一、time模块
1、时间表达形式:
在Python中,通常有这三种方式来表示时间:时间戳、元组(struct_time)、格式化的时间字符串:
1.1、时间戳(timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们
运行“type(time.time())”,返回的是float类型。
1.2、格式化的时间字符串(Format String): ‘1988-09-10’
1.3、元组(struct_time) :struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,
一年中第几天等)
import time
# 时间戳
print(time.time())
#时间字符串
print(time.strftime("%Y-%m-%d %X"))
#时间元组
print(time.localtime())
-------------输出结果---------------
1493196609.4780002
2017-04-26 16:50:09
time.struct_time(tm_year=2017, tm_mon=4, tm_mday=26,
tm_hour=16, tm_min=50, tm_sec=9, tm_wday=2, tm_yday
=116, tm_isdst=0)
小结:时间戳是计算机能够识别的时间;
时间字符串是人能够看懂的时间;
元组则是用来操作时间的。
2、时间形式之间的转换:

2.1.1、结构化时间和时间戳之间的装换:
import time
time_stamp = time.time() #获取时间戳
struct_time = time.localtime() #获取结构化时间
print("struct_time:",struct_time)
print("time_stamp:",time_stamp)
#时间戳----->结构化时间
print(time.localtime(time_stamp))
#结构化时间----->时间戳
print(time.mktime(struct_time))
-----------------输出结果-----------------------
struct_time: time.struct_time(tm_year=2017, tm_mon=4,
tm_mday=26,tm_hour=17, tm_min=37, tm_sec=4, tm_wday
=2, tm_yday=116, tm_isdst=0)
time_stamp: 1493199424.8830001
time.struct_time(tm_year=2017, tm_mon=4, tm_mday=26,
tm_hour=17, tm_min=37, tm_sec=4, tm_wday=2, tm_yday=
116, tm_isdst=0)
1493199424.0
2.1.2、结构化时间和字符串时间之间的装换:
import time
format_time = time.strftime("%Y-%m-%d %X") #获取字符串时间
struct_time = time.localtime() #获取结构化时间
print(struct_time)
print(format_time)
#字符串时间----->结构化时间
print(time.strptime(format_time,"%Y-%m-%d %X"))
#结构化时间----->字符串时间
print(time.strftime("%Y-%m-%d %X",struct_time))
--------------------输出结果-----------------------
time.struct_time(tm_year=2017, tm_mon=4, tm_mday=26,
tm_hour=18, tm_min=0, tm_sec=5, tm_wday=2, tm_yday=
116, tm_isdst=0)
2017-04-26 18:00:05
time.struct_time(tm_year=2017, tm_mon=4, tm_mday=26,
tm_hour=18, tm_min=0, tm_sec=5, tm_wday=2, tm_yday=
116, tm_isdst=-1)
2017-04-26 18:00:05
注意:字符串时间跟时间戳之间是不能进行转换的。
2.2、见图
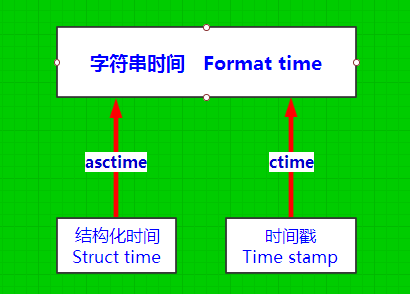
import time time_stamp = time.time() #获取时间戳 struct_time = time.localtime() #获取结构化时间 print(time.asctime(struct_time)) #结构化时间固定格式转换成字符串时间 print(time.ctime(time_stamp)) #时间戳固定格式转换成字符串时间 #输出格式为:星期 月 日 时 分 秒 年 print(type(time.asctime(struct_time))) #查看数据类型 --------------------输出结果----------------------------- Wed Apr 26 18:20:09 2017 Wed Apr 26 18:20:09 2017 <class 'str'>
其他方法:
sleep(secs) 线程推迟指定的时间运行,单位为秒。
二、random模块
