正则化
在模型中加入正则项,防止训练过拟合,使测试集效果提升

Dropout
每次在网络中正向传播时,在每一层随机将一些神经元置零(相当于激活函数置零),一般在全连接层使用,在卷积层一般随机将整个通道置零而不是单个神经元
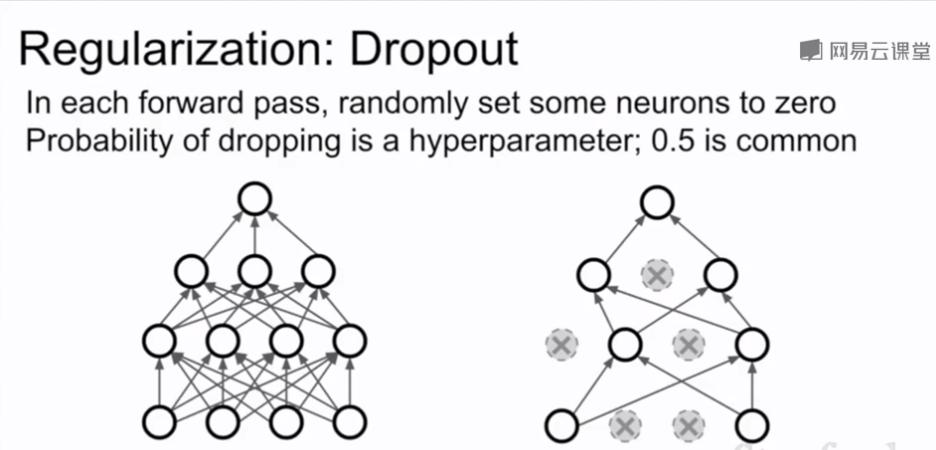

Dropout 的两种解释:
1.dropout避免了特征之间的相互适应,假如让网络识别一只猫,一个神经元学到了耳朵,一个学到了尾巴,另一个学到了毛,将这些特征组合在一起来判断是否是猫;Dropout以后模型不能通过这些特征组合来判断,需要通过不同的零散的特征来判断,某种程度上这抑制了过拟合
2.另一种解释是dropout的使用相当于在单一模型中进行了集成学习,dropout后可以看作在一个子网络中用所有神经元的子集进行运算,每次dropout不同的神经元就产生一个不同的子网络,最后相当于对一群共享参数的网络进行集成学习
在预测时,对于预测函数用dropout 的概率乘以输出层的输出平均测试时的随机性



Inverted dropout在训练时除以p,在预测时不改变,提升预测时的效率。
使用Dropout时,训练通常需要更长的时间,因为每次更新只是更新网络的子部分,但模型收敛后的鲁棒性更好

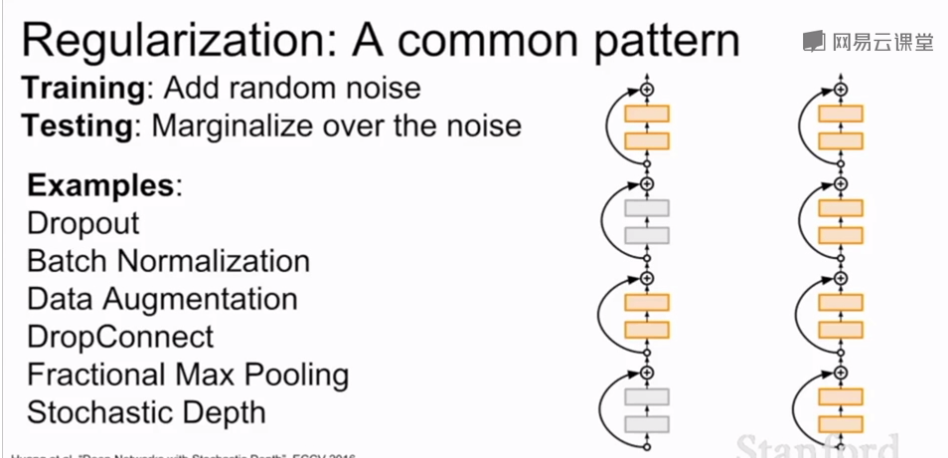
dropout和BN都会在训练时加入随机性和噪声以扰乱训练集防止过拟合于训练集,在测试时抵消这些随机性和噪声提高泛化能力。BN在训练时,一个数据点可能和其他不同的数据点出现在不同的mini-batches,对于单个数据点来说在训练过程中该点会如何被正则化具有一定的随机性,在测试时,通过基于全局估计的正则化来抵消这个随机性。有时BN已经足够正则化,不使用dropout;dropout的优点是可以调整p的值来控制正则化力度。
常用的正则化方法:
Q1:dropout操作后为何要乘一个系数?
Q2:从引入随机性的角度解释Dropout的正则化作用?
Q3:同上,试解释图像增强对网络训练的作用?
1.乘以系数是为了平均测试时的随机性
2.dropout避免了特征之间的相互适应,假如让网络识别一只猫,一个神经元学到了耳朵,一个学到了尾巴,另一个学到了毛,将这些特征组合在一起来判断是否是猫;Dropout以后模型不能通过这些特征组合来判断,需要通过不同的零散的特征来判断,某种程度上这抑制了过拟合
3.数据增强增加了数据多样性,
1