对于requests的爬虫库,我们已经学到了尾声。
我们在这儿可以挖掘出更多的requests的使用小技巧。
一.cookie对象与字典的转换
在爬取目标cookie的时候,我们可以将cookie信息进行简化处理。
现在做一个简单的代码验证看看,使用百度的cookies:
RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
{'BDORZ': '27315'}
那么,反过来切换呢?
response_cookie_1=requests.utils.cookiejar_from_dict=(response_dict)
print(response_cookie_1)
输出结果:
<RequestsCookieJar[<Cookie BDORZ=27315 for />]>
我们可以分析此次的输出结果可以知道,重新翻译过来url信息丢失了,具有信息保护性。
二.url编码的解码处理
我们在做爬虫的过程中,是经常会遇到我们输入的url被解码成另外一种数据形式。
例如:http://tieba.baidu.com/f?kw=无限法则
我们在对这个网址进行爬虫处理之后,在输出结果显示的时候,已经编码成了这个形式:
http%3a%2f%2ftieba.baidu.com%2ff%3fkw%3d%e6%97%a0%e9%99%90%e6%b3%95%e5%88%99
翻译的时候,我们还得上网去翻译过来。那么requests正好也提供了这个功能,能够完成翻译,避免了你去网上翻译的过程。
现在就放一段代码看看:
输出结果:
http://tieba.baidu.com/f?kw=无限法则
反过来也是一样的:
url_3=requests.utils.quote(url_2)
print(url_3)
输出结果:
http%3A//tieba.baidu.com/f%3Fkw%3D%E6%97%A0%E9%99%90%E6%B3%95%E5%88%99
所以我们总结起来,就是这样:
quote:对URL编码; unquote:对解码的URL进行解码
三.请求SSL证书验证解决
我们在做爬虫的时候,会经常遇到网站请求SSL证书的验证,这将是爬虫遇到的家常便饭。
那么我们如何跳过这个SSL证书呢,在get参数中加入一个参数即可。
假设我们访问百度,遇到了SSL证书问题,我们要做的就是:
response=requests.get("http://www.baidu.com",verify=False)
以上就是三个requests的使用小技巧,当然,requests库是强大的,能做的不只是这些。
关于其他的用法,我们在今后使用的时候会慢慢探索出来,具有一定的自学能力是最好的。
回顾一下我们学习requests的过程,我们可以做一个总结:
①填写正确的url形式,是有协议,IP地址,端口和路径等组成的,其中协议不能忘了写。
正确的url形式为"http://www.baidu.com"
②学会对自己的伪装,准备一堆User-Agent,一堆IP和一堆cookie。
选择代理IP时,选端口跟自己网络端口符合的。
③两种请求方式的公式和参数有如下:
requests.get(url,headers=?(存储User-Agent参数),params=?(存储wd访问参数),proxies=?(存储IP地址参数),cookies=?(存储cookies参数),verify=?(解决SSL证书验证))
requests.post(url,headers=?(存储User-Agent参数),data=?(存储form表单参数),proxies=?(存储IP地址参数),cookies=?(存储cookies参数),verify=?(解决SSL证书验证))
当然,这些参数都是以字典的形式而作为参数。
④显示源码最好的方式就是respsonse.content.decode(),如果要将json文本转为python文本,使用json库的json.loads()方法。
保存源码的方式是with open,标准的格式为:
with open ("?"(文件的名字),"w"(进入可读模式),encoding="utf-8"(不可缺,不然在编辑器上显示不出来))as f :
f.write(response.content.decode())
那么,requests模块就学到这儿,但是正确的学习方式是学以致用,我将给自己布置下面两个作业:
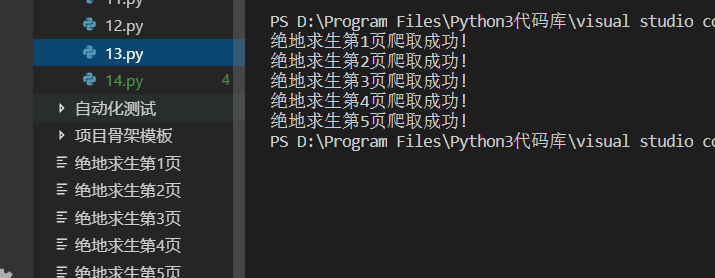
1.抓取绝地求生贴吧的前5页源码。
已成功完成,运行截图如下:
源码如下:
import requests
class TiebaSpider():
def __init__(self, tieba_name):
self.tieba_name = tieba_name
self.url = "https://tieba.baidu.com/f?kw=" + tieba_name + "&ie=utf-8&pn={}"
self.proxies = {"http": "http://139.196.90.80:80"}
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6814.400 QQBrowser/10.3.3005.400"}
self.cookies = {
"cookie": "BIDUPSID=ACDA08B4211ABB2C8501DB67D45C6354; PSTM=1511497343; bdshare_firstime=1511786525592; rpln_guide=1; TIEBAUID=0929173e72ad98f36fe7ebc6; TIEBA_USERTYPE=e916512877b43f62b624ed45; BDUSS=RuaHRBTnhZdDY3MTBKaWo3U0lKdkRES2Y0VGEyS2F0RW1BYXYyN3N0bWlIRXRjQVFBQUFBJCQAAAAAAAAAAAEAAABLXgnSxdzF3E1BU1RFUgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAKKPI1yijyNcMj; STOKEN=5fc0d6f6e16857ed3e6abac93bd75cae1cf244d5fd9d4e106b3ecb9d56017894; locale=zh; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BAIDUID=4D17734C04368D8A9BDE5236D01D183E:FG=1; Hm_lvt_98b9d8c2fd6608d564bf2ac2ae642948=1547216027,1547272466,1547303935,1547367124; wise_device=0; Hm_lpvt_98b9d8c2fd6608d564bf2ac2ae642948=1547367145"}
def get_url_list(self, url):
url_list = []
for i in range(5):
url_list.append(url.format(i * 50))
return url_list
def parse_url(self, url):
response = requests.get(url, headers=self.headers, proxies=self.proxies, cookies=self.cookies)
return response.content.decode()
def save_html(self, html, page_num):
with open(self.tieba_name + "第" + str(page_num) + "页", "w", encoding="utf") as f:
f.write(html)
def run(self):
# 1.使用url_list成功存储五页源码
url_list = self.get_url_list(self.url)
# 2.获取响应
# 3.保存源码到html文件
page_num = 1
for url in url_list:
html = self.parse_url(url)
self.save_html(html, page_num)
print(self.tieba_name + "第" + str(page_num) + "页爬取成功!")
page_num += 1
if __name__ == "__main__":
tieba_spider = TiebaSpider("绝地求生")
tieba_spider.run()
2.使用搜狗翻译将英文翻译成中文。
完成失败。
总结原因:搜狗采取了反爬虫,在表单中去掉了翻译结果的参数。
我尝试使用正则表达式匹配出来结果,但是技术不精,匹配失败。
已经自闭,下次再来。