第 11 章 Page Object 设计模式
11.1 什么是 PO
PO 是 Page Object 的缩写,中文翻译为「页面对象模式」。它是一种设计模式,其目的是为 Web UI 测试创建对象库。在这种模式下,应用涉及的每一个页面应该定义为一个单独的类。类中应该包含此页面上的页面元素对象和处理这些元素对象所需要的方法等。方法的命名也有一定的规则,比如方法命名要能清楚、正确地表明此方法的作用或者行为。
举个例子,我们要定义一个方法,目的是回到应用首页,那么就可以把它命名为「getHomePage()」,这样通过方法的名字就可以很清楚地知道方法的具体功能。
PO 的优点如下:
(1)PO 提供了页面元素操作和业务流程相分离的模式,可以使测试的代码结构比之前清晰,可读性强。
(2)更方便地复用对象和方法。
(3)对象库是独立于测试用例的、统一的对象库,可以通过集成不同的工具类来达到不同的测试目的。比如集成 UnitTest 可以用来做单元测试自动化/功能测试;同时也可以集成 JBehave/Cucumber 等来做验收测试。
(4)使得整体自动化测试的优化变得更容易一些,如果有某个页面的元素需要变更,那么就可以直接更改封装好的页面元素类即可,而不用更改调用它的其他测试类/代码。这样整个的代码维护成本也会缩减。
PO 的核心就是分层的思想,把同属于一个页面的元素都放在一个页面类中。比如,对于登录页面,可以用三种不同的类来体现这种分层的思想,达到 PO 的目的。即我们以页面为单位,将某一个页面中的元素控件等全部提炼出来并封装成相应的方法,形成一个个可以被调用的对象。
11.2 PO 实战
笔者觉得,如果要真正掌握 PO 的精髓,至少需要掌握两点:一是对被测系统要有充分的认识,特别对需要纳入自动化测试的场景或者功能点等要有一个清晰的判断和划分;二是需要实战,实践是检验真理的唯一标准,实战才能体现出真正的自动化的意义。
本节选择第 10 章的项目实战的案例,笔者将一步一步地顺着项目的脉络带大家循序渐进地熟悉 PO 的思想和进一步重构代码的过程,把自动化测试代码的重构和优化推向极致。
PO 项目的框架结构图,如图 11.1 所示,在图表上可以清晰地看到分层,每层的具体功能会在本章后面进行详细讲解。
图 11.1 是对 PO 项目总体框架的介绍,其中的核心层就是 PO 层,围绕着 PO 层,又新增了其他层级的实现。这样对于自动化测试会越来越清晰,也会降低后期维护的成本,进而提高自动化的程度。

图 11.1
Base 层主要定义了项目需要的基础方法,特别是一些基础操作,如元素 click 操作、send keys 操作,调用 JavaScript 脚本的方法和其他一些与基本浏览器相关的操作。
Base 层的一些函数调用了 Common 层的模块函数,需要先了解其 Common 层代码结构。
11.2.1 Common 层代码分析
Common 层主要包含处理 Excel 文件的方法,获取项目路径、测试系统 URL 的信息和框架执行相关日志功能的实现方法。接下来,将对具体实现细节和重要的知识点进行讲解。
(1)获取项目路径、测试系统 URL 方法,文件名为「function.py」,源码如下:


该部分代码运用了 os 和 configparse 两个 Python 模块,其中 os 模块主要功能是获取操作系统级别的目录/文件夹的操作和文件的操作(读取,写入等);而 configparse 模块在 Python 中的主要功能是读取配置文件。方法 project_path 的功能是获取项目的当前目录。这里也涉及 Python 方法的命名规范,通常 method_name 都是小写,如果需要多个词汇组合就用下画线「_」连接。而方法 config_url 的功能是获取被测系统的网址信息,其中涉及自动化项目的配置文件「config.ini」,其内容结构如图 11.2 所示,其中 URL 值即是项目中被测系统的网址(携程网火车票网址)。

