1.获取小说页的url地址: http://www.shuquge.com/txt/8659/2324752.html
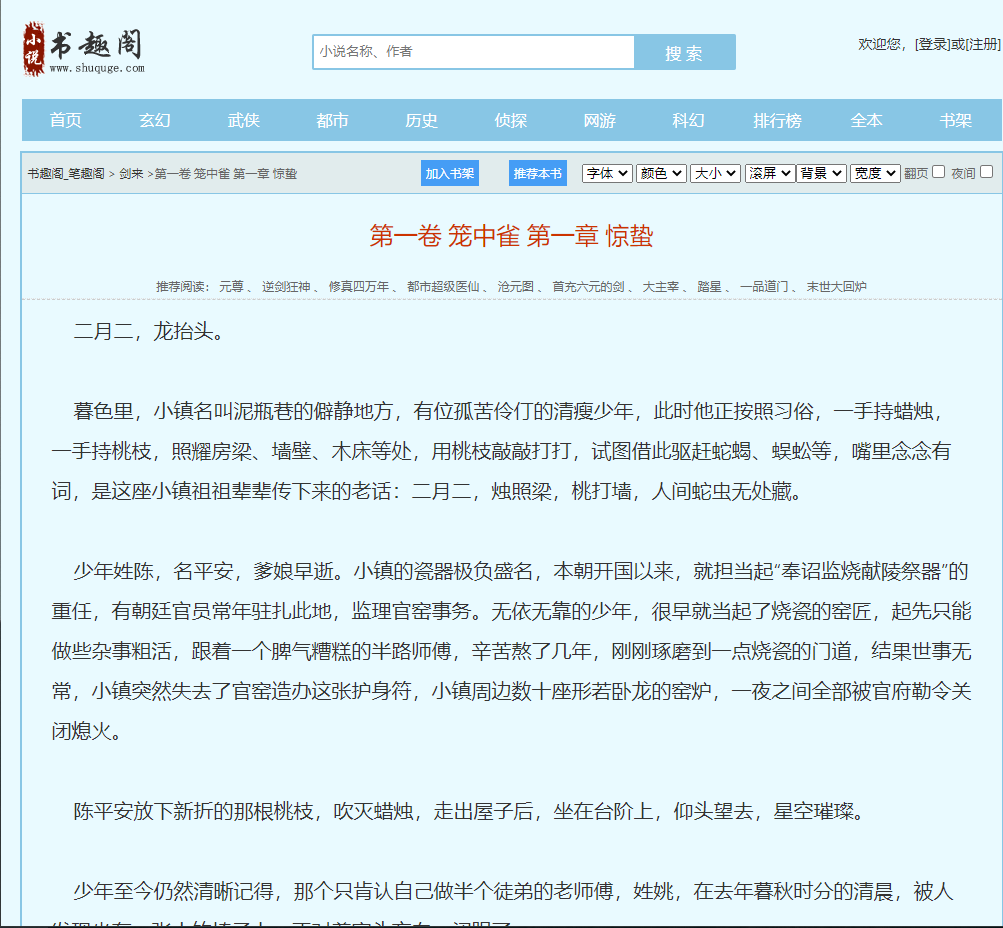
2.使用parsel解析获取到的地址
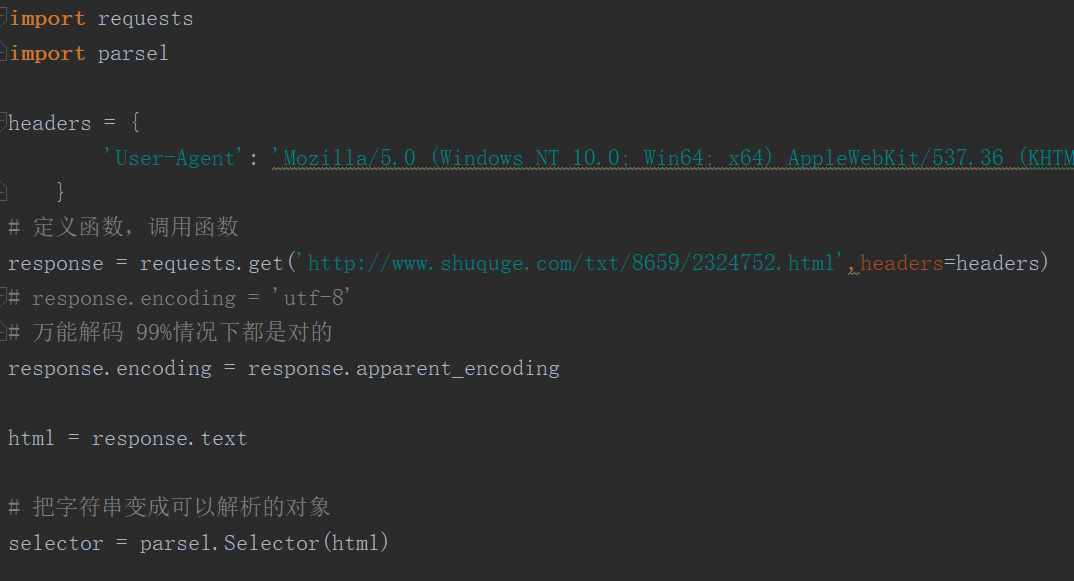
3.这里用css属性提取到标题和小说的文本
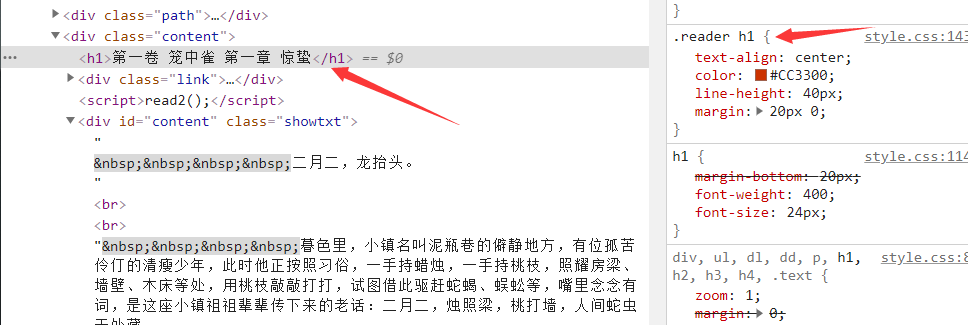

4.对爬取数据进行遍历

5.保存写入文件:

6.爬取数据如下:

7.代码如下:
import requests import parsel headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36' } # 定义函数,调用函数 response = requests.get('http://www.shuquge.com/txt/8659/2324752.html',headers=headers) # response.encoding = 'utf-8' # 万能解码 99%情况下都是对的 response.encoding = response.apparent_encoding html = response.text # 把字符串变成可以解析的对象 selector = parsel.Selector(html) # get 获取对象里面的文字内容 # 属性提取器 attr (:text(提取文本)) h1 = selector.css('.reader h1::text').get() # print(h1) content = selector.css('.showtxt::text').getall() # print(content) # xpath 路径提取器 # h1 = selector.xpath('//h1/text()').get() # # content = selector.xpath('//*[@class="showtxt"]//text()').getall() # 去除每一个空白字符 把它遍历出来 lines = [] for c in content: lines.append(c.strip()) # print(h1) # print(lines) # str join 字符串的合并方法 text = ' '.join(lines) print(text) # mode模式 write 写入 a append 追加写入 # h1 每次都在变 所以会写成多个文件 file = open(h1 + "txt", mode="a", encoding='utf-8') file.write(h1) file.write(' ') file.write(text) file.write(' ') file.close()