爬取的网页地址为:https://movie.douban.com/top250
打开网页后,可观察到:TOP250的电影被分成了10个页面来展示,每个页面有25个电影。
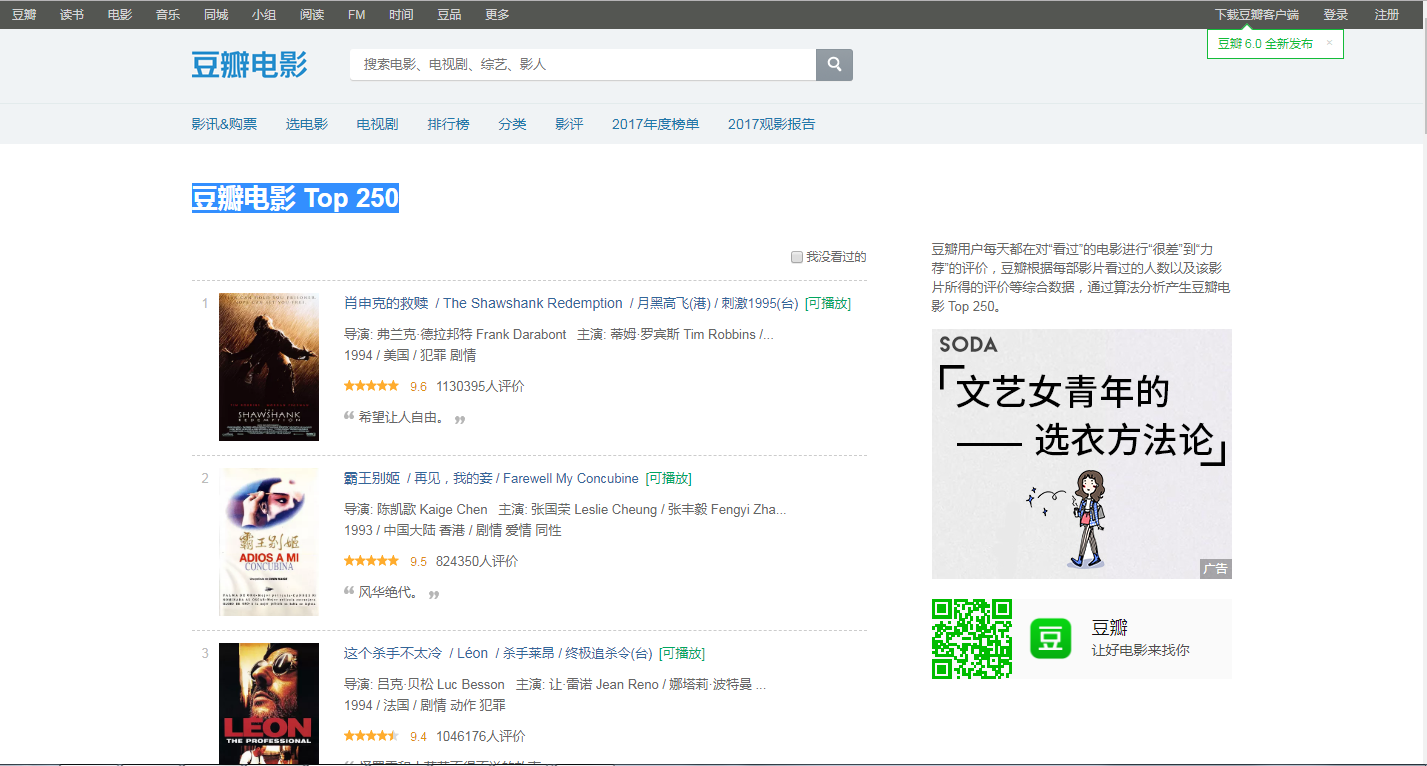
那么要爬取所有电影的信息,就需要知道另外9个页面的URL链接。
第一页:https://movie.douban.com/top250
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
以此类推...
