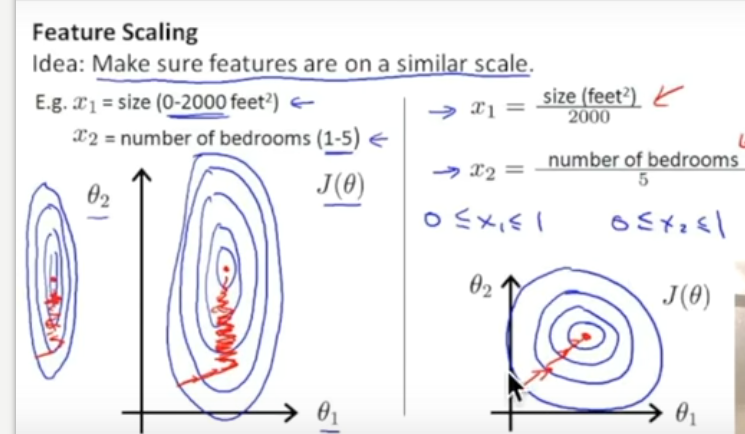
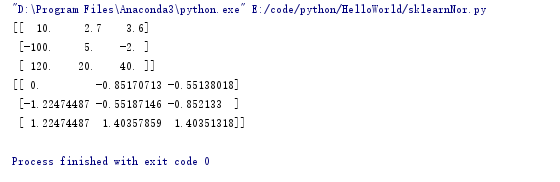
from sklearn import preprocessing import numpy as np a = np.array([[10,2.7,3.6],[-100,5,-2],[120,20,40]],dtype=np.float64) print(a) print(preprocessing.scale(a))
from sklearn import preprocessing import numpy as np from sklearn.cross_validation import train_test_split from sklearn.datasets.samples_generator import make_classification from sklearn.svm import SVC import matplotlib.pyplot as plt # a = np.array([[10,2.7,3.6],[-100,5,-2],[120,20,40]],dtype=np.float64) # print(a) # print(preprocessing.scale(a)) X,Y = make_classification(n_samples=300,n_features=2,n_redundant=0,n_informative=2,random_state=22, n_clusters_per_class=1, scale=100) # plt.scatter(X[:, 0], X[:, 1], c=Y) # plt.show() #X=preprocessing.scale(X) X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3) clf = SVC() clf.fit(X_train, y_train) print(clf.score(X_test, y_test))

from sklearn import preprocessing import numpy as np from sklearn.cross_validation import train_test_split from sklearn.datasets.samples_generator import make_classification from sklearn.svm import SVC import matplotlib.pyplot as plt # a = np.array([[10,2.7,3.6],[-100,5,-2],[120,20,40]],dtype=np.float64) # print(a) # print(preprocessing.scale(a)) X,Y = make_classification(n_samples=300,n_features=2,n_redundant=0,n_informative=2,random_state=22, n_clusters_per_class=1, scale=100) # plt.scatter(X[:, 0], X[:, 1], c=Y) # plt.show() X=preprocessing.scale(X) X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3) clf = SVC() clf.fit(X_train, y_train) print(clf.score(X_test, y_test))