图 11.2
以上「function.py」脚本执行结果如图 11.3 所示,测试代码在代码文件中,结果证明函数功能运行正常。
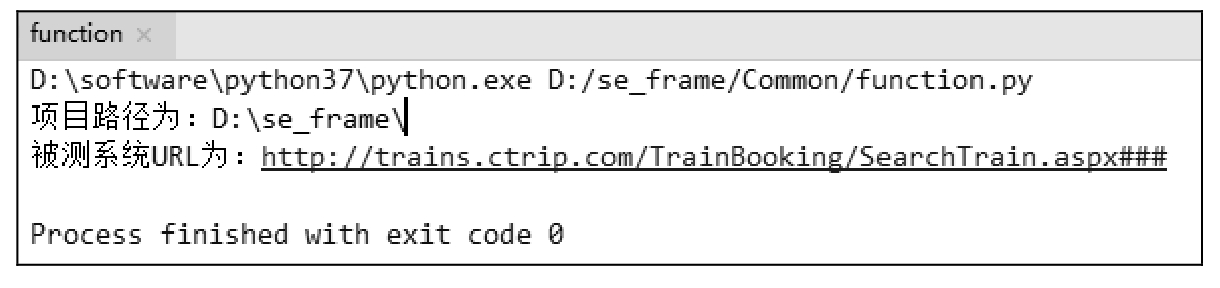
图 11.3
(2)创建日志类,便于在项目中添加日志信息,文件名为「log.py」。其主要函数为 log,作用是返回一个 logger 对象,而项目测试代码在使用的时候,可以直接调用其返回对象,使用者只需要关注日志的具体内容即可,不需要清楚日志的内部实现。其中比较重要的几点是,需要设置日志文件的文件名命名方式;日志文件存放路径的设置;日志输出内容格式的设定,此步骤会设定日志内容的格式和布局等信息,是日志功能的核心,具体参见如下源码:

测试结果如图 11.4 所示。
从测试结果来看,日志写在了项目主目录的「/Logs/2019_05_02_log.log」下,如图 11.5 所示。

图 11.4
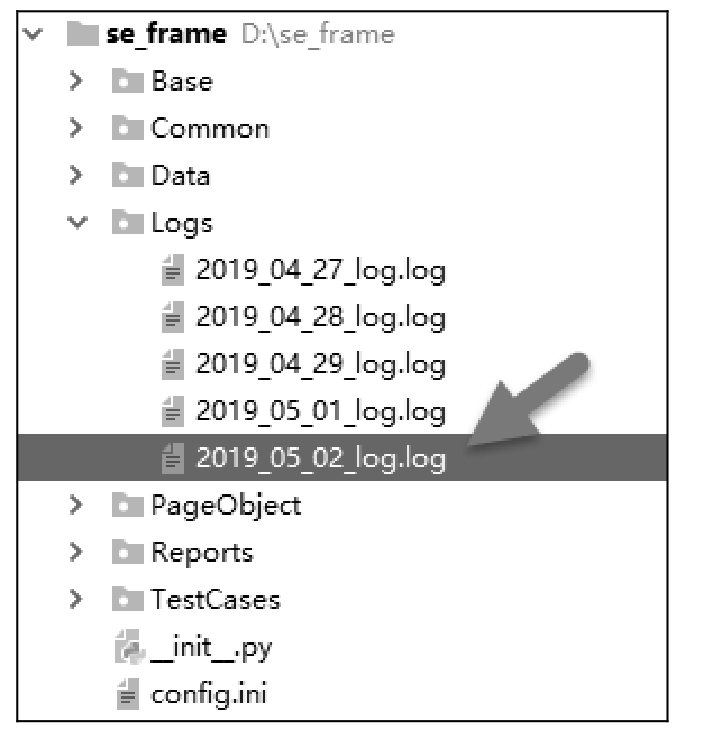
图 11.5
日志文件内容如图 11.6 所示。

图 11.6
(3)处理测试数据文件(Excel),代码文件名为「excel_data.py」。源码如下:


