软件的一个驱动由于开发的年代比较久一些,使用的是非Unicode编码,而当前新的软件使用的是Unicode编码,于是将非Unicode驱动用于Unicode软件上时,就出现了问题!
问题就出现在非Unicode与Unicode的转换过程中!
程序中使用了char数组以及TCHAR数组,而数组是以字符‘�’为结束的。
请看下面的例子:
C++ Code
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
// cppunicode.cpp : Defines the entry point for the console application.
// #include "stdafx.h" #include <iostream> #include <string> #include <tchar.h> #include <Windows.h> using namespace std; #define MAX_AARRAY_LENGTH 64 int _tmain(int argc, _TCHAR* argv[]) { char szArray[MAX_AARRAY_LENGTH]; TCHAR tszArray[MAX_AARRAY_LENGTH]; memset(&szArray, 0, sizeof(szArray)); memset(&tszArray, 0, sizeof(tszArray)); for (int i = 0; i < MAX_AARRAY_LENGTH; i++) { if (i >=0 && i < 12) { szArray[i] = 'a'; } if (i >=19 && i < 22) { szArray[i] = 'b'; } if (i >=30 && i < 32) { szArray[i] = 'c'; } } //会被‘�’截断,然后输出aaaaaaaaaaa cout << szArray << endl; //char[]转TCHAR[] 方法1 int nLength = MultiByteToWideChar (CP_ACP, 0, szArray, -1, NULL, 0) ; MultiByteToWideChar (CP_ACP, 0, szArray, -1, tszArray, nLength) ; //char[]转TCHAR[] 方法2 for (int i = 0; i < MAX_AARRAY_LENGTH; i++) { TCHAR* ptchar = new TCHAR; *ptchar = '�'; MultiByteToWideChar(CP_ACP, 0, &szArray[i], -1, ptchar, 1); tszArray[i] = *ptchar; delete ptchar; } //TCHAR[]转char[] 方法1 int nLen = WideCharToMultiByte( CP_ACP, 0, tszArray, -1, NULL, 0, NULL, NULL ); WideCharToMultiByte( CP_ACP, 0, tszArray, -1, szArray, nLen, NULL, NULL ); //TCHAR[]转char[] 方法2 for (int i = 0; i < MAX_AARRAY_LENGTH; i++) { char* pchar = new char; *pchar = '�'; WideCharToMultiByte(CP_ACP, 0, &tszArray[i], -1, pchar, 1, NULL, NULL ); szArray[i] = *pchar; delete pchar; } //会被‘�’截断,然后输出aaaaaaaaaaa cout << szArray << endl; cout << tszArray << endl; return 0; } |
char数组szArray的内容如下:可见,在数组长度范围内,分三个位置存储了不同的内容,但是在使用cout输出、sprintf、MultiByteToWideChar以及WideCharToMultiByte等时会将其在索引为12时遇到‘�’被截断处理,导致只能保留第一部分位置的内容,从而造成数据的截断丢失。
原始数据:
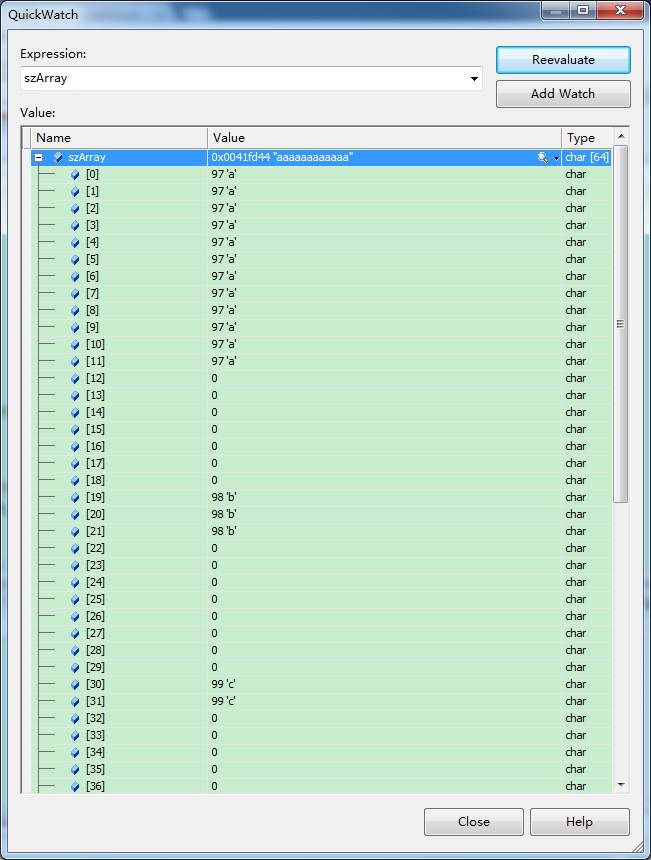
MultiByteToWideChar转换后的数据:


我一直希望能够通过库函数以及API来解决此问题,但是它们均是遇到‘�’则结束转换操作。
一种可行的做法是:遍历字符数组,单个字符转换后,再赋值给新的字符数组(简单好用!)。
见程序中: //char[]转TCHAR[] 方法2 //TCHAR[]转char[] 方法2,从而很好地完成此类字符数组的转换。