第 7 章 Selenium WebDriver 进阶应用
本章将讲解 WebDriver 中的一些高级应用,掌握了这些知识点,读者在自动化测试的职业发展中可以往前更进一步。
7.1 滑块操作
滑块作为安全验证机制的一种,经常在登录或者注册时涉及。但是在自动化测试时,需要想办法用代码的方式来处理滑块。下面以携程网的注册页面为例来演示如何操作滑块。网站 URL 是「https://passport.ctrip.com/user/reg/home」,代码实现要遵循的流程如表 7.1 所示。
表 7.1

7.1.1 携程注册业务分析
需要同意携程用户注册协议和隐私政策,如图 7.1 所示。

图 7.1
之后在用户注册页面显示滑块验证功能,如图 7.2 所示。
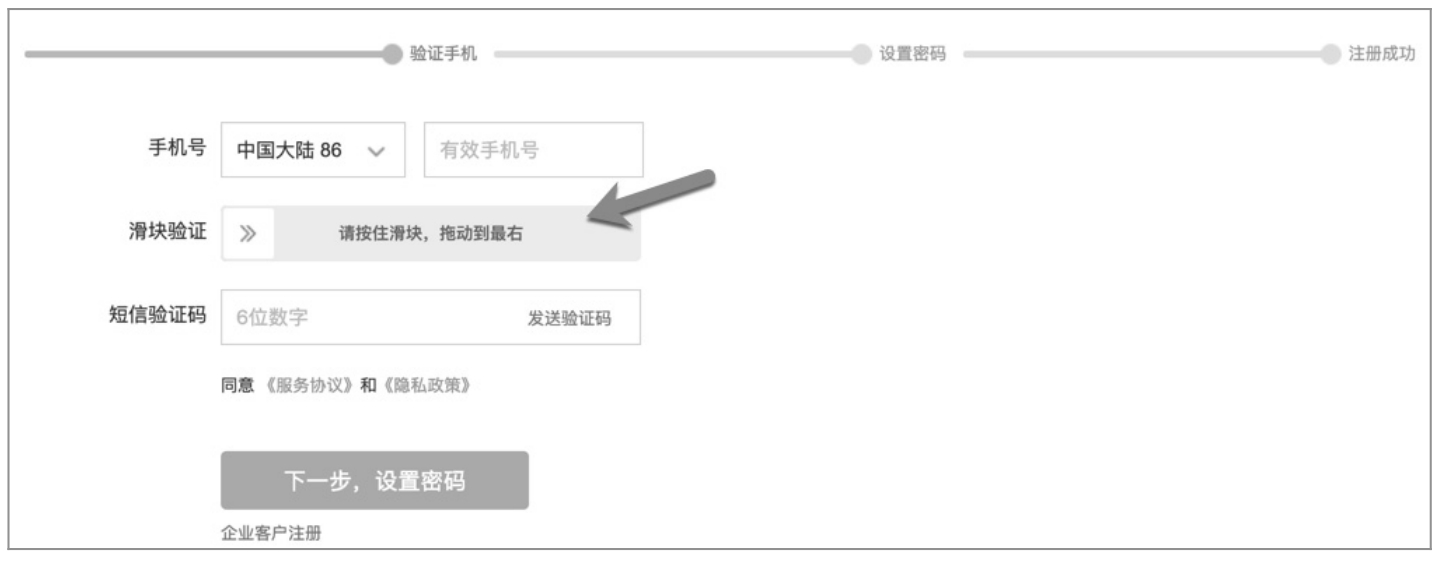
图 7.2
7.1.2 滑块处理思路
Selenium 中对滑块的操作基本是采用元素拖曳的方式,而这种方式需要用到 Selenium 的 Actionchains 功能模块。
先分别求出滑块按钮和滑块区域的长度和宽度。在以下代码运行后,控制台分别打印这两个元素的长度与宽度,代码如下:
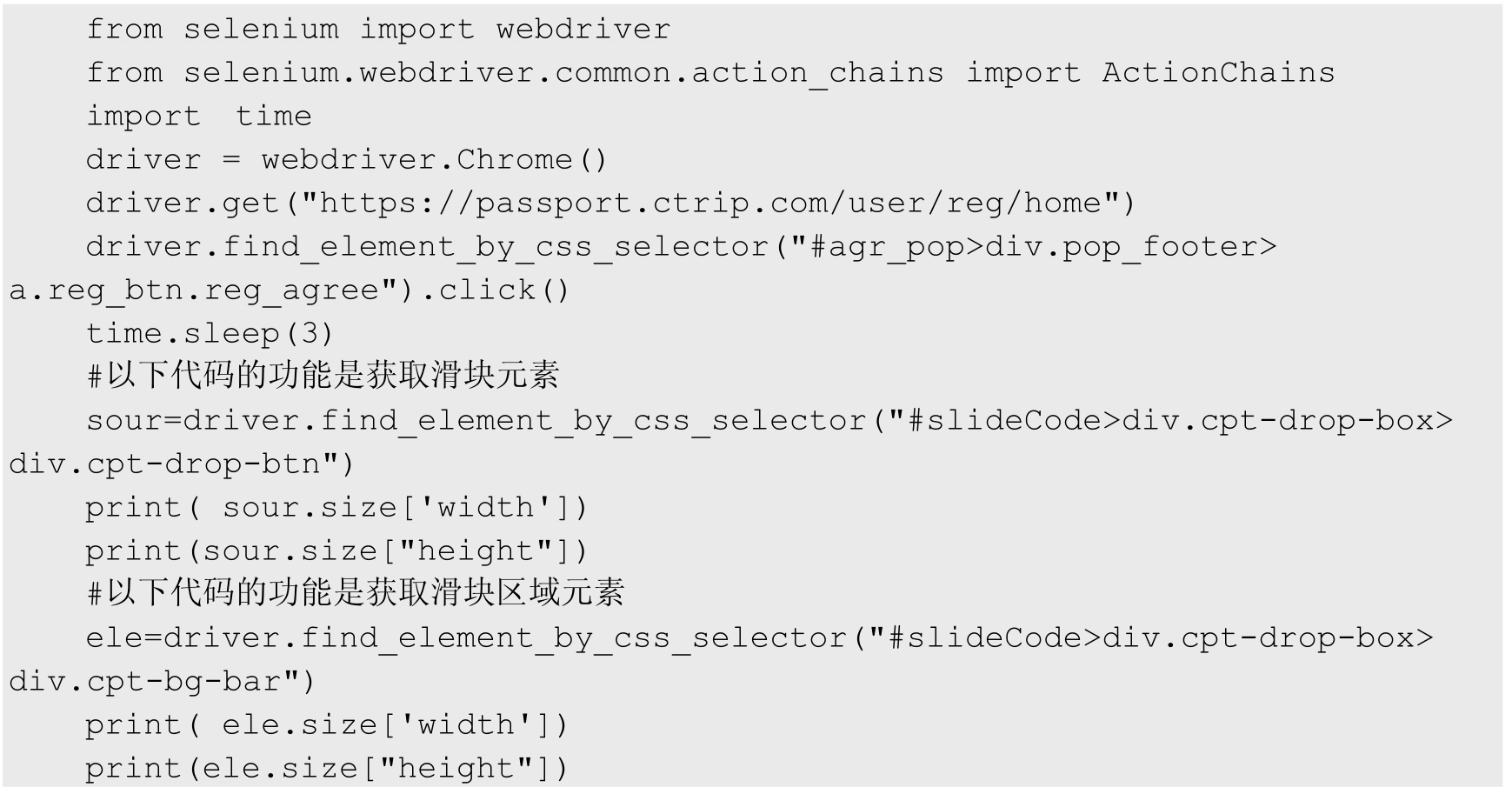