在上面这段代码中,主要方法为 read_excel,即读取存储在 Excel 文件中的测试数据进行自动化测试,方法最后返回字典对象。如果读者觉得还是不方便,也可以继续对字典对象进行处理。
读取方法调用了 Python xlrd 代码模块,如果要使用此模块,需要安装 xlrd,其安装步骤在 10.1.3 节中已有介绍,这里不再赘述。在项目中用到的测试数据如图 11.7 所示。
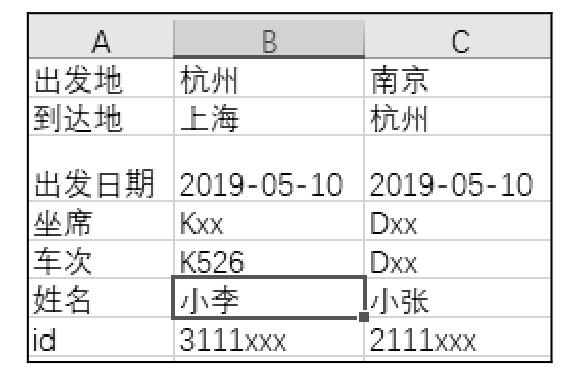
图 11.7
以上测试代码「print(data)」返回的是字典对象,字典对象的细节为「{0: [『出发地』,『到达地』,『出发日期』,『坐席』,『车次』,『姓名』,『id』],1: [『杭州』,『上海』,『2019-05-10』,『Kxx』,『K526』,『小李』,『3111xxx』],2: [『南京』,『杭州』,『2019-05-10』,『Dxx』,『Dxx』,『小张』,『2111xxx』]}」;测试代码「print(data.get(1))」返回的是列表对象,细节为「[『杭州』,『上海』,『2019-05-10』,『Kxx』,『K526』,『小李』,『3111xxx』]」。
11.2.2 Base 层代码分析
Base 层代码在项目中涉及底层操作,如对 click、send_keys 及 clear 等事件的封装,可以提高代码的复用性。文件名为「base.py」,主要包含定位元素方法 findele,方法 findele 返回的结果是元素定位的语句,该函数用参数*args 可以接收任意多个非关键字参数,参数的类型是元组。代码如下:

此外 Base 层还包含另外一个文件(base_unit.py),其目的是抽离单元测试中的 setUp 和 tearDown 方法,源码如下:

11.2.3 PageObject 层代码分析
这里是 PO 的核心层。该层不但涉及代码技术,还涉及对项目业务的分析,进而对相关的页面进行分析。在业务分析方面,首先,分析要进行 PO 的页面;其次,对在每个范围内的页面进行细节分析(如自动化需要用到的元素和相关的操作方法及页面之间的关联情况等)。
在本书中,笔者将继续使用第 10 章的案例作为 PO 实战案例。案例的主要测试场景包含火车票搜索页面、车次订购页面和订单信息页面等。通过项目分析,需要关注在携程网购买火车票的如下三个页面即可:
(1)搜索火车票页面。
(2)预订火车票页面。
(3)订单页面。
1.搜索火车票页面
在搜索火车票页面,主要涉及如下页面元素:
(1)出发城市(输入框),如图 11.8 第 1 处标记所示。
(2)到达城市(输入框),如图 11.8 第 2 处标记所示。
(3)出发日期(输入框),如图 11.8 第 3 处标记所示。
(4)开始搜索(按钮),如图 11.8 第 4 处标记所示。
(5)搜索类别(分为单程、往返和中转三种类型,如图 11.8 所示第 5 处标记),在项目中以单程票类型为例做演示。
以上 5 个元素,定义了搜索火车票的方法 search_train,根据出发城市、到达城市和出发时间参数实现搜索车次信息的功能。

图 11.8
搜索火车票页面的代码(文件名为「search_page.py」)如下:


根据以上代码分析,类 SearchPage 继承了 Base 类。此外它还定义了页面基础的操作,比如方法 search_leave 的功能是返回出发城市的元素定位语句,它继承调用了 Base 类下面的 findele 方法,而此方法的传入参数分别为 By.ID 和「notice01」。By.ID 是属于 from selenium.webdriver.common.by 模块下的应用,其返回字符串「id」作为方法 search_leave 的第 1 个参数,是为了指明此元素的定位方式是通过元素 id 属性进行的。方法的第 2 个参数是传入的字符串「notice01」,它表明元素 id 的属性值为「notice01」。其他元素定位的相关方法 search_arrive、search_date、search_btn 及 search_current,与方法 search_leave 类似,这里不再展开。
创建方法 search_js 是为了执行 JavaScript 代码,创建 jsvalue 是为了得到完整的 JavaScript 代码,第 2 行代码通过调用 Base 父类中的 js 方法来执行第 1 行代码得到的 JavaScript 代码。
创建 search_train 方法是为了根据出发城市、到达城市和出发日期等参数来搜索火车车次信息,最后返回当前的 URL 信息。
2.预订火车票页面
预订火车票页面,主要涉及以下页面元素:
(1)预订车票按钮(超链接 <a>)。
(2)动车复选框(HTML dd 标签)。
(3)关闭浮层窗口。
(4)非登录订票超链接。
以上为预订火车票页面所涉及的元素,具体如图 11.9 所示,如箭头所示,上面标注了前 2 种页面元素;第 3 种页面元素如图 11.10 所示,作用是关闭广告浮层;第 4 种页面元素如图 11.11 所示,页面方法的功能是订购火车票,方法名为 book_btn,方法执行完会返回当前浏览器的 URL。