import random ret = random.random() #随机大于0且小于1之间的小数 print(ret) # 0 < ret < 1 之间的小数 ret = random.uniform(1,3) #随机大于1且小于3的小数 print(ret) # 1 < ret < 3 之间的小数 ret = random.randint(1,5) #随机大于等于1且小于等于5之间的整数 print(ret) # 1 <= ret <= 5 之间的整数 ret = random.randrange(1,3) #随机大于等于1且小于3之间的整数 print(ret) # 1<= ret < 3 之间的整数 ret = random.choice([1,"abc",[2,3]]) #随机取出一个有序列的数据类型里的任意一个元素 print(ret) #返回一个列表里随机一个元素 ret = random.sample((1,"23",[3,4]),2) #随机取出一个有序列的数据类型里的任意两个个元素 print(ret) #返回一个列表里随机两个元素 item = [1,2,3,4,5] random.shuffle(item) #随机打乱次序 print(item) #查看输出结果 random.shuffle(item) #随机打乱次序,每次不一样 print(item) #查看输出结果 --------------输出结果--------------- 0.0514007698403014 1.4354983460192048 2 1 [2, 3] [1, [3, 4]] [1, 4, 5, 2, 3] [5, 3, 2, 4, 1]
自己写一个6位数验证码:


1 #生成一个随机的6位数验证码 2 def validate(): 3 s = "" #设一个空字符串 4 for i in range(6): #下面的代码循环6次 5 r_num = random.randint(0,9) #取出0到9之间的一个整数赋值给r_num 6 r_letter = chr(random.randint(65,90)) #取出数字跟ASCII表对应的大写字母赋值给r_letter 7 r_letter1 = chr(random.randint(97,122)) #取出数字跟ASCII表对应的小写字母赋值给r_letter1 8 ret = random.choice([str(r_num),r_letter,r_letter1]) #随机选出一个元素,数字、大写字母、小写字母 9 s += ret #每循环一次,自加到字符串里 10 return s 11 print(validate()) #打印输出的结果 12 ---------------输出结果---------------- 13 eJ23b9 #每次都不一样
三、hashlib模块
1 、算法介绍:
hashlib模块提供了常见的摘要算法,俗称用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1,
SHA224, SHA256, SHA384, SHA512 ,MD5 算法。
什么是摘要算法呢?
摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16
进制的字符串表示)。
摘要算法的作用:
摘要算法就是通过摘要函数func()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是
否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反
推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
我们以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
import hashlib
m = hashlib.md5() #.选择算法得到一个对象m
m.update("hello michael".encode("utf8")) #将一个字符串按某种编码方式得到一个摘要值
print(m.hexdigest()) #调用函数查看计算的结果
m.update("hello michael".encode("utf8")) #同一个对象,相同的字符串得到的结果不一样
print(m.hexdigest()) #调用函数查看计算的结果
m.update("hello egon".encode("utf8")) #将一个字符串按某种编码方式得到一个摘要值
print(m.hexdigest()) #调用函数查看计算的结果
m.update("hello egon".encode("gbk")) #相同的字符串,不同编码方式,得到的摘要值不一样
print(m.hexdigest()) #调用函数查看计算的结果
m2 = hashlib.md5() #.选择算法得到一个对象m2
m2.update("hello michael".encode("utf8")) #不同的对象,相同的字符串,相同的编码方式,得到一样的结果
print(m2.hexdigest()) #调用函数查看计算的结果
-------------------输出结果-----------------------
47bf238f10127e5cd1a031695b16a247
1ad608efea97ce788c4cdc1c67f96c33
83ec549f97aa6705d93fc16a15d7efbf
2f9beff0cc454e53202af509d170fe1c
47bf238f10127e5cd1a031695b16a247
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
import hashlib
m = hashlib.md5() #.选择算法得到一个对象m
m.update("hello".encode("utf8")) #对“hello michael”进行分块
print(m.hexdigest())
m.update("michael".encode("utf8")) #对“hello michael”进行分块
print(m.hexdigest()) #得到的值跟一块的一样
m2 = hashlib.md5() #.选择算法得到一个对象m2
m2.update("hellomichael".encode("utf8")) #两个字符串合一块,跟上面是一样的
print(m2.hexdigest()) #得到的跟分块的一样
------------------输出结果--------------------
