1.导入模块获取网页头

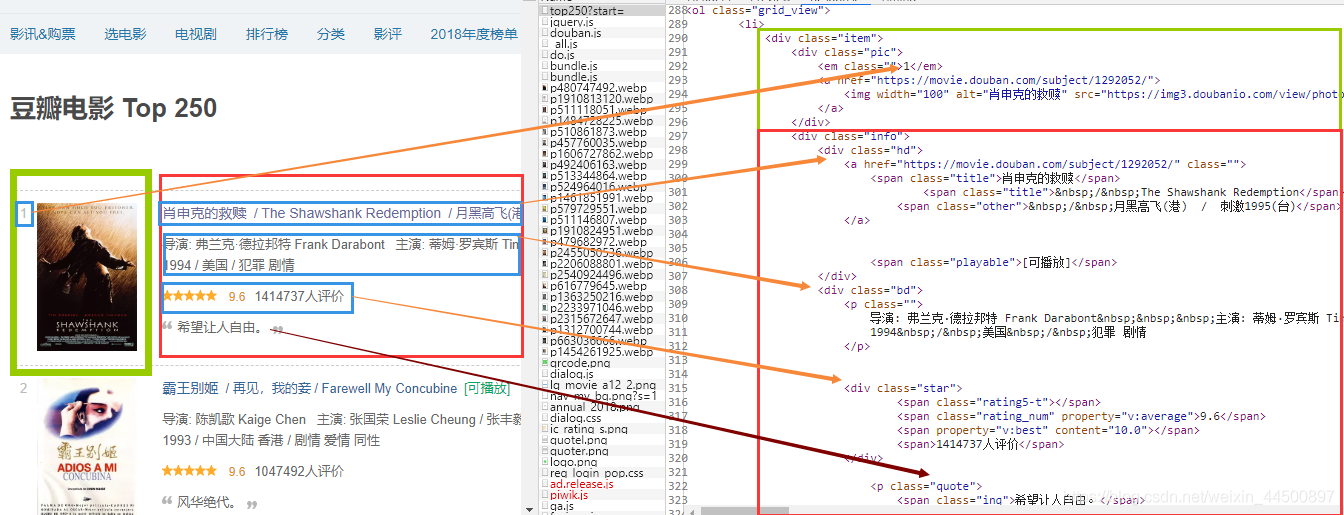
2.通过分析网页源码,我们可以看到,所有电影都归到[ol]标签下。每一个[li]下包含一部电影。以下图为例,分析出对应关系后,便可以针对性的提取出想要的信息。
3.豆瓣电影top250共有10页数据,对比url发现,每翻一页就获取25个电影信息,所以只需做10个循环,就可以获取到250部电影的所有信息

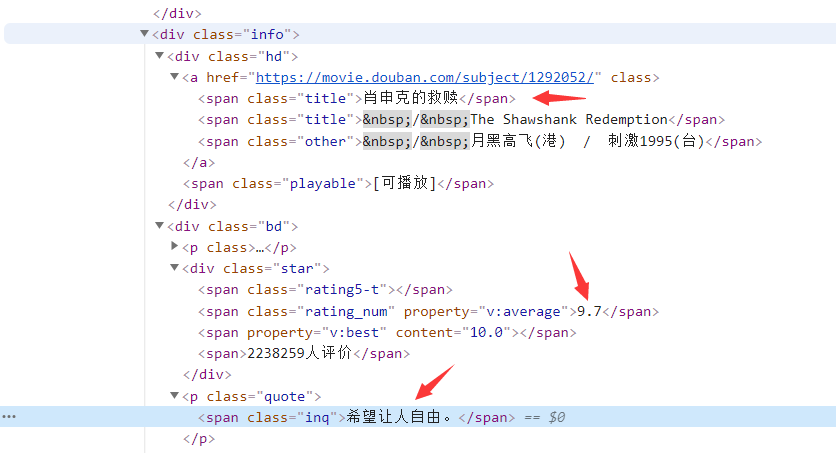
3.使用xpath定位到电影名,,排名,评分和电影标语的位置:

4.获取数据
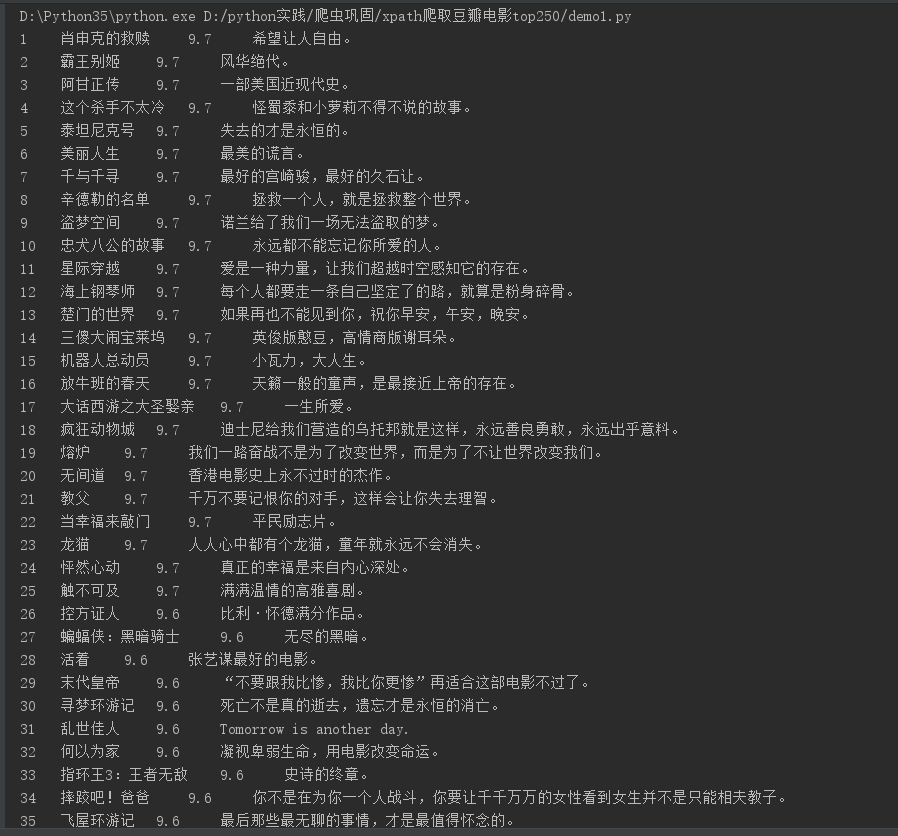
5.数据如下:
代码如下:
import requests from lxml import etree headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36', 'Host': 'movie.douban.com' } def get_one_page(base_url): for i in range(10): url=base_url+str(i*25)# response=requests.get(url, headers=headers) html=etree.HTML(response.content) items = html.xpath('//ol/li/div[@class="item"]') for item in items: try: rank=item.xpath('./div[@class="pic"]/em/text()')#提取电影的排名 title=item.xpath('./div[@class="info"]/div[@class="hd"]/a/span/text()')#提取电影名 quote=item.xpath('./div[@class="info"]//p[@class="quote"]/span/text()')#提取quote score=item.xpath('//div[@class="star"]/span[contains(@class,"rating_num")]/text()') if len(quote)==0: quote=[" "] print(rank[0]+" ", title[0]+" ", score[0]+" ", quote[0]+" ", )#注意到xpath返回的都是list。 except : print("出错!") pass if __name__ == '__main__': url = 'https://movie.douban.com/top250?start=' get_one_page(url)