Optimization
随机梯度下降(SGD):


当损失函数在一个方向很敏感在另一个方向不敏感时,会产生上面的问题,红色的点以“Z”字形梯度下降,而不是以最短距离下降;这种情况在高维空间更加普遍。
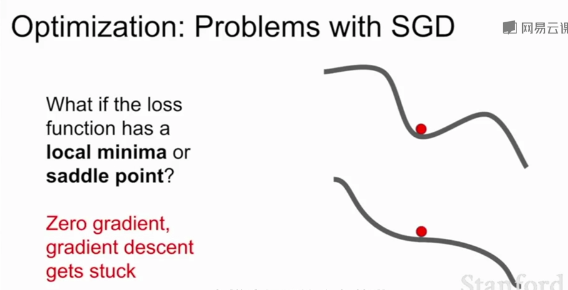
SGD的另一个问题:损失函数容易卡在局部最优或鞍点(梯度为0)不再更新。在高维空间鞍点更加普遍
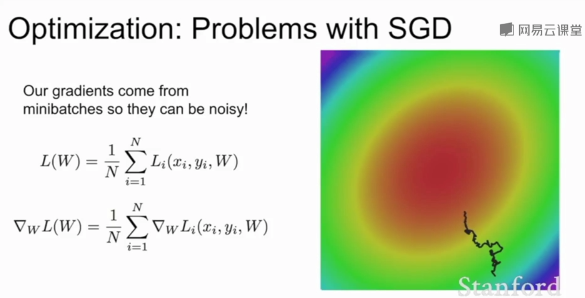
当模型较大时SGD耗费庞大计算量,添加随机均匀噪声时SGD需要花费大量的时间才能找到极小值。
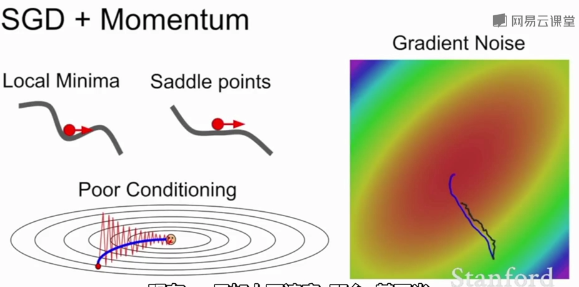
SGD+Momentum:
带动量的SGD,基本思想是:保持一个不随时间变化的速度,并将梯度估计添加到这个速度上,在这个速度方向上前进,而不是随梯度变化方向,给一个摩擦系数作为这个速度的衰减项。

这种方法解决了局部极小值和鞍点问题,尽管在局部极小值和鞍点任会有朝预定速度方向步进,且速度会随着时间的速度增加。
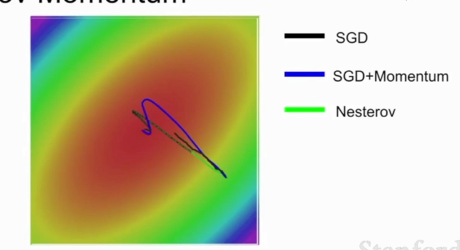
普通的Momentum更新是先估计当前梯度向量,取其和速度向量的和的方向作为真实参数更新的方向
Nesterov Momentum则相反,先取得速度方向的步进,再估计当前位置的梯度,随后回到原来位置,再根据两者的和作为真实参数更新的方向。在凸优化问题有良好表现


Nesterov Momentum不会剧烈的越过局部最小值
AdaGrad:
在优化过程中,需要保持一个在训练过程中的每一步的梯度的平方和的持续估计;与速度项不同,梯度平方项在训练时,会一直累加当前梯度的平方到这个梯度平方项,在更新参数向量时,会除以这个梯度平方项。

当一个维度上的梯度更新很小时会除以很小的平方项,梯度很大时则会除以很大的平方项;在一个维度上(梯度下降很慢的)训练会加快,在另一个维度方向上训练减慢;让各个参数得到相同程度的收敛。
随着时间的推移,梯度更新的步长会越来越小(梯度平方项随时间单调递增);在学习目标是一个凸函数的情况下,效果很好,到达极值点,步长越来越小最终收敛;非凸函数则会变得复杂
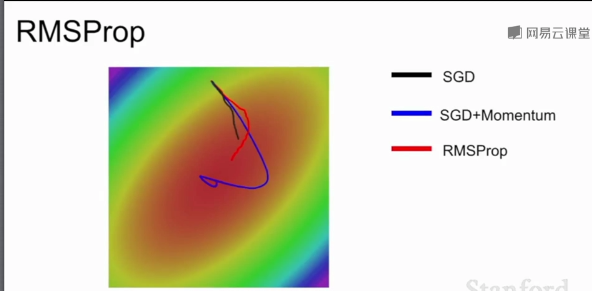
RMSProp:
不仅加上平方项,并让平方梯度按照一定比率下降,然后用1减去衰减了乘以梯度平方加上之前的结果。
随着训练的进行,步长会有一个良好的性质,与AdaGrad类似在一个维度上(梯度下降很慢的)训练会加快,在另一个维度方向上训练减慢,RMSProp让梯度平方衰减了,可能会造成训练一直在变慢。

RMSProp会慢慢调整梯度更新方向,SGD效果不好,SGD+Momentum会先绕过极小值再朝极小值方向前进,AdaGrad在较小学习率时可能会卡住。(凸优化问题)
Adam:
更新第一动量(类似SGD+Momentum中的速度)和第二动量(类似AdaGrad、RMSProp中的梯度的平方项)的估计值,第一动量的估计值等于梯度的加权和,第二动量的动态估计值是梯度平方的动态估计值,相当于速度项与梯度平方项的结合。

在最初的第一步,第二动量的初始值为0,第一步之后衰减值beta2=0.9或0.99,第二动量还是接近于0,除以第二动量后会得到很大的步长,可能导致初始化到一个难以收敛的区域。1e-7为的是分母不为0。
因此,Adam增加了一个偏置校正项避免出现开始时得到很大步长。

一般网络的都会使用Adam算法作为优化算法,它结合了SGD和RMSProp的优点。

学习率的选择:

一般选择学习率衰减策略,在训练的开始选择较大的学习率,然后随着步长衰减或指数衰减。

SGD+Momentum的学习率衰减很常见,Adam一般不使用学习率衰减,学习率衰减相当于二阶超参数,在开始时不使用,在训练达到一定瓶颈时再考虑使用。
一阶优化与二阶优化:




L-BFGS是一个二阶优化器

Adam是大多数情况下的默认选择,如果能承受整个批次的更新且没有很多随机性(如风格迁移),可以考虑L-BFGS
模型集成是提高测试集准确率的有效办法,通常选择一批不同的随机初始值上训练N个模型,测试时平均N个模型的结果,能够缓解过拟合。

Q1:随机梯度下降的随机指得是什么?
Q2:尝试解释为什么Adam通常会是一个更好的选择?(可以结合Momentum和RMSProb的优点解释)
1.随机梯度下降指的是从批量样本中随机选取一个样本,按照该样本梯度下降的方向进行梯度下降,
2.Adam的优点:可以解决局部最优和鞍点问题,且下降速度较快,平衡各特征梯度的大小
https://blog.csdn.net/weixin_40170902/article/details/80092628