图 11.9

图 11.10

图 11.11
页面文件名为「book_page.py」,其源码如下:


下面对上述代码进行分析,页面类 BookPage 继承了基础类 Base。方法 book 的作用是返回订购 K526 次列车无座车位的预订按钮的定位语句(用到了 XPath 定位方式),如图 11.9 所示,使用了 Base 类中的 findele 方法,这里不再赘述。方法 book_close 的作用是返回广告浮层的关闭按钮的定位语句,在测试的时候需要关闭广告浮层,便于进行元素的定位和自动化测试的顺利进行。方法 book_nologin 的作用是返回「不登录,直接预订」超链接的元素定位语句。
方法 book_btn 用来实现订购火车票,它调用了 book_close、book()及 book_nologin 方法,而且用到了 try 语句,这样能更好地对火车票查询结果进行管理。如果查询失败,会打印日志「车次查询失败」,并返回当前浏览器的 URL。
3. 订单页面
车票预订成功后,会跳转到订单页面,此页面以「乘客姓名信息」文本框为例,
页面文件名为「order_page.py」,代码如下:


代码分析,OrderPage 类继承了 Base 类,方法 detail_name 用来返回乘客信息框对象;方法 user_info 用来实现输入乘客姓名。
11.2.4 TestCases 层代码分析
TestCases 层的作用是管理测试用例和执行测试,相当于测试的总入口。在项目中,可以将测试管理的代码和测试用例的相关代码都维护在这里。
如上所述,这里首先了解一下测试总入口文件的代码,代码文件名为「suite.py」,源码如下:

代码分析:在测试管理过程中,用到了 HTMLTestRunner 模块,该模块其实是 Python UnitTest 模块功能的一个扩展。为了更加方便地生成测试报告,通常需要和单元测试 UnitTest 模块结合在一起使用。
首先,在代码中定义了项目测试用例(测试代码)的存放地址,即项目主目录下的「TestCase」文件夹。然后,定义了测试用例规则,在规则中定义了测试目录、测试文件的模式等。最后,定义了测试报告的文件路径和文件名等规则,测试报告存放地址为项目主目录下的「Reports」文件夹。
11.2.5 Data 层分析
在项目中 Data 目录是测试数据的存放地址,在这里可以维护测试数据,比如本项目中的测试数据文件「testdata.xlsx」等,这样分层存放是为了让项目的可维护性强、整体的条理性强。测试数据有时是自动化测试的驱动因素,因此对 Data 层的管理和维护就显得特别重要。从笔者的经验出发,Data 层通常有以下几点需要注意:
(1)测试数据和测试用例分离不是一直都是高效的,不能为了分离而分离,这样反而得不偿失。如有些测试用例所用的测试数据很少,并且这些数据有极少的概率会被其他测试用例用到,这种情况就不需要大费周章地将数据与用例分离。
(2)数据文件类型的选型。在本书中关于数据的存储,笔者使用的是 Excel。但是这不一定是最佳的方式,也不一定适用于每一种测试场景。读者要根据项目实际需要进行灵活的运用,笔者在第 10 章也讲解了不同的文件类型的使用。举例来说明这种观点:在测试场景中有时需要测试上传功能,在测试数据中需要定义清楚数据字段等头部信息且上传文件信息又比较大(如 10 万行数据),此时用 CSV 就比 Excel 的优势明显。分析原因,CSV 保存的是文本文件,而 Excel 保存的是二进制文件,在软件的可操作性或者易用性来说,Excel 优势比不上 CSV;在大数据量的场景下,对 Excel 的处理没有 CSV 处理得高效。
(3)数据维护要有条理性。关联性比较强的测试用例的测试数据最好放在一起,便于维护。如存放在一个 Excel 文件的不同 Sheet 页或一个文本文档的不同列中。
11.2.6 Logs 层分析
Logs 层主要存放在项目运行过程中产生的日志文件中。日志文件记录了在每次测试执行过程中的详细信息,便于分析定位测试过程中的异常。框架的日志在一定程度上反映了框架是否运行在正确的轨道上。关于日志层面的维护,笔者的一些建议如下:
(1)日志级别或者频度要设置合理。在测试用例中,需要对打印日志操作进行筛选,对于一些重要的点最好打印日志。
(2)在框架中笔者建议添加一些系统级别的日志。如对系统资源进行监控的日志,便于一些非框架问题的定位。笔者曾经遇到过由磁盘空间问题导致的框架异常。
(3)日志的管理。如日志的清理,是需要考虑的问题。
11.2.7 Reports 层分析
Reports 层主要存放在项目执行过程中产生的测试报告文件,测试报告是对测试结果的总结。Reports 层的报表可能不只是一个测试报告文件那么简单,需要探究报告上所呈现内容的准确性、完整性和持续性是否有问题。后续报表功能的迭代不能影响之前的测试结果或报告。
如果自动化测试项目的周期比较长,可能需要对测试结果进行数据存储,如存储在 Mongo DB 或者 MySQL 数据库等。
11.2.8 其他分析
除以上各层外,在项目主目录下还需要维护一个配置文件(文件名:config.ini),该文件是整个项目配置项需要用到的,该文件在本章的 Common 层已经做过介绍。后续如果还有其他项目需要添加,直接在该文件中进行维护即可。
11.2.9 PO 项目执行
通过以上对 PO 项目的介绍,相信读者朋友已经对此 PO 项目有了大致的了解。现在需要把项目跑起来,然后查看测试报告和日志等是否达到了预期。
执行时,需要执行 TestCases 下的 suite.py,关于这一点在 11.2.4 节中对 suite.py 已经做过简单的介绍。suite.py 是该项目的入口,我们需要对 suite.py 了解,下面来看一下它的源码:


通过以上源码分析发现,此次执行测试的测试用例脚本是以「Train」开头的.py 文件,测试报告存放在项目默认的路径「xx/Reports」下。
为简单起见,这里只写一个测试文件「TrainTest.py」。测试代码如下:
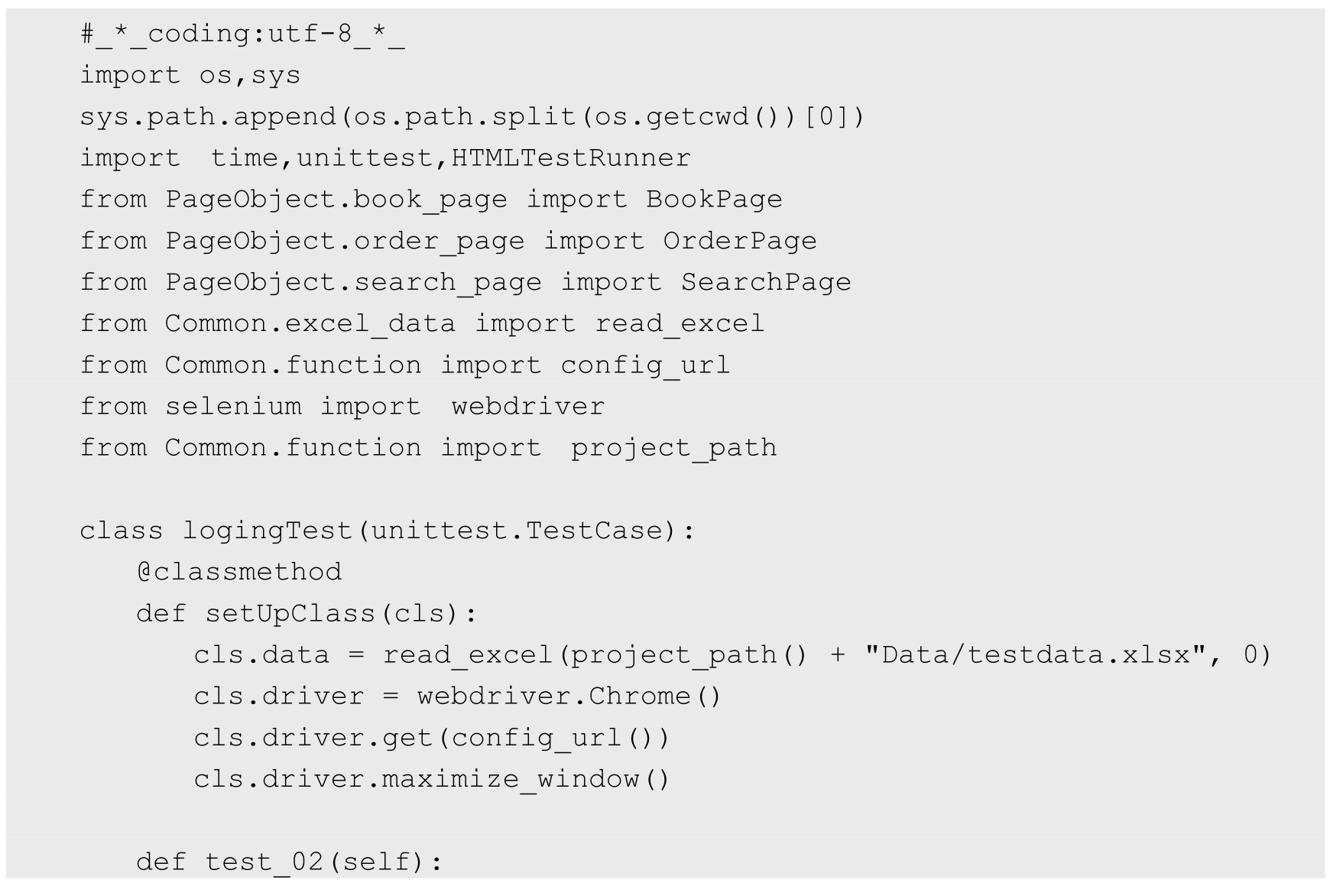

