1.情景展示
做了这么长时间的java开发,但是,你知道JVM是以怎样的编码加载、解析class文件的吗?
我们知道,通常情况下,我们会将java文件的字符集修改成utf-8,这样,理所当然地就认为:JVM在加载class的时候,自然是按照utf-8进行解析的。
事实并非如此:JVM加载class文件默认采用的字符集,是由操作系统来决定的。
换句话说,JVM会根据操作系统的字符集来解析你的class文件,而不是智能的去判断你的class文件的字符集而进行解析。
这样,肯定有问题。
2.原因分析
以win7/win10中文操作系统为例,我们借助开发工具以utf-8将java文件编译成class文件,而解析的时候却以GBK的编码加载到JVM中,不出问题才怪!
但是,问题恰恰就出现在了这里,一直都是以utf-8进行编译,以gbk进行解析,中文也没有出现乱码问题,至于为什么,我没有想通。
今天的重点不在这里,重点是,我们怎么让JVM以utf-8的格式解析class文件?
3.解决方案
方案一:设置环境变量
快捷键:win+r--》输入sysdm.cpl-->回车--》高级--》环境变量--》系统变量--》新建
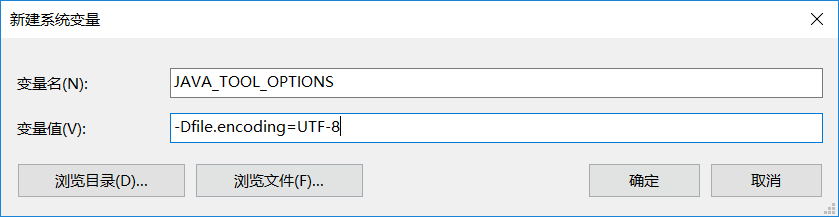
变量名设置为:JAVA_TOOL_OPTIONS
变量值设置为: -Dfile.encoding=UTF-8
确定即可。
方案二:修改tomcat
路径:{TOMCAT_HOME}/bin/catalina.bat
打开该文件,在有对JAVA_OPS设置的地方,添加代码

:设置JVM以utf-8格式解析class文件 set "JAVA_OPTS=%JAVA_OPTS% -Dfile.encoding=UTF-8"
重新启动tomcat即可。
注意:如果你像上面那样修改成utf-8后,重启后的tomcat,日志肯定乱码。

因为Tomact日志字符集采用的是gbk,java强制将gbk转换成utf-8后,造成乱码是自然的事情了。
位置:{TOMCAT_HOME}/conf/logging.properties文件

#指定tomcat日志字符集 java.util.logging.ConsoleHandler.encoding = GBK
修改成功后,日志便不再乱码。
提醒:在Windows下,在黑窗口使用命令对java文件进行编译且没有指定字符集的前提下,编译时默认采用的也是gbk的编码,与java文件本身的字符集无关。