from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains import time driver = webdriver.Chrome() driver.get("https://passport.ctrip.com/user/reg/home") driver.find_element_by_css_selector("#agr_pop > div.pop_footer > a.reg_btn.reg_agree").click() time.sleep(3) #以下代码的功能是获取滑块元素 sour=driver.find_element_by_css_selector("#slideCode > div.cpt-drop-box > div.cpt-drop-btn") print(sour.size['width']) print(sour.size["height"]) #以下代码的功能是获取滑块区域元素 ele=driver.find_element_by_css_selector("#slideCode > div.cpt-drop-box > div.cpt-bg-bar") print(ele.size['width']) print(ele.size["height"])
代码执行后控制台输出的结果如图 7.3 所示,说明滑块按钮和滑块区域的高度都是 40px,而它们的宽度分别是 40px 和 300px。

图 7.3
下面来实现执行滑块的操作,如注册业务分析中提到的那样,执行滑块的拖曳操作需要使用到功能模块 ActionChains 的 drag_and_drop_by_offset 方法。完整的演示代码如下:
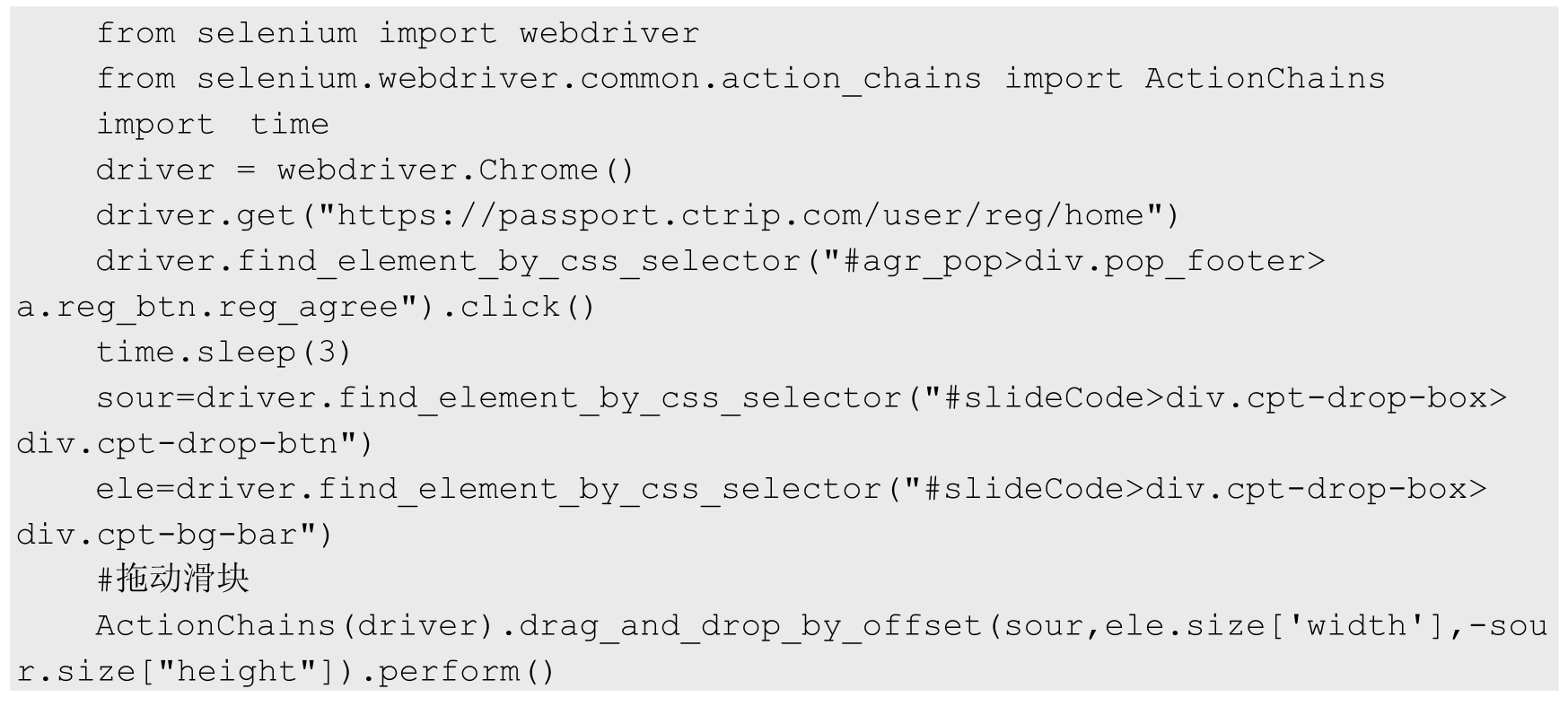
执行以上代码,结果如图 7.4 所示,滑块条变成绿色,证明滑块拖曳操作成功。