对测试代码进行简单的分析,本测试用例包含了 3 个测试方法 test_02、test_03 和 test_04。测试结果文件如图 11.12 所示,而测试报告的内容如图 11.13 所示,测试脚本运行通过。假若测试脚本没有通过,可以在报告中或者测试日志中寻找错误的详细信息,帮助我们分析问题。
图 11.12
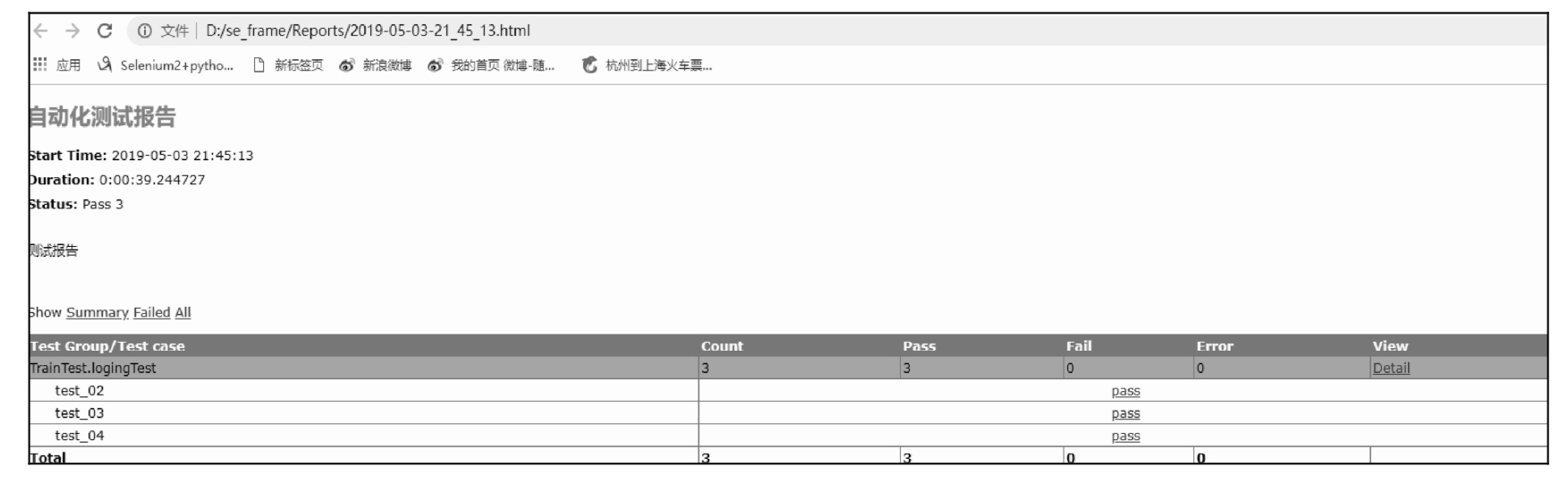
图 11.13