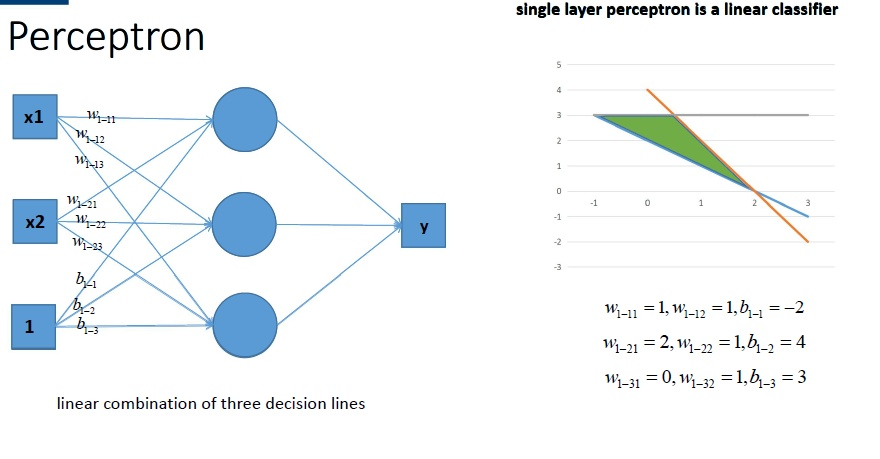
多层感知器
再看看包含一个隐层的多层感知机的情况,如图所示:
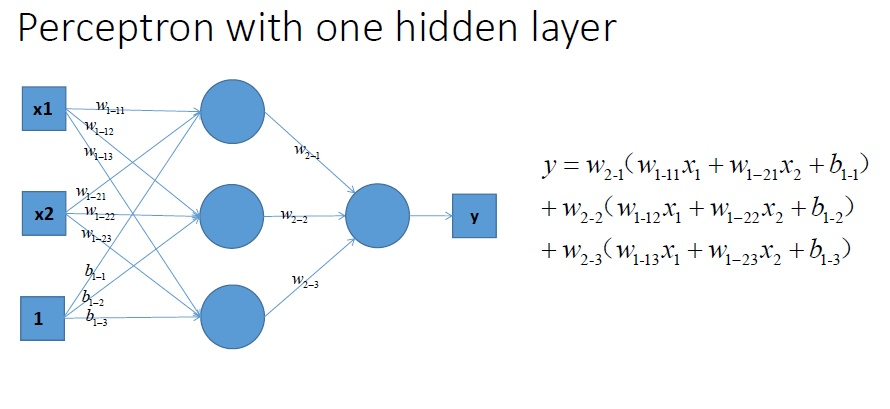
显而易见,无论如何更改参数,这样的结构都不能很好的完成最开始的那个二分类问题,因为问题本身就是线性不可分的。所以我们需要因素非线性的因素——激活函数。
激活函数
当我们在神经网络每一层神经元做完线性变换以后,加上一个非线性的激活函数对线性变换的结果进行转换,结果显而易见,输出立马变成一个不折不扣的非线性函数了,如图所示:
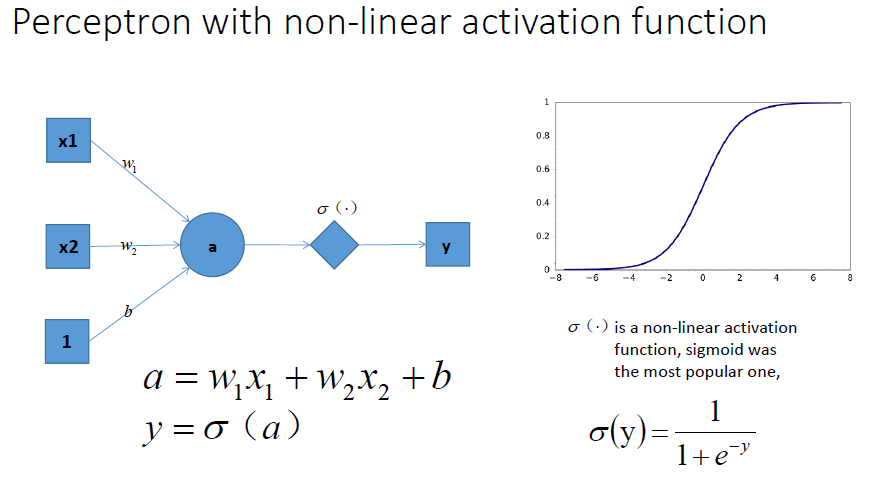
拓展到多层神经网络的情况, 和刚刚一样的结构, 加上非线性激励函数之后, 输出就变成了一个复杂的非线性函数了,如图所示:
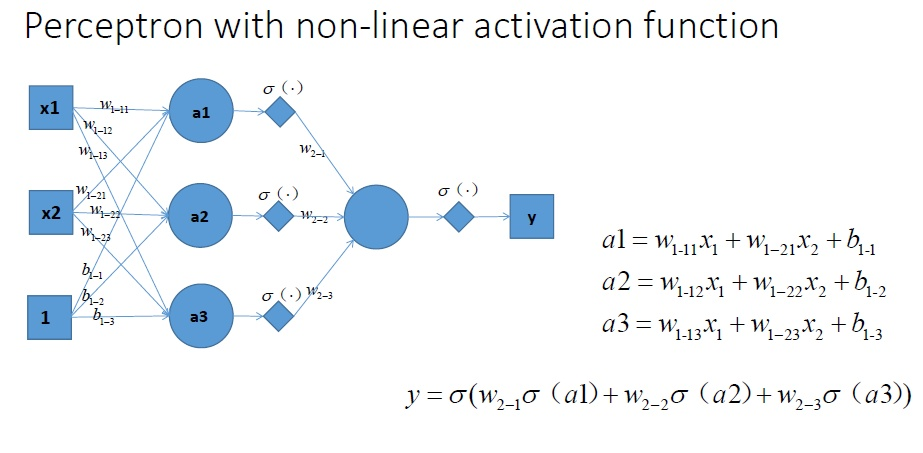
总结:加入非线性激励函数后,神经网络就有可能学习到*滑的曲线来分割*面,而不是用复杂的线性组合逼**滑曲线来分割*面,使神经网络的表示能力更强了,能够更好的拟合目标函数。 这就是为什么我们要有非线性的激活函数的原因。如下图所示说明加入非线性激活函数后的差异,上图为用线性组合逼**滑曲线来分割*面,下图为*滑的曲线来分割*面:

很显然,加入了激活函数的多层感知器,拥有了非线性的拟合能力,就能很好地完成最开始的二分类任务了。
有关激活函数的更详细介绍见深度学习之激活函数。
损失函数
通常机器学习的每一个算法中都会有一个目标函数,算法的求解过程即是对这个目标函数不断优化的过程。在分类或者回归问题中,通常使用损失函数(代价函数)作为其目标函数。而深度学习作为机器学习的一个重要分支,损失函数亦是其核心组成之一。神经网络模型的训练与预测都和损失函数息息相关,下面就从损失函数的设计思路与常见形式来进行详细解读。
设计思路
从一个例子入手:首先我们假设要预测一个公司某商品的销售量($X$:门店数,$Y$:销量):
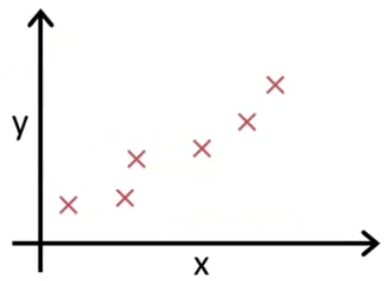
我们会发现销量随着门店数上升而上升。于是我们就想要知道大概门店和销量的关系是怎么样的呢?我们根据图上的点描述出一条直线:
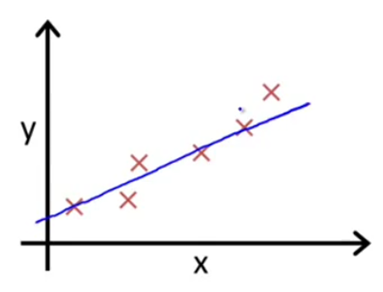
似乎这个直线差不多能说明门店数$X$和$Y$得关系了:我们假设直线的方程为$Y = a_0 + a_1X$($a$为常数系数)。假设$a_0 = 10, a_1 = 3$,那么$Y = 10 + 3X$(公式1)。
| $X$ | 预测$f(X)$ | 实际$Y$ | 差值 |
| 1 | 13 | 13 | 0 |
| 2 | 16 | 14 | 2 |
| 3 | 19 | 20 | -1 |
| 4 | 22 | 21 | 1 |
| 5 | 25 | 25 | 0 |
| 6 | 28 | 30 | -2 |
公式1中的$Y$即预测函数$f(X)$。我们希望预测的值与实际值差值越小越好,所以就定义了一种衡量模型好坏的方式,即损失函数(用来表现预测与实际数据的差距程度)。
于是乎我们就会想到这个方程的损失函数可以用绝对损失函数表示,即预测值$f(X)$减去实际值$Y$的绝对值,数学表达式:$L(Y, f(X)) = |Y - f(X)|$。上面的案例它的绝对损失函数求和计算求得为:6。为后续数学计算方便,我们通常使用*方损失函数代替绝对损失函数,即预测值$f(x)$减去实际值$Y$的*方,数学表达式:$L(Y, f(x)) = (Y - f(x))^2$。上面的案例它的*方损失函数求和计算求得为:10。
以上为公式1模型的损失值。
假设我们再模拟一条新的直线:$a_0 = 8,a_1 = 4。
| $X$ | 预测$f(X)$ | 实际$Y$ | 差值 |
| 1 | 12 | 13 | -1 |
| 2 | 16 | 14 | 2 |
| 3 | 20 | 20 | 0 |
| 4 | 24 | 21 | 3 |
| 5 | 28 | 25 | 3 |
| 6 | 32 | 30 | 2 |
那么有公式2:$Y = 8 + 4X$。绝对损失函数求和:11,*方损失函数求和:27。对比公式1的两个结果,从损失函数求和中,就能评估出公式1能够更好地预测门店销售。
总结:损失函数可以很好地反映模型与实际数据的差距,理解损失函数能够更好地对后续优化工具(梯度下降等)进行分析与理解。很多时候遇到复杂的问题,其实最难的一关是如何写出损失函数。
常见的损失函数
损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。不同的算法使用的损失函数不一样。
损失函数按照公式设计可分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差别,结构风险损失函数是指经验风险损失函数加上正则项。通常表示为如下:$$\theta^{*} = argmin\frac{1}{N}\sum_{i=1}^{N}L(y_i, f(x_i; \theta_i)) + \lambda \Phi(\theta)$$
其中,前面的均值函数表示的是经验风险函数,$L$代表的是损失函数,后面的$\Phi$是正则化项(Regularizer)或者叫惩罚项(Penalty term),它可以是$L1$,也可以是$L2$,或者其他的正则函数。整个式子表示的意思是找到使目标函数最小时的$\theta$值。
不同的损失函数有不同的表示意义,也就是在最小化损失函数过程中,预测逼*真实的方式不同,得到的结果可能也不同。
常见的损失函数以及其各自特性如下:
0-1损失函数(Zero-one Loss)
0-1损失是指预测值和目标值不相等为1,否则为0:$$L(Y, f(X)) = \begin{cases} 1, Y \neq f(X) \\ 0, Y = f(X) \end{cases}$$
特点:
(1)0-1损失函数直接对应分类判断错误的个数,但是它是一个非凸函数,不太适用。
(2)感知机就是用的这种损失函数。但是相等这个条件太过严格,因此可以放宽条件,即满足$|Y - f(X)| < T$时认为相等:$$L(Y, f(X)) = \begin{cases} 1, |Y - f(X) | \geq T \\ 0, |Y - f(X)| < T \end{cases}$$
绝对值损失函数
绝对值损失函数是计算预测值与目标值的差的绝对值:$$L(Y, f(X)) = |Y - f(X)|$$
log对数损失函数
逻辑回归(Logistic Regression)的损失函数就是log对数损失函数。在Logistic Regression的推导中,它假设样本服从伯努利分布(0-1)分布,然后求得满足该分布的似然函数,接着用对数求极值。Logistic Regression并没有求对数似然函数的最大值,而是把极大化当做一个思想,进而推导它的风险函数为最小化的负的似然函数。从损失函数的角度上,它就成为了log损失函数。
$\log$对数损失函数的标准形式如下:$$L(Y, P(Y|X)) = -\log P(Y|X)$$
在极大似然估计中,通常都是先取对数再求导,再找极值点,这样做是方便计算极大似然估计。损失函数$$L(Y, P(Y|X))$是指样本$X$在分类$Y$的情况下,使概率$P(Y|X)$达到最大值( 利用已知的样本分布,找到最大概率导致这种分布的参数值)。
特点:
(1)$\log$对数损失函数能非常好的表征概率分布,在很多场景尤其是多分类,如果需要知道结果属于每个类别的置信度,那它非常适合。
(2)健壮性不强,相比于Hinge loss对噪声更敏感。
*方损失函数
最小二乘法是线性回归的一种方法,它将回归的问题转化为了凸优化的问题。最小二乘法的基本原则是: 最优拟合曲线应该使得所有点到回归直线的距离和最小。通常用欧几里得距离进行距离的度量。
*方损失函数标准形式如下:$$L(Y|f(X)) = \sum_{N}(Y - f(X))^2$$
特点:经常应用于回归问题。
指数损失函数(Exponential Loss)
指数损失函数的标准形式如下:$$L(Y|f(X)) = exp[-yf(x)] $$
特点:对离群点、噪声非常敏感。经常用在AdaBoost算法中。
铰链损失函数(Hinge Loss)
Hinge损失函数和SVM是息息相关的。在线性支持向量机中,最优化问题可以等价于$$\min_{w,b}\sum_{i}^{N}(1 - y_i(wx_i + b)) + \lambda||w^2||$$
这个式子和如下的式子非常像:$$\frac{1}{m}\sum_{i=1}^{m}l(wx_i + by_i) + ||w||^2$$
Hinge损失函数标准形式如下:$$L(y, f(x)) = \max(0, 1 - yf(x))$$
$f(x)$是预测值,$y$为目标值。
特点:
(1)Hinge损失函数表示如果被分类正确,损失为0,否则损失就为$1 - yf(x)$。SVM就是使用这个损失函数。
(2)一般的$f(x)$在$-1$到$+1$之间,而目标值$y$为$-1$或$+1$。其含义是,$f(x)$的值在$-1$和$+1$之间就可以了,并不鼓励$|f(x)| > 1$,即并不鼓励分类器过度自信,让某个正确分类的样本距离分割线超过$1$并不会有任何奖励,从而使分类器可以更专注于整体的分类误差。
(3)健壮性相对较高,对异常点、噪声不敏感,但它没太好的概率解释。
感知损失(Perceptron loss)函数
感知损失函数的标准形式如下:$$L(y, f(x)) = \max(0, -f(x))$$
特点:是Hinge损失函数的一个变种,Hinge loss对判定边界附*的点(正确端)惩罚力度很高。而Perceptron loss只要样本的判定类别正确的话,它就满意,不管其判定边界的距离。它比Hinge loss简单,因为不是Max-margin Boundary,所以模型的泛化能力没Hinge loss强。
交叉熵损失函数 (Cross-entropy loss function)
交叉熵损失函数的标准形式如下:$$C = -\frac{1}{n}\sum_{x}[y\ln a + (1 - y)\ln (1 - a)]$$
注意公式中$x$表示样本,$y$表示实际的标签,$a$表示预测的输出,$n$表示样本总数量。
特点:
(1)本质上也是一种对数似然函数,可用于二分类和多分类任务中。
二分类问题中的loss函数(输入数据是softmax或者sigmoid函数的输出):$$loss = -\frac{1}{n}\sum_{x}[y\ln a + (1 - y)\ln (1 - a)]$$
多分类问题中的loss函数(输入数据是softmax或者sigmoid函数的输出):$$loss = -\frac{1}{n}\sum_{i}y_i\ln a_i$$
(2)当使用sigmoid作为激活函数的时候,常用交叉熵损失函数而不用均方误差损失函数。因为它可以完美解决*方损失函数权重更新过慢的问题,具有“误差大的时候,权重更新快;误差小的时候,权重更新慢”的良好性质。
##################################################
要点补充
一、对数损失函数和交叉熵损失函数是等价的!!!

二、交叉熵函数与最大似然函数的联系和区别?
区别:
交叉熵函数被使用来描述模型预测值和真实值的差距大小,越大代表越不相*;
似然函数的本质就是衡量在某个参数下,整体的估计和真实的情况一样的概率,越大代表越相*。
联系:交叉熵函数可以由最大似然函数在伯努利分布的条件下推导出来,或者说最小化交叉熵函数的本质就是对数似然函数的最大化。
怎么推导的呢?我们具体来看一下。
设一个随机变量$X$满足伯努利分布,$P(X = 1) = p, P(X = 0) = 1 - p$,则$X$的概率密度函数为:$P(X) = p^X(1 - p)^{1 - X}$。
因为我们只有一组采样数据$D$,我们可以统计得到$X$和$1 - X$的值,但是$p$的概率是未知的,接下来我们就用极大似然估计的方法来估计这个$p$值。
对于采样数据$D$,其对数似然函数为:$$\begin{align}\log P(D) &= \log\prod_{i}^{N}P(D_i) \\ &= \sum_i \log(D_i) \\ &= \sum_i(D_i\log p + (1 - D_i)\log(1 - p)) \end{align}$$
可以看到上式和交叉熵函数的形式几乎相同,极大似然估计就是要求这个式子的最大值。而由于上面函数的值总是小于0,一般像神经网络等对于损失函数会用最小化的方法进行优化,所以一般会在前面加一个负号,得到交叉熵函数(或交叉熵损失函数):$$loss = -\sum_i(D_i\log p + (1 - D_i)\log(1 - p))$$
这个式子揭示了交叉熵函数与极大似然估计的联系,最小化交叉熵函数的本质就是对数似然函数的最大化。
现在我们可以用求导得到极大值点的方法来求其极大似然估计,首先将对数似然函数对$p$进行求导,并令导数为$0$,得到$$\sum_i(D_i\frac{1}{p} + (1 + D_i)\frac{1}{p - 1}) = 0$$
消去分母,得:$$\sum_i^N(p - D_i) = 0$$
所以:$$p = \frac{1}{N}\sum_iD_i$$
这就是伯努利分布下最大似然估计求出的概率$p$。
三、在用sigmoid作为激活函数的时候,为什么要用交叉熵损失函数,而不用均方误差损失函数?
其实这个问题求个导,分析一下两个误差函数的参数更新过程就会发现原因了。
对于均方误差损失函数,常常定义为:$$C = \frac{1}{2n}\sum_x(a - y)^2$$
其中$y$是我们期望的输出,$a$为神经元的实际输出( $a = \sigma(z), z = wx + b$)。在训练神经网络的时候我们使用梯度下降的方法来更新$w$和$b$,因此需要计算代价函数对$w$和$b$的导数:$$\begin{align} \frac{\partial C}{\partial w} &= (a - y)\sigma'(z)x \\ \frac{\partial C}{\partial b} &= (a - y)\sigma'(z) \end{align}$$
然后更新参数$w$和$b$:$$\begin{align} w = w - \eta\frac{\partial C}{\partial w} &= w - \eta(a - y)\sigma'(z)x \\ b = b - \eta\frac{\partial C}{\partial b} &= b - \eta(a - y)\sigma'(z) \end{align}$$
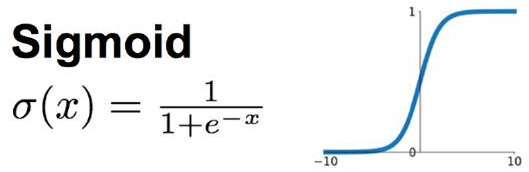
因为sigmoid的性质,导致$\sigma'(z)$在$z$取大部分值时会很小(如下图标出来的两端,几乎接*于*坦),这样会使得 $\eta(a - y)\sigma'(z)$很小,导致参数$w$和$b$更新非常慢。
那么为什么交叉熵损失函数就会比较好了呢?同样的对于交叉熵损失函数,计算一下参数更新的梯度公式就会发现原因。交叉熵损失函数一般定义为:
$$C = -\frac{1}{n}\sum_x[y\ln a + (1 + y)\ln(1 - a)]$$
其中$y$是我们期望的输出,$a$为神经元的实际输出($a = \sigma(z), z = wx + b$)。同样可以看看它的导数:$$\begin{align} \frac{\partial C}{\partial a} &= -\frac{1}{n}\sum_x[y\frac{1}{a} + (y - 1)\frac{1}{1 - a}] \\ &= -\frac{1}{n}\sum_x[\frac{1}{a(1 - a)}y - \frac{1}{1 - a}] \\ &= -\frac{1}{n}\sum_x[\frac{1}{\sigma(x)(1 - \sigma(x))}y - \frac{1}{1 - \sigma(x)}] \end{align}$$
另外,$$\begin{align} \frac{\partial C}{\partial z} &= \frac{\partial C}{\partial a}\frac{\partial a}{\partial z} \\ &= -\frac{1}{n}\sum_x[\frac{1}{\sigma(x)(a - \sigma(x))}y - \frac{1}{1 - \sigma(x)}] \cdot \sigma'(x) \\ &= -\frac{1}{n}\sum_x[\frac{1}{\sigma(x)(a - \sigma(x))}y - \frac{1}{1 - \sigma(x)}] \cdot \sigma(x)(1 - \sigma(x)) \\ &=-\frac{1}{n}\sum_x(y - a) \end{align}$$
所以有:$$\begin{align} \frac{\partial C}{\partial w} &= \frac{\partial C}{\partial z}\frac{\partial z}{\partial w} = (a - y)x \\ \frac{\partial C}{\partial b} &= \frac{\partial C}{\partial z}\frac{\partial z}{\partial b} = (a - y) \end{align}$$
所以参数更新公式为:$$\begin{align} w &= w -\eta\frac{\partial C}{\partial w} = w - \eta(a - y)x \\ b &= b - \eta\frac{\partial C}{\partial b} = b - \eta(a - y) \end{align}$$
可以看到参数更新公式中没有$\sigma'(x)$这一项,权重的更新受$(a - y)$影响,受到误差的影响,所以当误差大的时候,权重更新快;当误差小的时候,权重更新慢。这是一个很好的性质。
所以当使用sigmoid作为激活函数的时候,常用交叉熵损失函数而不用均方误差损失函数。
##################################################
总结
虽然损失函数可以让我们看到模型的优劣,并且为我们提供了优化的方向,但是也必须明确:没有任何一种损失函数适用于所有的模型。
损失函数的选取依赖于参数的数量、异常值、机器学习算法、梯度下降的效率、导数求取的难易和预测的置信度等若干方面。关于损失函数更详细的解读见深度学习之损失函数,其中按照机器学习的任务不同,将损失函数分成了回归问题和分类问题两大类进行详细地分析与汇总,在回归模型中,最终会给出一个数值结果,而在分类模型中,则会给出一个类别标签。
前向传播与反向更新
前向
梯度下降
关于梯度下降算法如何更新参数,依然采用损失函数的那个案例。
目标:已知学习样本$X$与$Y$,求解预测函数$f(X)$的系数(待学习参数),希望损失函数$L(X)$取到最小值。
假设我们已知门店销量为
| $X$ | 实际$Y$ |
| 1 | 13 |
| 2 | 14 |
| 3 | 20 |
| 4 | 21 |
| 5 | 25 |
| 6 | 30 |
我们如何预测门店数X与Y的关系式呢?假设我们设定$X$与$Y$为线性关系:$Y = a_0 + a_1X$,接下来我们如何使用已知数据预测参数$a_0$和$a_1$呢?这里就是用了梯度下降法:

左侧就是梯度下降法的核心内容,右侧$h_{\theta}(x)$为假设的关系模型(线性),$J(\theta)$为损失函数。
其中$\theta_j$表示关系模型$h_{\theta}(x)$的系数,$\alpha$为学习率。
对这样的线性回归问题运用梯度下降法,关键在于求出损失函数的导数,即:$$\frac{\partial}{\partial \theta_{j}}J(\theta_0\theta_1) = \frac{\partial}{\partial \theta_j}\frac{1}{2m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)}) - y^{(i)})^2$$
其中,待学习参数$\theta_0$和$\theta_1$对应前文的$a_0$和$a_1$,$m$为样本个数,$x$表示门店个数,$y$表示门店总销量。
当$j = 0$时,有$$\frac{\partial}{\partial \theta_{0}}J(\theta_0\theta_1) = \frac{1}{m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)}) - y^{(i)})$$
当$j = 0$时,有$$\frac{\partial}{\partial \theta_{1}}J(\theta_0\theta_1) = \frac{1}{m}\sum_{i=1}^{m}((h_{\theta}(x^{(i)}) - y^{(i)}) - x^{(i)})$$
则,算法改成:
$$\begin{align} \text{Repeat} \{&\\ &\theta_0 := \theta_0 - \alpha \frac{1}{m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)}) - y^{(i)}) \\ &\theta_1 := \theta_1 - \alpha \frac{1}{m}\sum_{i=1}^{m}((h_{\theta}(x^{(i)}) - y^{(i)}) - x^{(i)}) \\ &\} \end{align}$$
直观的表示即上面那幅公式图。
优化策略
神经网络模型中用到的优化算法大多是基于梯度下降的一阶优化,常用的一阶优化算法如下图所示:
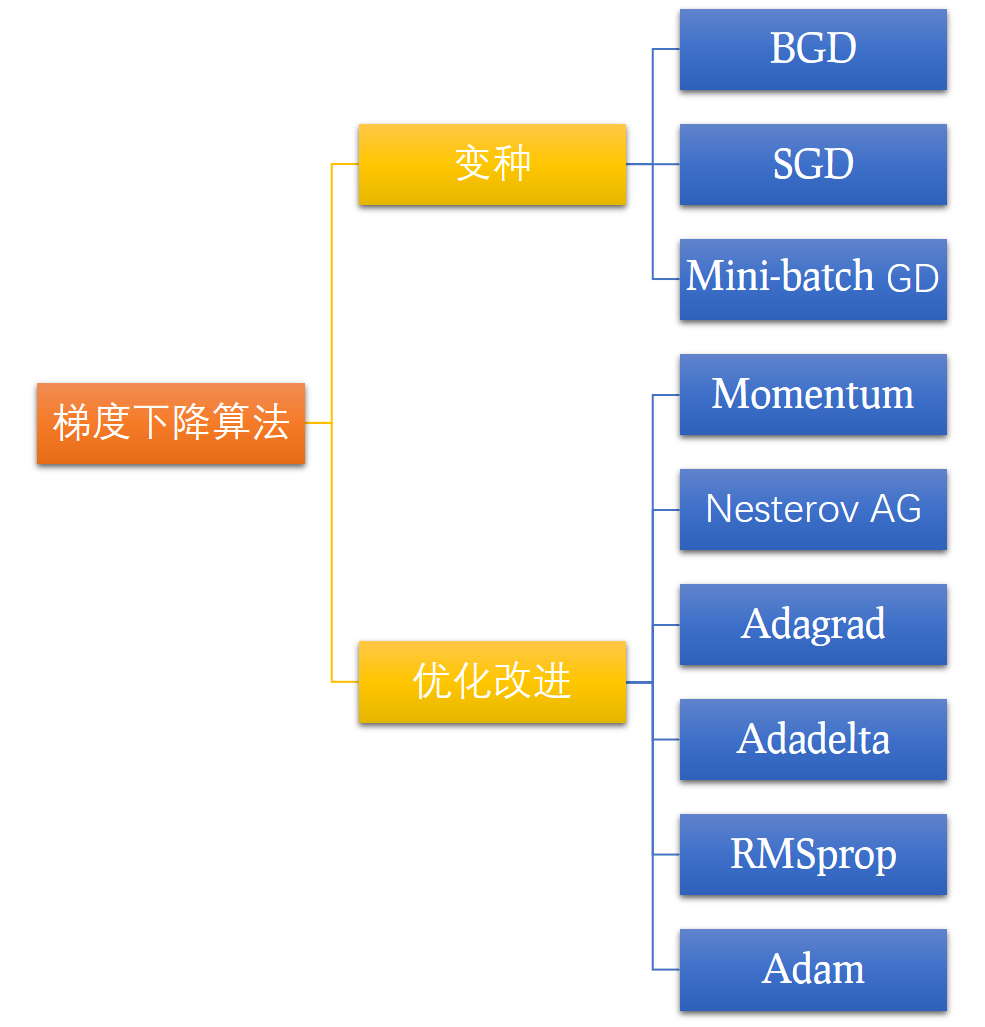
关于图上各算法的详细解读与归纳见深度学习之常用优化策略(一阶)。
更多关于牛顿法等二阶优化算法的内容感兴趣的同学请点击:机器学习之优化策略(二阶)。
常用模型
CNN
RNN
VaDE
DIM
Siamese Network
Contrastic Learning
...
(图文整理自网络)
参考链接:
https://liam.page/2018/04/17/zero-centered-active-function/
https://www.zhihu.com/question/22334626
https://blog.csdn.net/l18930738887/article/details/50670370
https://blog.csdn.net/weixin_37933986/article/details/68488339?
https://zhuanlan.zhihu.com/p/58883095