分析网页源代码:以首页为例

观察后可以发现:
所有电影信息在一个ol标签之内,该标签的 class属性值为grid_view;
每个电影在一个li标签里面;
每个电影的电影名称在:第一个 class属性值为hd 的div标签 下的 第一个 class属性值为title 的span标签里;
每个电影的评分在对应li标签里的(唯一)一个 class属性值为rating_num 的span标签里;
每个电影的评价人数在 对应li标签 里的一个 class属性值为star 的div标签中 的最后一个数字;
每个电影的短评在 对应li标签 里的一个 class属性值为inq 的span标签里。
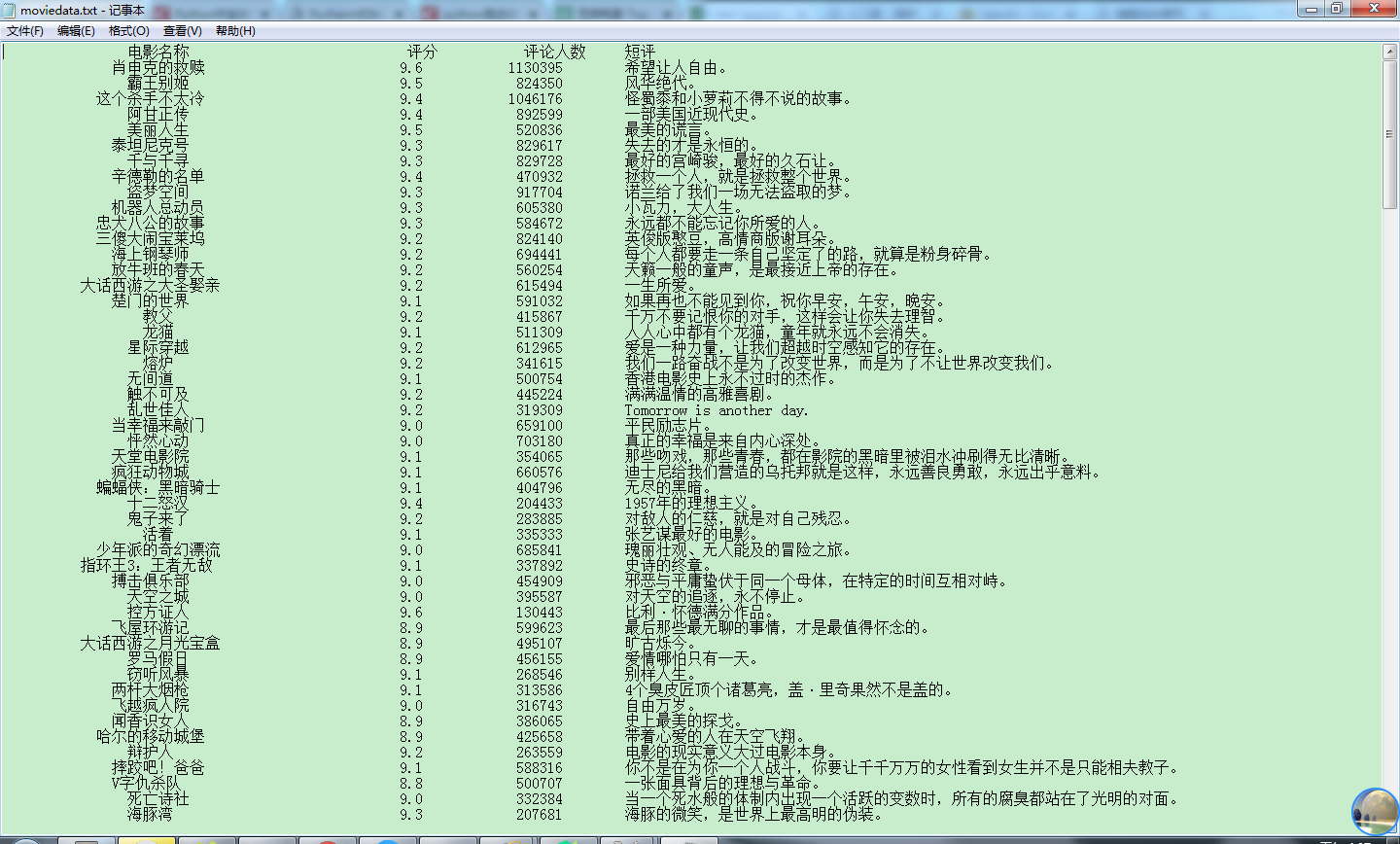
Python主要模块:requests模块 BeautifulSoup4模块
>pip install requests
>pip install BeautifulSoup4
主要代码:
Top250.py
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
# -*- coding:utf-8 -*-
import requests # requests模块 from bs4 import BeautifulSoup # BeautifulSoup4模块 import re # 正则表达式模块 import time # 时间模块 import sys # 系统模块 """获取html文档""" def getHTMLText(url, k): try: if(k == 0): # 首页 kw = {} else: # 其它页 kw = {'start':k, 'filter':''} r = requests.get(url, params = kw, headers = {'User-Agent': 'Mozilla/4.0'}) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print("Failed!") """解析数据""" def getData(html): soup = BeautifulSoup(html, "html.parser") movieList = soup.find('ol', attrs = {'class':'grid_view'}) # 找到第一个class属性值为grid_view的ol标签 moveInfo = [] for movieLi in movieList.find_all('li'): # 找到所有li标签 data = [] # 得到电影名字 movieHd = movieLi.find('div', attrs = {'class':'hd'}) # 找到第一个class属性值为hd的div标签 movieName = movieHd.find('span', attrs = {'class':'title'}).getText() # 找到第一个class属性值为title的span标签 # 也可使用.string方法 data.append(movieName) # 得到电影的评分 movieScore = movieLi.find('span', attrs={'class':'rating_num'}).getText() data.append(movieScore) # 得到电影的评价人数 movieEval=movieLi.find('div',attrs={'class':'star'}) movieEvalNum=re.findall(r'd+',str(movieEval))[-1] data.append(movieEvalNum) # 得到电影的短评 movieQuote = movieLi.find('span', attrs={'class': 'inq'}) if(movieQuote): data.append(movieQuote.getText()) else: data.append("无") print(outputMode.format(data[0], data[1], data[2], data[3], chr(12288))) # 将输出重定向到txt文件 output = sys.stdout outputfile = open("moviedata.txt", 'w', encoding = 'utf-8') sys.stdout = outputfile outputMode = "{0:{4}^20} {1:^10} {2:^10} {3:{4}<10}" print(outputMode.format('电影名称', '评分', '评论人数', '短评', chr(12288))) basicUrl = 'https://movie.douban.com/top250' k = 0 while k <= 225: html = getHTMLText(basicUrl, k) time.sleep(2) k += 25 getData(html) outputfile.close() sys.stdout = output |