图 7.4
from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains import time driver = webdriver.Chrome() driver.get("https://passport.ctrip.com/user/reg/home") driver.find_element_by_css_selector("#agr_pop > div.pop_footer > a.reg_btn.reg_agree").click() time.sleep(3) # #以下代码的功能是获取滑块元素 sour=driver.find_element_by_css_selector("#slideCode > div.cpt-drop-box > div.cpt-drop-btn") # print(sour.size['width']) # print(sour.size["height"]) # #以下代码的功能是获取滑块区域元素 ele=driver.find_element_by_css_selector("#slideCode > div.cpt-drop-box > div.cpt-bg-bar") # print(ele.size['width']) # print(ele.size["height"]) #拖动滑块 ActionChains(driver).drag_and_drop_by_offset(sour,ele.size['width'],sour.size["height"]).perform()
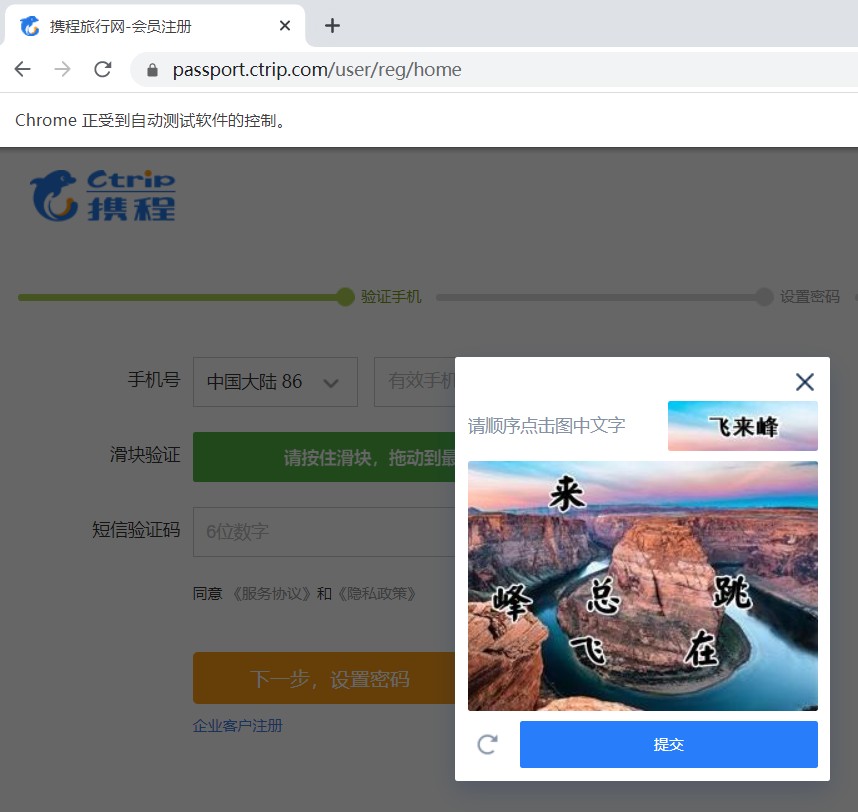
绕过验证码的测试思路参考:
http://www.cppcns.com/jiaoben/python/216777.html
https://www.cnblogs.com/jackzz/p/11443193.html
https://www.cnblogs.com/fengyiru6369/p/7513644.html
7.2 项目中的截图操作
本节主要介绍页面元素的截图操作,在构建实际项目的过程中经常会使用。一种场景是用在执行测试出错时,可以对报错的页面截屏,便于自动化测试人员追踪并解决问题;另一种场景是验证码截图,在后面的章节中会详细讲解。
7.2.1 页面截图
页面截图相对比较简单,可以直接用 Selenium 自带的方法「save_screenshot」。下面以去哪儿网登录页面为例,对整个页面进行截图,代码如下:

运行后在工程目录下生成图片,如图 7.5 所示。
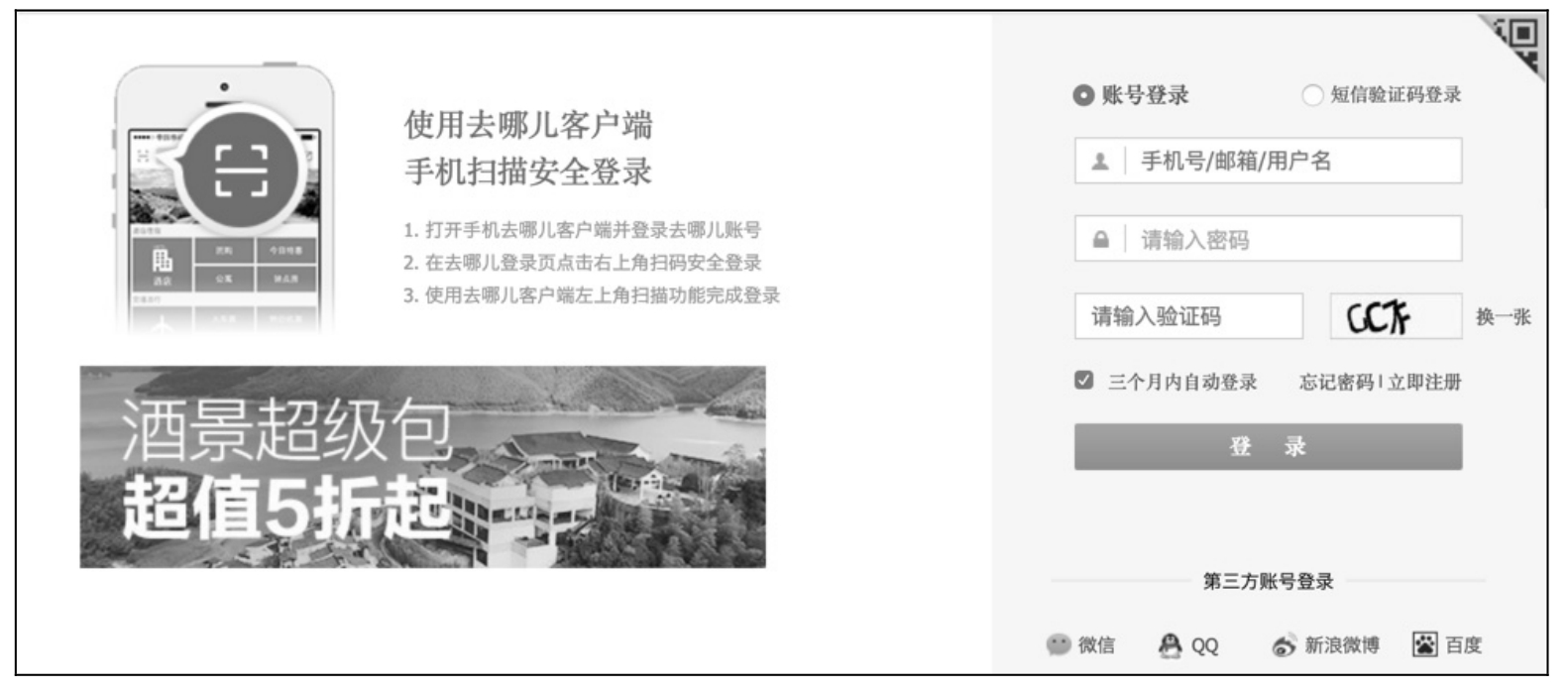
图 7.5
7.2.2 元素截图
验证码如果要用图像识别等方式去处理,需要先对验证码元素进行截图,我们先对整个页面截图,再通过验证码位置裁切的方式获取验证码图片。元素截图需要安装第三方 pillow 库,安装命令为「pip install pillow」。以去哪儿网登录页面为例,代码如下:


代码运行后,项目工程目录下成功生成验证码图片「t.png」
from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains import time driver = webdriver.Chrome() driver.get("https://passport.ctrip.com/user/reg/home") driver.find_element_by_css_selector("#agr_pop > div.pop_footer > a.reg_btn.reg_agree").click() time.sleep(3) # #以下代码的功能是获取滑块元素 sour=driver.find_element_by_css_selector("#slideCode > div.cpt-drop-box > div.cpt-drop-btn") # print(sour.size['width']) # print(sour.size["height"]) # #以下代码的功能是获取滑块区域元素 ele=driver.find_element_by_css_selector("#slideCode > div.cpt-drop-box > div.cpt-bg-bar") # print(ele.size['width']) # print(ele.size["height"]) #拖动滑块 ActionChains(driver).drag_and_drop_by_offset(sour,ele.size['width'],sour.size["height"]).perform() #获得验证码图片BASE64 pic_small=driver.find_element_by_class_name("cpt-small-img") pic_big=driver.find_element_by_class_name("cpt-big-img") small_str = pic_small.get_attribute("src") big_str = pic_big.get_attribute("src")
7.2.3 验证码处理思路
验证码在当今的软件中应用非常广泛,如手机 App、网页网站等,很多地方在利用这种机制来规避一些安全和隐私问题。在进一步对验证码处理之前,需要了解一下 Python 的字典等对象。
字典采用键值对的形式来表示数据,键和值之间用冒号分隔,每个键值对之间用逗号分隔,整个字典数据用花括号{}括起来。通常我们看到的 JSON 格式的数据和字典数据类型的数据很像,但是其实两者之间有本质的区别,字典是 Python 的一种数据类型,而 JSON 仅仅是一种前端的数据格式而已。如下面的例子:
dic ={"android":"appium","web":"selenium","interface":"python interface automation"}
· 字典元素查找,如查找 key 为「android」的 value 值,方法是:dic.get(‘android’)
· 修改 key 对应的 value 值,方法是:dic['android']= 'appium test'
· 在字典中添加元素,如 dic['performance']= 'jmeter'
· 获取字典长度,如 len(dic),即得到字典有多少个键值对。
实例演示 Python 中遍历字典键值对的用法,源码如下:


执行结果如图 7.6 所示。

图 7.6
遍历字典键值对也有第二种写法,代码如下:

上述源码执行结果如图 7.7 所示。

图 7.7
修改字典的值,示例代码如下:

执行结果如图 7.8 所示,「Name」键的值为「Jason」。
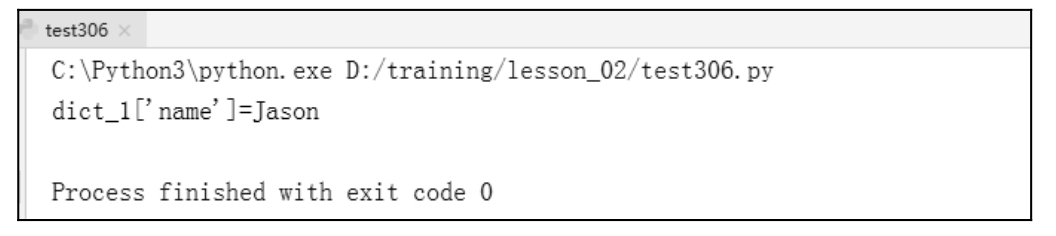
图 7.8
在字典中添加新的键值对,示例代码如下:

执行结果如图 7.9 所示。

图 7.9
下面进行删除字典元素操作,可以删除字典中的一个元素,也可以清空整个字典。以删除一个元素为例,代码如下:

在上述代码中,运用了 del 语句来删除键值对「'Name':'Jack'」。值得注意的是,字典的有些数值,如果不显式地转化,会产生类似「can only concatenate str (not 「int」)to str」的错误。因此,在 Python 中,常常利用内置函数「str(value)」进行显式转化。以上代码的执行结果如图 7.10 所示。

图 7.10
在自动化测试的过程中,有时候要求清空和删除整个字典。清空和删除是两个不太一样的操作,下面将进行具体讲解。
清空操作代码如下:

以上代码的执行结果如图 7.11 所示,在清空操作之后,字典对象还在,只是字典中没有键值对。

图 7.11
删除操作的代码如下:


以上代码用 del 语句实现了对字典的删除操作。执行结果如图 7.12 所示,并显示了错误。由此表明,原先的字典对象已经被彻底删除。删除和清空操作的区别也在于此。
以上是对列表、字典等对象的详细介绍。列表与字典对象在 Python 中是使用率比较高的一种对象。可以简单地将它理解为一种数据结构,目的就是存储数据,而存储位置是在内存中。

图 7.12
现在回到验证码的处理中来,其中的一种处理思路是通过 Cookie 操作的形式来绕过验证码甚至是二维码等安全机制。这种方法和思路相对来说简便一些。
下面我们通过百度网盘的登录场景来演示 Cookie 实现自动化登录。
(1)通过脚本抓取初次打开百度网盘首页的 Cookie(假如之前登录过,建议先清理一下 Cookie),代码如下:

执行以上代码得到 Cookie 的详情如下,从存储类型上看,这是一个字典类型的数据。
[{'domain': '.baidu.com','expiry': 1582881120.935221,'httpOnly': False,'name': 'BAIDUID','path': '/','secure': False,'value': '436A73EBC9EB9669DC86B75BE928E8B9:FG=1'}]
(2)手动登录百度网盘,再抓取一次 Cookie(脚本如下所示)。跟上一步的脚本相比,这里增加了一个在执行抓取 Cookie 操作之前的长时间等待。在等待的过程中,测试人员将手动登录百度网盘。

(3)比较一下两次得到的 Cookie 值的差别,找出哪些项是在第一次 Cookie 值中没有的。通过添加这些缺少的值,来实现自动化登录。比较 Cookie 差别的详细分析过程在这里就不一一描述了,自动化登录的脚本如下。


执行完以上代码,可以在浏览器中查看百度网盘是否已经自动登录。
另外一种思路是:用图像识别技术来处理验证码,将图片上的字符进行识别并转化成文本字符串。
在这之前,需要讲解一个第三方工具「斐斐打码」。斐斐打码是一个专业图形识别的平台,使用时需在其官网上申请账号,并下载 Python 接口代码。网址为「http://docs.fateadm.com/web/#/1?page_id=37」,关键代码如下:


以上代码解释如下:
· pd_id 为充值后 PD 账号,pd_key 为 PD 秘钥。
· pred_type 为验证码类型,其中 30400 为 4 位英文数字混合型,如图 7.13 所示。
· file_name 为验证码图片路径。
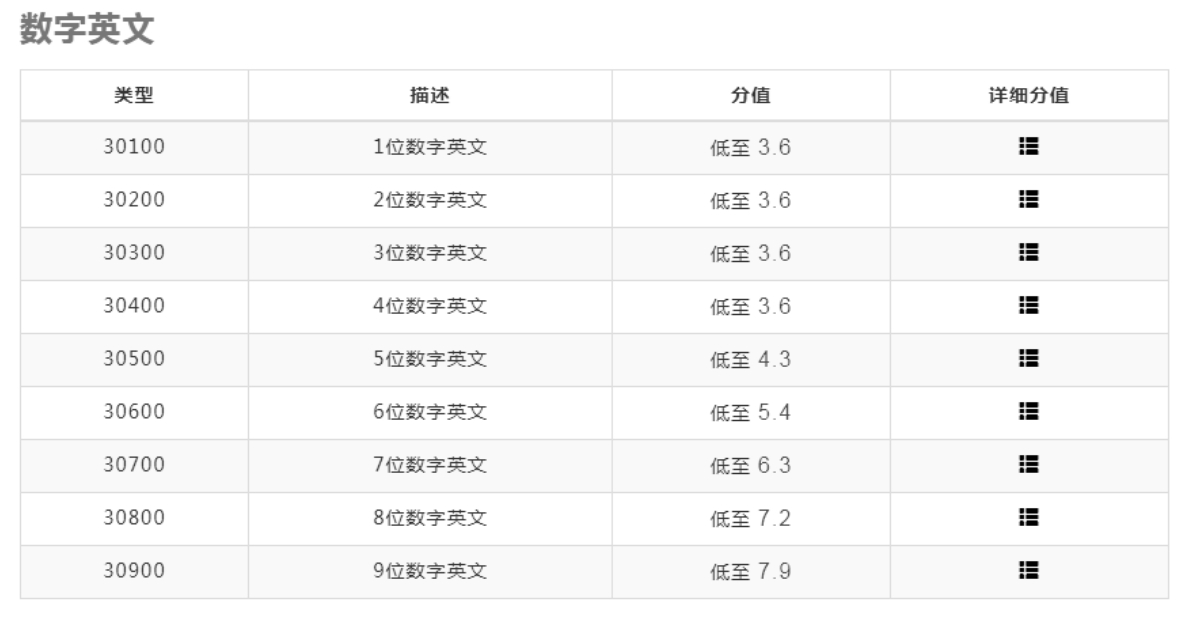
图 7.13
以图 7.5 验证码为例执行后,返回字符串类型结果,识别的验证码为第 2 行「gc7f」,如图 7.14 所示:
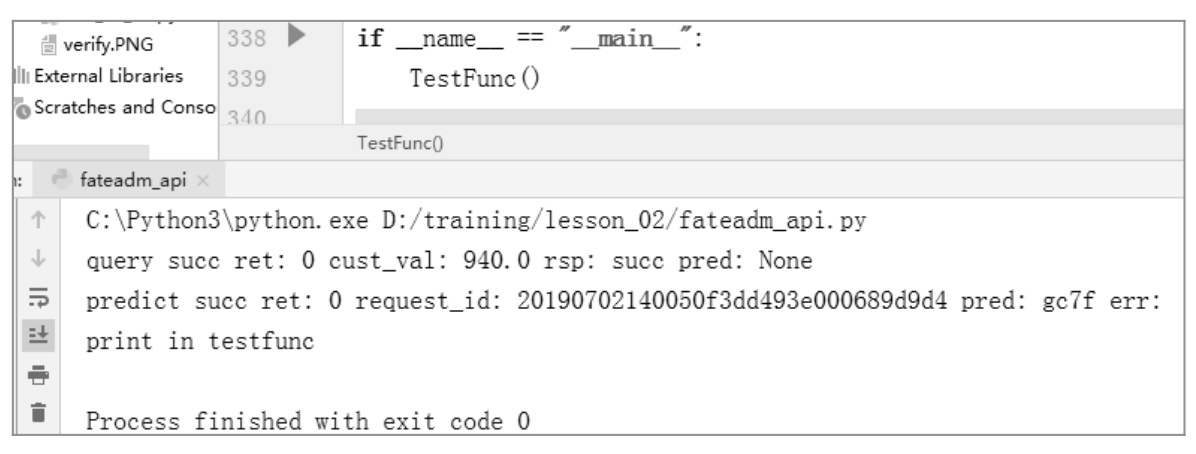
图 7.14
下面对以上两种方法进行总结。用 Cookie 方式实现相对来说比较简便,但因部分网站的安全机制,Cookie 无法实现自动登录,而图像识别没有限制。
7.3 Web 页面多窗口切换
在 Web 测试过程中,经常会打开多个窗口,Selenium 无法直接对新页面元素进行定位,需要切换句柄操作。以「hao123」网站为例,单击超链接「hao123 新闻」并单击「娱乐」版块。代码如下:

代码解释:通过「current_window_handle」方法获取当前窗口字符串,其中「window_handles」方法为当前所有窗口字符串且为列表类型,通过比较发现新窗口句柄为「handles[1]」。
7.4 元素模糊定位
元素模糊定位,从其名字基本可以知道这种元素定位的特性,即根据部分元素属性值来定位元素。因为有些元素的属性值是随机的,但同时又带有一定的规律性,这时为了提高测试代码定位元素的准确性,我们需要寻找其规律,然后集成到函数中进行重构。
下面是北京市行政区划相关的一个简单的 HTML 页面代码,代码文件名称为「beijing.html」,本节将以此页面为例,讲解元素模糊定位的相关知识点。

