
作者 | 文永亮
研究方向 | 目标检测、GAN
研究动机
这是一篇发表于CVPR2019的关于显著性目标检测的paper,在U型结构的特征网络中,高层富含语义特征捕获的位置信息在自底向上的传播过程中可能会逐渐被稀释,另外卷积神经网络的感受野大小与深度是不成正比的,目前很多流行方法都是引入Attention(注意力机制),但是本文是基于U型结构的特征网络研究池化对显著性检测的改进,具体步骤是引入了两个模块GGM(Global Guidance Module,全局引导模块)和FAM(Feature Aggregation Module,特征整合模块),进而锐化显著物体细节,并且检测速度能够达到30FPS。因为这两个模块都是基于池化做的改进所以作者称其为PoolNet,并且放出了源码:https://github.com/backseason/PoolNet
模型架构
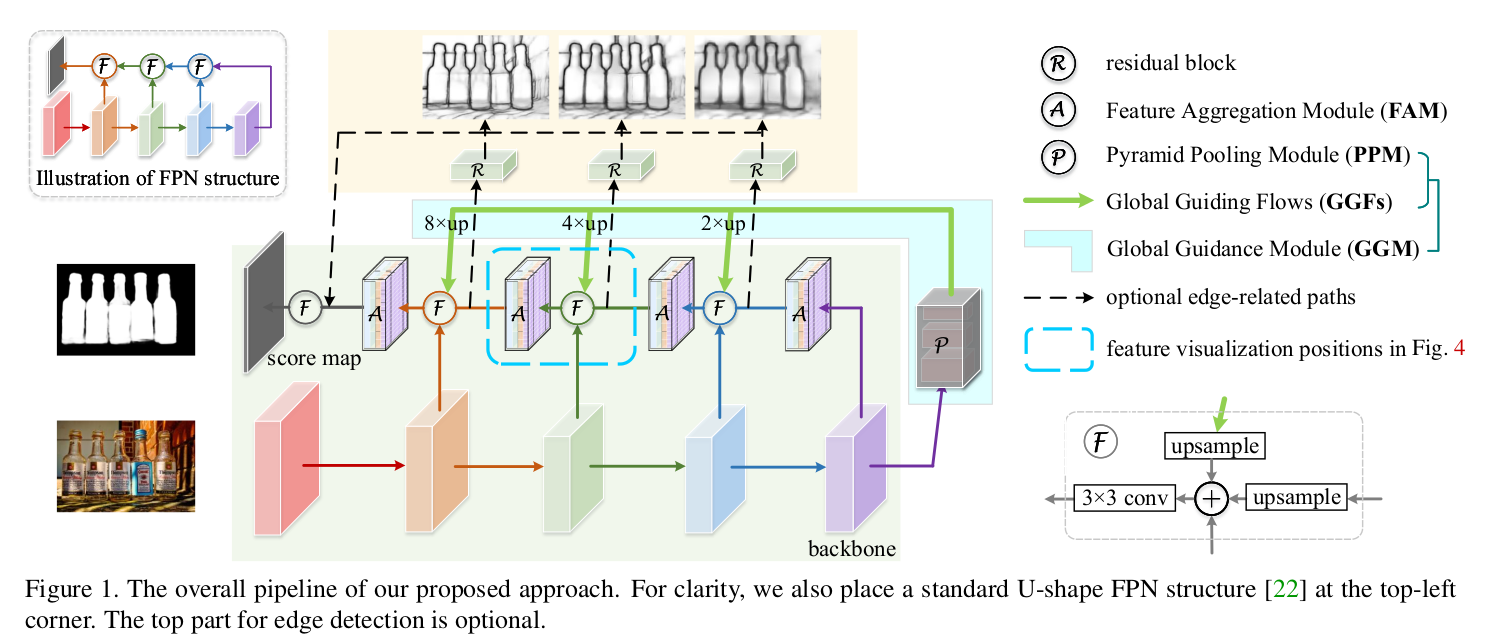
两个模块:
-
GGM(Global Guidance Module,全局引导模块)
我们知道高层语义特征对挖掘显著对象的详细位置是很有帮助的,但是中低层的语义特征也可以提供必要的细节。因为在top-down的过程中,高层语义信息被稀释,而且实际上的感受野也是小于理论感受野,所以对于全局信息的捕捉十分的缺乏,导致显著物体被背景吞噬,所以提出了GGM模块,GGM其实是PPM(Pyramid Pooling module,金字塔池化模块)的改进并且加上了一系列的GGFs(Global Guiding Flows,全局引导流),这样做的好处是,在特征图上的每层都能关注到显著物体,另外不同的是,GGM是一个独立的模块,而PPM是在U型架构中,在基础网络(backbone)中参与引导全局信息的过程。 其实这部分论文说得并不是很清晰,没有说GGM的详细结构,我们可以知道PPM[7]的结构如下:
如果明白了这个的话,其实GGM就是在PPM的结构上的改进,PPM是对每个特征图都进行了金字塔池化,所以作者说是嵌入在U型结构中的,但是他加入了global guiding flows(GGFs),即Fig1中绿色箭头,引入了对每级特征的不同程度的上采样映射(文中称之为identity mapping),所以可以是个独立的模块。
简单地说,作者想要FPN在top-down的路径上不被稀释语义特征,所以在每次横向连接的时候都加入高层的语义信息,这样做也是一个十分直接主观的想法啊。
- FAM(Feature Aggregation Module,特征整合模块)
特征整合模块也是使用了池化技巧的模块,如下图,先把GGM得到的高层语义与该级特征分别上采样之后横向连接一番得到FAM的输入b,之后采取的操作是先把b用{2,4,8}的三种下采样得到蓝绿红特征图然后avg pool(平均池化)再上采样回原来尺寸,最后蓝绿红紫(紫色是FAM的输入b)四个分支像素相加得到整合后的特征图。
- 帮助模型降低上采样(upsample)导致的混叠效应(aliasing)
- 从不同的多角度的尺度上纵观显著物体的空间位置,放大整个网络的感受野
第二点很容易理解,从不同角度看,不同的放缩尺度看待特征,能够放大网络的感受野。对于第一点降低混叠效应的理解,用明珊师姐说的话,混叠效应就相当于引入杂质,GGFs从基础网络最后得到的特征图经过金字塔池化之后需要最高是8倍上采样才能与前面的特征图融合,这样高倍数的采样确实容易引入杂质,作者就是因为这样才会提出FAM,进行特征整合,先把特征用不同倍数的下采样,池化之后,再用不同倍数的上采样,最后叠加在一起。因为单个高倍数上采样容易导致失真,所以补救措施就是高倍数上采样之后,再下采样,再池化上采样平均下来可以弥补错误。
实验结果
论文在常用的6种数据集上做了实验,有ECSSD [8], PASCALS[9], DUT-OMRON [10], HKU-IS [11], SOD [12] and DUTS [13], 使用二值交叉熵做显著性检测,平衡二值交叉熵(balanced binary cross entropy)[14]作为边缘检测(edge detection)。
以下是文章方法跟目前state-of-the-arts的方法的对比效果,绿框是GT,红框是本文效果。可以看到无论在速度还是精度上都有很大的优势。
参考文献
[1]. Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In CVPR, 2017. 1, 3
[2]. Tiantian Wang, Ali Borji, Lihe Zhang, Pingping Zhang, and Huchuan Lu. A stagewise refinement model for detecting salient objects in images. In ICCV, pages 4019–4028, 2017. 1, 3, 6, 7, 8
[3].Nian Liu and Junwei Han. Dhsnet: Deep hierarchical saliency network for salient object detection. In CVPR, 2016.1, 2, 3, 7, 8
[4]. Qibin Hou, Ming-Ming Cheng, Xiaowei Hu, Ali Borji, Zhuowen Tu, and Philip Torr. Deeply supervised salient object detection with short connections. IEEE TPAMI, 41(4):815–828, 2019. 1, 2, 3, 5, 6, 7, 8
[5]. Tiantian Wang, Ali Borji, Lihe Zhang, Pingping Zhang, and Huchuan Lu. A stagewise refinement model for detecting salient objects in images. In ICCV, pages 4019–4028, 2017. 1, 3, 6, 7, 8
[6]. Tiantian Wang, Lihe Zhang, Shuo Wang, Huchuan Lu, Gang Yang, Xiang Ruan, and Ali Borji. Detect globally, refine locally: A novel approach to saliency detection. In CVPR, pages 3127–3135, 2018. 1, 3, 6, 7, 8
[7]. Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In CVPR, 2017. 1, 3
[8]. Qiong Yan, Li Xu, Jianping Shi, and Jiaya Jia. Hierarchical saliency detection. In CVPR, pages 1155–1162, 2013. 1, 5, 8
[9]. Yin Li, Xiaodi Hou, Christof Koch, James M Rehg, and Alan L Yuille. The secrets of salient object segmentation. In CVPR, pages 280–287, 2014. 5, 7, 8
[10]. Chuan Yang, Lihe Zhang, Huchuan Lu, Xiang Ruan, and Ming-Hsuan Yang. Saliency detection via graph-based manifold ranking. In CVPR, pages 3166–3173, 2013. 5, 6, 7, 8
[11]. Guanbin Li and Yizhou Yu. Visual saliency based on multiscale deep features. In CVPR, pages 5455–5463, 2015. 2, 5, 6, 7, 8
[12]. Vida Movahedi and James H Elder. Design and perceptual validation of performance measures for salient object segmentation. In CVPR, pages 49–56, 2010. 5, 6, 7, 8
[13]. Lijun Wang, Huchuan Lu, Yifan Wang, Mengyang Feng, Dong Wang, Baocai Yin, and Xiang Ruan. Learning to detect salient objects with image-level supervision. In CVPR, pages 136–145, 2017. 5, 7, 8
[14]. Saining Xie and Zhuowen Tu. Holistically-nested edge detection. In ICCV, pages 1395–1403, 2015. 6