5d41402abc4b2a76b9719d911017c592
2887f48a873232a855bd54cf3150f039
2887f48a873232a855bd54cf3150f039
md5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。另一
种常见的摘要算法是sha1,调用sha1和调用md5完全类似:
import hashlib
s = hashlib.sha1()
s.update("hello".encode("utf8"))
print(s.hexdigest())
s.update("michael".encode("utf8"))
print(s.hexdigest()) #跟md5用法一样
s1 = hashlib.sha1()
s1.update("hellomichael".encode("utf8"))
print(s1.hexdigest()) #跟md5用法一样
-----------------输出结果---------------------
aaf4c61ddcc5e8a2dabede0f3b482cd9aea9434d
4bc281050eec21c18a797edcd90973f8a27403f6
4bc281050eec21c18a797edcd90973f8a27403f6
sha1的结果是160 bit字节,通常用一个40位的16进制字符串表示。比sha1更安全的算法是sha256和sha512,不过越
安全的算法越慢,而且摘要长度更长。
以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义
key再来做加密。
import hashlib
s1 = hashlib.sha256("heihei".encode("utf8"))
s1.update("hello michael".encode("utf8"))
print(s1.hexdigest())
------------------------输出结果-----------------------
d1c657d13bb1f1e1e3efa97faaec019b04f0ea4021fb368eba597bd3bb613bd0
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密:
import hmac
h1 = hmac.new("heihei".encode("utf8"))
h1.update("hello".encode("utf8"))
print(h1.hexdigest())
h1.update("michael".encode("utf8"))
print(h1.hexdigest())
h2 = hmac.new("heihei".encode("utf8"))
h2.update("hellomichael".encode("utf8"))
print(h2.hexdigest())
------------------输出结果---------------------
c106aa9b321aa75c51fdc3f366ba74a5
d827a25481411c0ce78ea2f804fa1c33
d827a25481411c0ce78ea2f804fa1c33
2、摘要算法应用:
任何允许用户登录的网站都会存储用户登录的用户名和口令。如何存储用户名和口令呢?方法是存到数据库表中:
name | password ------------------------- michael | 123456 egon | abc999 jack | 112233
如果以明文保存用户口令,如果数据库泄露,所有用户的口令就落入黑客的手里。此外,网站运维人员是可以访问数
据库的,也就是能获取到所有用户的口令。正确的保存口令的方式是不存储用户的明文口令,而是存储用户口令的摘要,
比如MD5:
name | password ------------------------- michael | e10adc3949ba59abbe56e057f20f883e egon | 878ef96e86145580c38c87f0410ad153 jack | d0970714757783e6cf17b26fb8e2298f
考虑这么个情况,很多用户喜欢用123456,888888,password这些简单的口令,于是,黑客可以事先计算出这些常
用口令的MD5值,得到一个反推表:
'e10adc3949ba59abbe56e057f20f883e': '123456' '21218cca77804d2ba1922c33e0151105': '888888' '5f4dcc3b5aa765d61d8327deb882cf99': 'password'
这样,无需破解,只需要对比数据库的MD5,黑客就获得了使用常用口令的用户账号。
对于用户来讲,当然不要使用过于简单的口令。但是,我们能否在程序设计上对简单口令加强保护呢?
由于常用口令的MD5值很容易被计算出来,所以,要确保存储的用户口令不是那些已经被计算出来的常用口令的
MD5,这一方法通过对原始口令加一个复杂字符串来实现,俗称“加盐”:
import hashlib
hashlib.md5("salt".encode("utf8")) #这就是“加盐”,呵呵
经过Salt处理的MD5口令,只要Salt不被黑客知道,即使用户输入简单口令,也很难通过MD5反推明文口令。
但是如果有两个用户都使用了相同的简单口令比如123456,在数据库中,将存储两条相同的MD5值,这说明这两个
用户的口令是一样的。有没有办法让使用相同口令的用户存储不同的MD5呢?
如果假定用户无法修改登录名,就可以通过把登录名作为Salt的一部分来计算MD5,从而实现相同口令的用户也存储
不同的MD5。
摘要算法在很多地方都有广泛的应用。要注意摘要算法不是加密算法,不能用于加密(因为无法通过摘要反推明文)
,只能用于防篡改,但是它的单向计算特性决定了可以在不存储明文口令的情况下验证用户口令。