元素模糊定位即对页面元素属性值进行部分匹配而进行定位的方式。从以上 HTML 代码可以看出,区县信息的 id 属性值的字符串前半部分是固定的,但是后半部分的数字是随机的,在这种情况下比较适合使用元素模糊定位的方法。元素属性值的匹配方式主要有三种,分别为「starts-with」「ends-with」和「contains」。笔者准备以「starts-with」与「ends-with」两种方式进行讲解。
1.starts-with
创建如下脚本用于测试「starts-with」。


以上脚本执行结果将返回「Success」字样,表明元素定位成功。具体执行结果如图 7.15 所示。

图 7.15
2.contains
遵循以上测试「starts-with」的脚本写法,「contains」的脚本写法如下,以定位「西城区」超链接元素为例。

以上代码运行后结果如图 7.16 所示,结果表明利用「contains」定位方式定位元素成功。

图 7.16
7.5 复合定位
复合定位即定位一组元素,通过「find_elements_xx」方式实现定位,打开百度首页,单击「设置-> 搜索设置」,选择「搜索语言范围」,如图 7.17 所示。
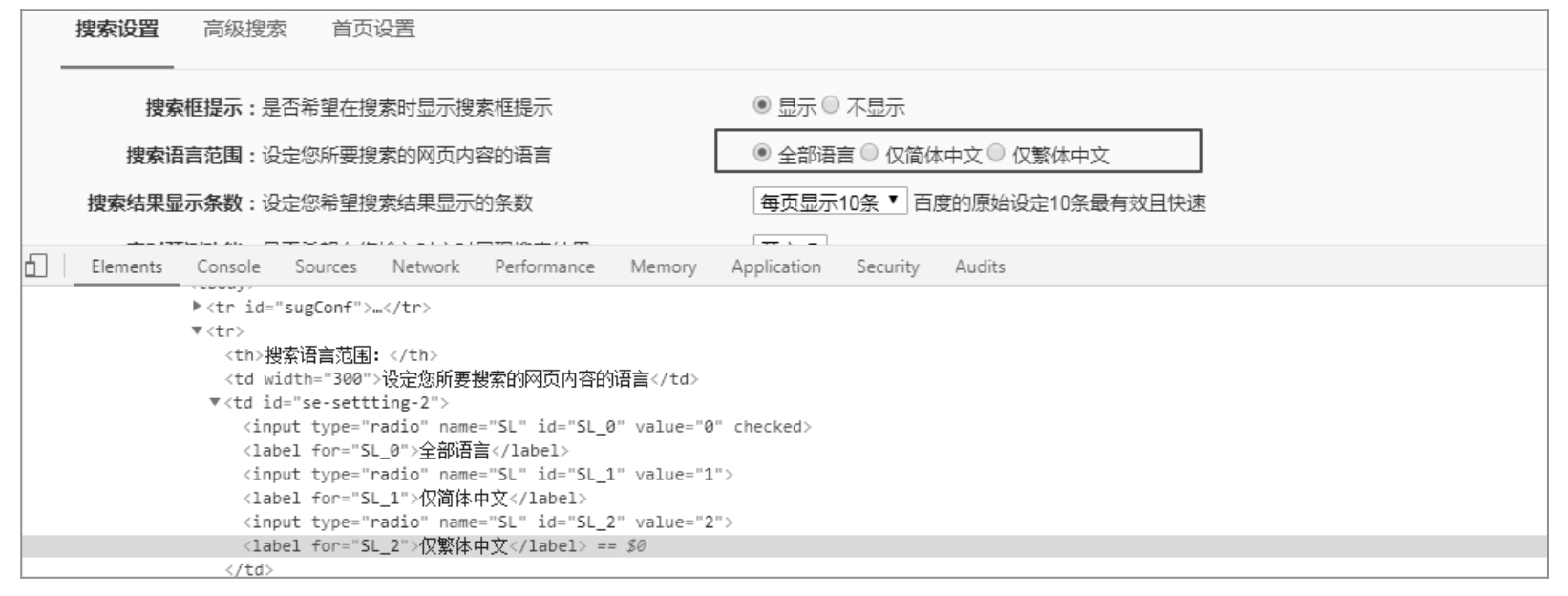
图 7.17
通过「find_elements_by_name」复合定位,定位对象是一个列表类型,只需对列表取值便可实现单击不同选项的功能,代码如下:
