五一机房的专题是字符串问题,自己刚好也在学习字符串匹配,于是就打算写篇关于最近学的几个经典的算法的 (Blog) ~
嗯,还是先甩定义
模式匹配
是数据结构中字符串的一种基本运算,给定一个子串,要求在某个字符串中找出与该子串相同的所有子串,这就是模式匹配。——参考自 (Baidupedia)
熟悉几个名词
- 模式串:给定的子串 (P)
- 匹配串:待查找的字符串 (T)
- 失配:按位匹配的过程中,某一位不匹配时称当前位置失配
接下来会介绍两种算法
- (KMP):解决单个模式串的匹配问题的一种算法
- (AC) 自动机:解决多个模式串的匹配问题的一种算法
(KMP)
甩定义
(KMP) ((Knuth)-(Morris)-(Pratt))
即克努斯-莫里斯-普拉特算法,该算法可在一个主文本字符串 内查找一个词的出现位置。此算法通过运用对这个词在不匹配时本身就包含足够的信息来确定下一个匹配将在哪里开始的发现,从而避免重新检查先前匹配的字符。
这个算法是由高德纳和沃恩·普拉特在1974年构思,同年詹姆斯 (·H·) 莫里斯也独立地设计出该算法,最终由三人于 (1977) 年联合发表。——参考自 (Wikipedia)
好了,举栗子时间到~
设模式串 (P=) " (abcabd) " ,匹配串 (T=) " (abcabcabd) " ,(i) 和 (j) 分别表示当前匹配完的模式串 (P) ,匹配串 (T) 的指针(即字符串下标,个人习惯,从 (1) 开始算起),初始时,(i=1) ,(j=1)
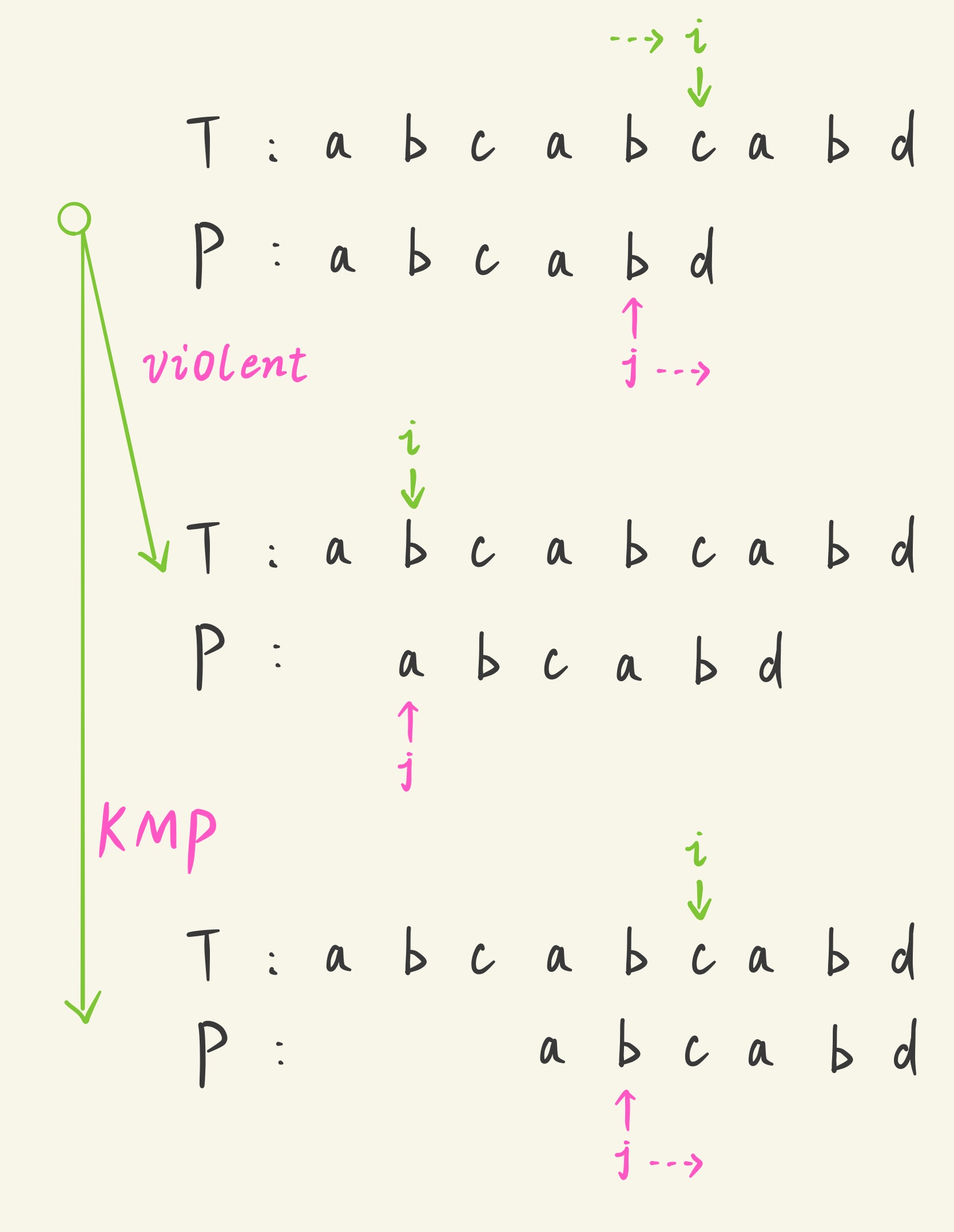
如图,当 (i=5) ,(j=5) 时, (T[1,5]) 和 (P[1,5]) 恰完全匹配,现在先让 (i) 往后移一位,即 (i=6) ,显然 (T[i] eq T[j+1]) ,(j) 后移一位会造成失配。
如果我们暴力去匹配,此时应该将 (i) ,(j) 置为此次匹配的初值,再让 (i) 后移一位,重新开始匹配,这样的复杂度让人难以接受。
有没有什么好的办法呢?我们发现,可以保持 (i) 不变, 让 (j) 直接跳转至 (2) ,理由很简单:对于 模式串 (P) ,位置 (j=5) 的前缀 (P[1,4]) 有公共的前后缀 (P[1,2]) ,(P[2,4]) ,(j) 跳转完后,就可以继续看 (j) 后移一位能否与 (i) 匹配,因为跳转后的位置应该比 (j) 要靠前,特别地,只有一个字符时前后缀完全覆盖,跳转位置应为 (0) 。
这里,(j) 的跳转位置只与模式串 (P) 有关,我们完全可以预处理出模式串 (P) 每一个位置的下一位失配后接下来的跳转位置。处理出的跳转数组又称失配数组,一般用 (next) 表示,我的代码中简称为 (nxt) 。
- (nxt[i]) :满足 (P[1,x]=P[i-x+1,i]) 的最大 (x)
拿上面的栗子算一下,(next[1,6]={0,0,0,1,2,0})
(PS):实际应用中,因为跳转后还是要后移,有一些做法是选择先后移再跳转,并定义 (next[i]):满足 (P[1,x]=P[i-x,i-1]) 的最大 (x) ,比如 (kuangbin) 的板子。 一开始我两个都看了然后傻傻分不清
下面给出关键的代码
代码中,(p) 就是指针 (j) ,(s_1) 就是匹配串,长度为 (len_1) ,(s_2) 就是模式串,长度为 (len_2) 。
Code :模式匹配的过程
void mp_count(void){
int p=0; //指针初始化为0
for(int i=1;i<=len1;i++){
while(p>0&&s1[i]!=s2[p+1]) p=nxt[p]; //下一位失配且p能往前跳转时则跳转
if(s1[i]==s2[p+1]) p++; //当前位置匹配成功,p后移
if(p==len2){ //匹配成功
printf("%d
",i-len2+1); //输出位置
p=nxt[p]; //继续匹配
}
}
}
Code :(next) 数组的预处理
void nxt_init(void){ //实际上就是模式串自我匹配的过程
int p=0; //指针初始化为0
/*
nxt[1]=0,表示指针无法更往前跳转,下面我们从nxt[2]开始处理
*/
for(int i=2;i<=len2;i++){
while(p>0&&s2[i]!=s2[p+1]) p=nxt[p]; //当下一位失配且能往前跳转时则跳转
nxt[i]=s2[i]==s2[p+1]?++p:p; //当前位置匹配成功,p后移
}
}
结合代码模拟一下应该能弄明白吧~
贴一个板子题链接+代码:P3375 【模板】KMP字符串匹配
Code
#include <bits/stdc++.h>
using namespace std;
const int N=1e6+5;
const int M=1e6+5;
char s1[N];
char s2[M];
int len1,len2;
int nxt[M];
void nxt_init(void);
void mp_count(void);
int main(void){
scanf("%s%s",s1+1,s2+1);
len1=strlen(s1+1);
len2=strlen(s2+1);
nxt_init();
mp_count();
for(int i=1;i<=len2;i++) printf("%d ",nxt[i]);
putchar('
');
return 0;
}
void nxt_init(void){
int p=0;
for(int i=2;i<=len2;i++){
while(p>0&&s2[i]!=s2[p+1]) p=nxt[p];
nxt[i]=s2[i]==s2[p+1]?++p:p;
}
}
void mp_count(void){
int p=0;
for(int i=1;i<=len1;i++){
while(p>0&&s1[i]!=s2[p+1]) p=nxt[p];
if(s1[i]==s2[p+1]) p++;
if(p==len2){
printf("%d
",i-len2+1);
p=nxt[p];
}
}
}
到这里,我们的 (KMP) 就算完...才怪了~
上述的 (KMP) 算法,其实是 (MP) 算法。什么?这不是 (KMP) ?那讲它干嘛?其实,所谓的 (KMP) 和 (MP) 相比,区别只有在 (next) 数组的处理上做了一些优化。至于为什么现在很多都直接管这个叫 (KMP) ... 我也不知道呢
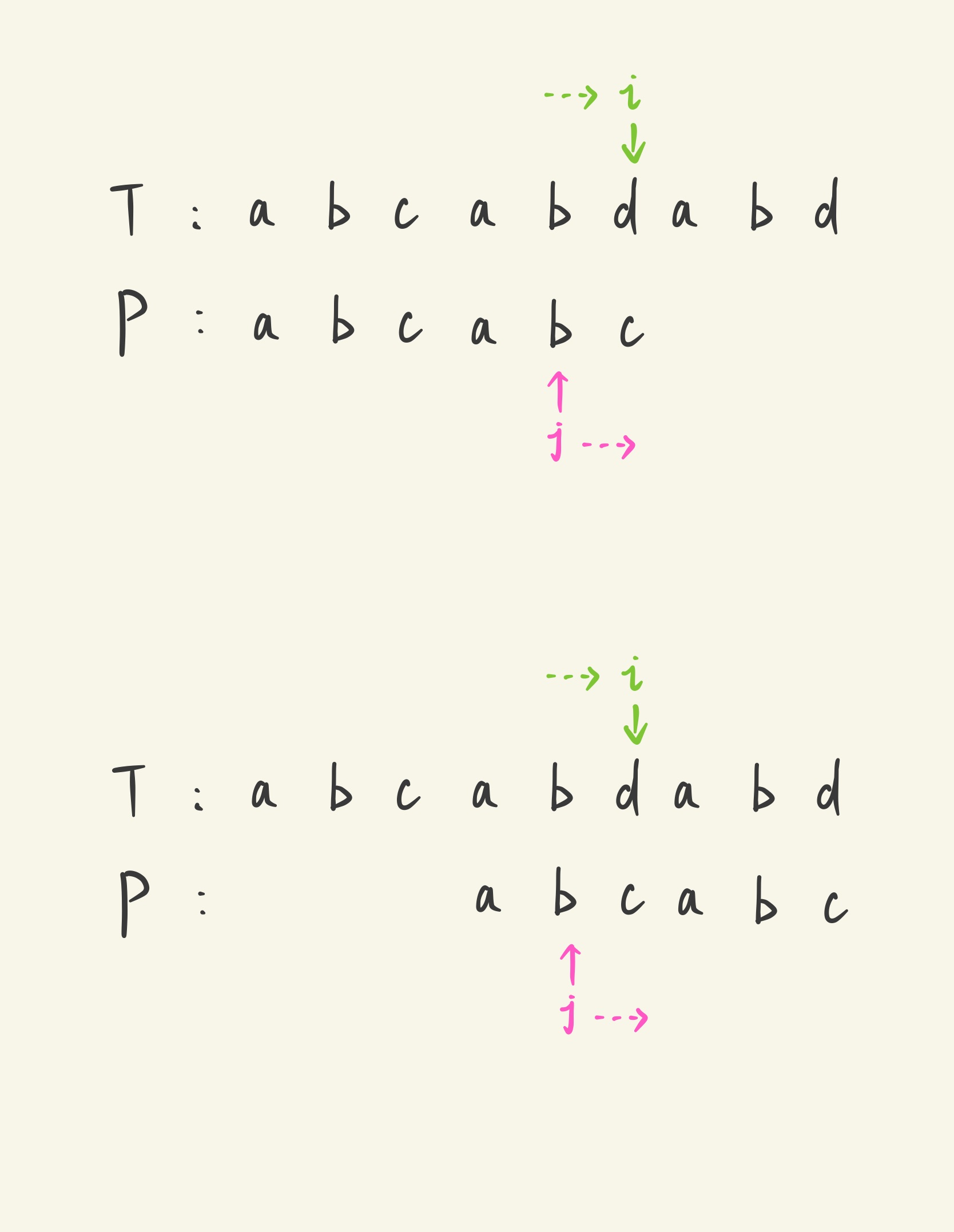
如图,当 (P[j+1]=P[next[j]+1]) 时,跳转再后移仍然会出现失配,实际匹配过程中这里会继续往前跳转,这一步完全可以在预处理 (next) 数组时就完成。
Code :优化后 (next) 数组的预处理
void nxt_init(void){
int p=0;
for(int i=2;i<=len2;i++){
while(p>0&&s2[i]!=s2[p+1]) p=nxt[p];
if(s2[i]==s2[p+1]) p++;
nxt[i]=(i<len2&&s2[i+1]==s2[p+1])?nxt[p]:p; //这里多加一个后面字符的是否相同的判断
}
}
这里 (next) 数组的含义其实就发生了改变,在原来的基础上加上了一个 (P[j+1]
eq P[next[j]+1]) 的前提。 这里给的板子题要求输出优化前的 (next) 数组,不要交错哦
设模式串和匹配串的长度分别为 (n) ,(m)
时间复杂度:(O(n+m))
好了,这次是真的结束了~
参考资料:
- Matrix67大神的《KMP算法详解》 前面 (MP) 算法的部分基本是一样的
- 板子题上皎月dalao的高赞题解
其实两个都差不多(讲得都比我好QAQ
来看下一个qwq
(AC) 自动机
(AC) 自动机 ((Aho)-(Corasick) (automaton))
是由 (Alfred) (V.) (Aho) 和 (Margaret) (J.) (Corasick) 发明的字符串搜索算法,用于在输入的一串字符串中匹配有限组“字典”中的子串。它与普通字符串匹配的不同点在于同时与所有字典串进行匹配。算法均摊情况下具有近似于线性的时间复杂度,约为字符串的长度加所有匹配的数量。然而由于需要找到所有匹配数,如果每个子串互相匹配(如字典为 (A) ,(AA) ,(AAA) ,(AAAA) ,输入的字符串为 (AAAA)),算法的时间复杂度会近似于匹配的二次函数。
该算法主要依靠构造一个有限状态机(类似于在一个 (Trie) 树中添加失配指针)来实现。这些额外的失配指针允许在查找字符串失败时进行回退(例如设 (Trie) 树的单词 (cat) 匹配失败,但是在 (Trie) 树中存在另一个单词 (cart),失配指针就会指向前缀 (ca)),转向某前缀的其他分支,免于重复匹配前缀,提高算法效率。——参考自 (Wikipedia)
定义看着很头大?没关系,实际上学会 (KMP) 之后,学习 (AC) 自动机就相对容易了~
前置知识
- (Trie) 树
因为比较简单,所以就讲一下下吧~
甩定义~
(Trie) 树
又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。——参考自 (Wikipedia)
简单来说, (Trie) 树就是一棵树 废话 ,上面能保存多个字符串,构建方法如下:
- 选择一个字符串
- 从根节点开始帕努单当前节点的子节点是否含有下一个字符
- 如果含有则访问
- 否则,新建这个节点
- 回到第二步
- 所有字符串都被选择后结束
举个栗子
如果字符串分别是 " (TLE) " ," (LFT) " ," (LTL) " ,则构建完的 (Trie) 树长这样
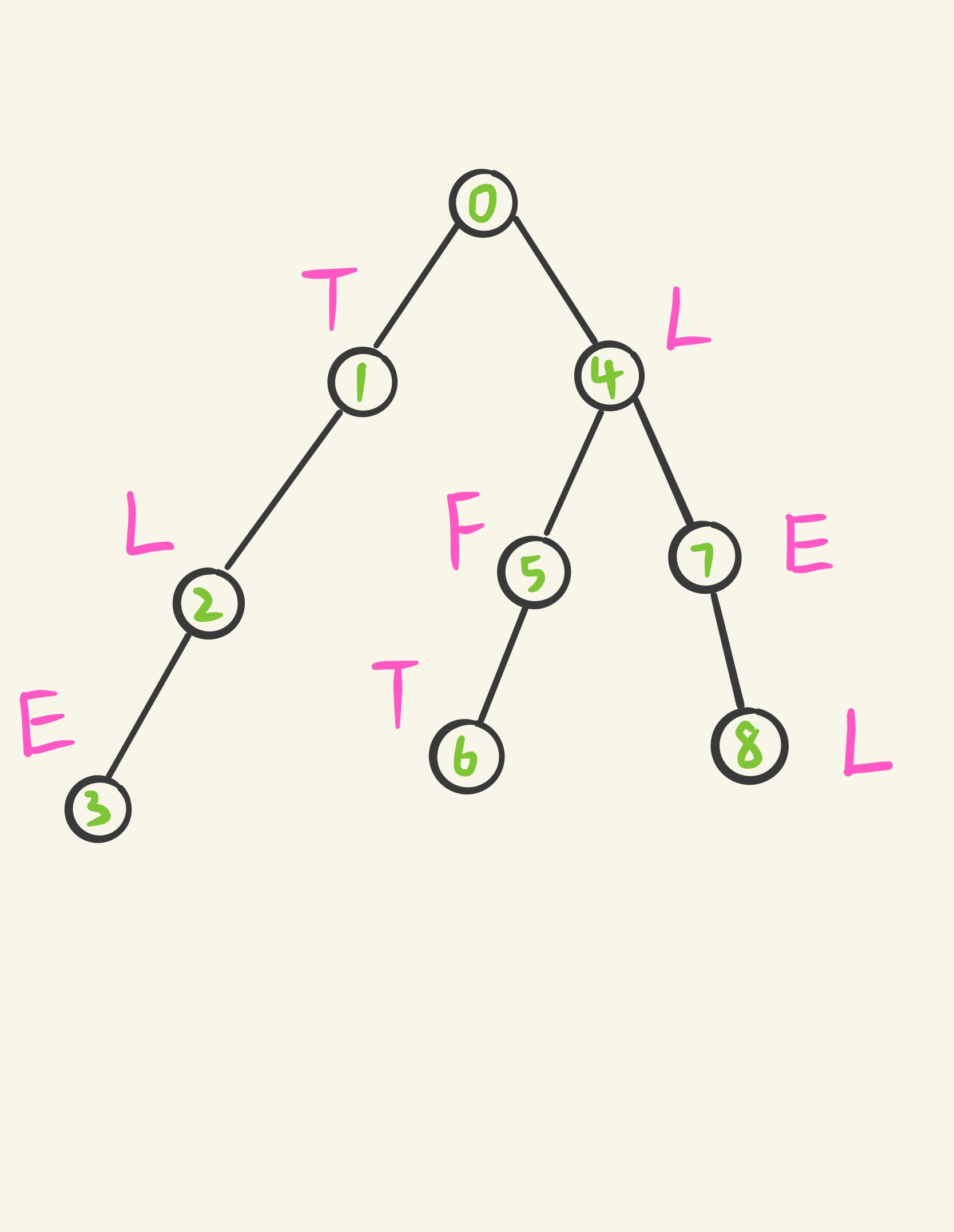
构建完这颗树之后有什么用呢?我们用这棵树代替模式串和匹配串 (T) 进行匹配,和 (KMP) 一样,我们用指针完成这个过程,只不过原来模式串的指针变成了 (Trie) 树上的指针。考虑一个问题,当匹配不能继续进行(指针移动到了叶节点)或失配时 (Trie) 树上的指针该移到哪?回想一下 (KMP) 中的 (next) 数组,我们知道指针移到的节点 (p) ,应满足从根节点到当前节点 (p) (含 (p) ,不含根节点)的字符形成的字符串与当前节点的某一祖先到当前节点(含祖先节点与当前节点)字符形成的字符串相同,且长度最长,相当于最长的相同“前后缀”
我们把当前节点应指向的节点 (p) 称为失配指针,习惯上也叫 (fail) 指针,代码中也用
(fail) 指代。
- (fail[i]) : 节点 (i) 的失配指针 (p) ,满足从根节点到 (p) (含 (p) ,不含根节点)的字符形成的字符串与 (i) 的某一祖先到 (i) (含祖先节点与节点 (i) )的字符形成的字符串相同,且长度最长
构建完失配指针的 (Trie) 树长这样
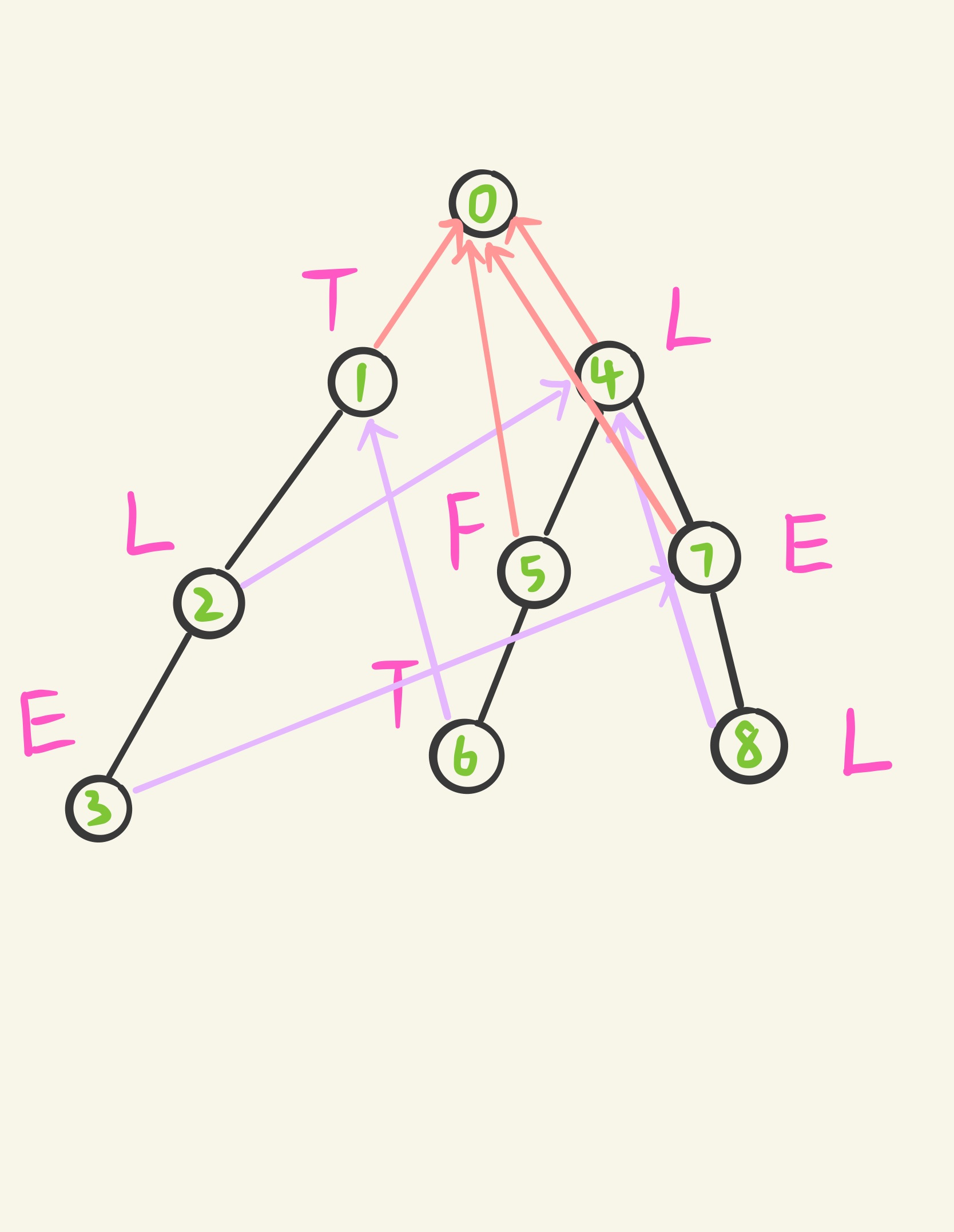
如何构建 (fail[i]) 指针呢?假设节点 (i) 的祖先的 (fail[i]) 指针已经构造完成,那么只需沿着祖先的 (fail[i]) 指针一路往前,找到第一个子节点中含有节点 (i) 的字符的节点即可,显然这是一个 (BFS) 的过程。
下面给出代码,节点编号从 (0) 开始,节点 (i) 的字符为 (ch) (这里假设都是小写)的子节点为 (son[i][ch-ascii(a)]) 。
Code :构建 (fail) 指针
void fail_init(void){
//根节点的子节点的fail指针显然就是根节点,这里根节点的编号为0
for(int i=0;i<26;i++) //先将子节点都加入队列
if(son[0][i]>0) que.push(son[0][i]);
while(que.empty()==false){
int tmp=que.front();
que.pop();
/*
子节点x的fail指针即
当前节点的fail指针y中字符与x节点字符ch相同的“子节点”所指向的节点z
这个节点z有可能是当前这个“子节点”——当节点y确实有代表ch的子节点时
也有可能是沿着节点y的fail指针继续往上的某一节点的字符与ch相同的子节点
为了达到这个目的,我们每遍历到一个节点
不仅要处理出存在的子节点的fail指针
还要处理出代表其他字符的“子节点”与上一层的联系
*/
for(int i=0;i<26;i++)
if(son[tmp][i]>0){
fail[son[tmp][i]]=son[fail[tmp]][i];
que.push(son[tmp][i]);
}else son[tmp][i]=son[fail[tmp]][i];
}
}
构建完 (fail) 指针后,匹配的过程就简单了。
举个栗子,求有多少个模式串在匹配串中出现了几次。我们让每个节点记录下以这个节点为结尾的模式串个数(一般为1,要求重复的模式串计算多次时可以大于1),用 (ec[i]) 表示,匹配串为 (t) ,就会有如下代码。
Code :求模式串在匹配串中总的出现次数
int query(void){
int len=strlen(s+1);
int pos=0,ans=0;
for(int i=1;i<=len;i++){
pos=son[pos][s[i]-'a'];
for(int j=pos;j>0&&ec[j]!=-1;j=fail[j]){
ans+=ec[j];
ec[j]=-1; //已经计算过的标记为负一防止重复计算
}
}
return ans;
}
再举个栗子,求每个模式串在匹配串中出现了几次。我们让每个节点记录下以这个节点为结尾的模式串的编号,用 (ed[i]) 表示, 为了简化问题就假设模式串是无重复(有重复其实就把 (ed) 用 (vector) 之类的改成链表就行了),同样,匹配串为 (t) ,模式串 (i) 的出现次数为 (ans[i]) ,有如下代码。
Code :求每个模式串在匹配串中出现次数
void query(void){
int len=strlen(t+1);
int pos=0;
for(int i=1;i<=len;i++){
pos=son[pos][t[i]-'a'];
for(int j=pos;j>0;j=fail[j]) ans[ed[j]].sec++;
}
}
上面两个栗子其实就是两个板子题~
贴下链接+代码:
P3808 【模板】AC自动机(简单版)
Code
#include <bits/stdc++.h>
using namespace std;
const int L=1e6+5;
int n;
char s[L];
int cnt,ec[L],fail[L],son[L][26];
queue<int> que;
void build(void);
void fail_init(void);
int query(void);
int main(void){
scanf("%d",&n);
for(int i=0;i<n;i++){
scanf("%s",s+1);
build();
}
fail_init();
scanf("%s",s+1);
printf("%d
",query());
return 0;
}
void build(void){
int len=strlen(s+1);
int pos=0;
for(int i=1;i<=len;i++){
int tmp=s[i]-'a';
if(son[pos][tmp]==0) son[pos][tmp]=++cnt;
pos=son[pos][tmp];
}
ec[pos]++;
}
void fail_init(void){
for(int i=0;i<26;i++)
if(son[0][i]>0) que.push(son[0][i]);
while(que.empty()==false){
int tmp=que.front();
que.pop();
for(int i=0;i<26;i++)
if(son[tmp][i]>0){
fail[son[tmp][i]]=son[fail[tmp]][i];
que.push(son[tmp][i]);
}else son[tmp][i]=son[fail[tmp]][i];
}
}
int query(void){
int len=strlen(s+1);
int pos=0,ans=0;
for(int i=1;i<=len;i++){
pos=son[pos][s[i]-'a'];
for(int j=pos;j>0&&ec[j]!=-1;j=fail[j]){
ans+=ec[j];
ec[j]=-1;
}
}
return ans;
}
Code
#include <bits/stdc++.h>
using namespace std;
#define fir first
#define sec second
#define mp make_pair
typedef pair<int,int> pii;
const int N=155;
const int S=75;
const int L=1e6+5;
int n;
char s[N][S];
char t[L];
pii ans[N];
int cnt,ed[L],fail[L],son[L][26];
queue<int> que;
void reset(void);
void build(int num);
void fail_init(void);
void query(void);
bool cmp(const pii &a,const pii &b);
int main(void){
while(true){
scanf("%d",&n);
if(n==0) break;
reset();
for(int i=1;i<=n;i++){
ans[i]=mp(i,0);
scanf("%s",s[i]+1);
build(i);
}
fail_init();
scanf("%s",t+1);
query();
sort(ans+1,ans+n+1,cmp);
printf("%d
",ans[1].sec);
for(int i=1;i<=n&&ans[i].sec==ans[1].sec;i++) printf("%s
",s[ans[i].fir]+1);
}
return 0;
}
inline void reset(void){
memset(ans,0,sizeof(ans));
cnt=0;
memset(ed,0,sizeof(ed));
memset(fail,0,sizeof(fail));
memset(son,0,sizeof(son));
}
void build(int num){
int len=strlen(s[num]+1);
int pos=0;
for(int i=1;i<=len;i++){
int tmp=s[num][i]-'a';
if(son[pos][tmp]==0) son[pos][tmp]=++cnt;
pos=son[pos][tmp];
}
ed[pos]=num;
}
void fail_init(void){
for(int i=0;i<26;i++)
if(son[0][i]>0) que.push(son[0][i]);
while(que.empty()==false){
int tmp=que.front();
que.pop();
for(int i=0;i<26;i++)
if(son[tmp][i]>0){
fail[son[tmp][i]]=son[fail[tmp]][i];
que.push(son[tmp][i]);
}else son[tmp][i]=son[fail[tmp]][i];
}
}
void query(void){
int len=strlen(t+1);
int pos=0;
for(int i=1;i<=len;i++){
pos=son[pos][t[i]-'a'];
for(int j=pos;j>0;j=fail[j]) ans[ed[j]].sec++;
}
}
inline bool cmp(const pii &a,const pii &b){
return a.sec==b.sec?a.fir<b.fir:a.sec>b.sec;
}
设模式串(总和)和匹配串的长度分别为 (n) ,(m)
时间复杂度:(O(n+m))
讲完啦~
学习字符串还会遇到很多神奇 毒瘤 的算法 比如后缀数组 ,有机会下次再分享吧~
这个月要去打人生第一场正式比赛了qwq, CCPC 组队赛!
希望不要零 负 贡献orz
希望不要拖dalao队友的后腿orz
希望见识一下,
我未见过的风景。