
本文链接:
https://blog.csdn.net/hlang8160/article/details/88310815
一、 概念
自动摘要技术解决的问题描述很简单,就是用一些精炼的话来概括整片文章的大意,用户通过读文摘就可以了解到原文要表达的意思。
问题解决的思路有两种:
一种是Extractive抽取式的,就是从原文中找到一些关键的句子,组合成一篇摘要;
另外一种是Abstractive摘要式的,这就需要计算机可以读懂原文的内容,并且用自己的意思变大出来。
现阶段,相对成熟的是抽取式方案,有很多很多算法,也有一些baseline测试,但得到的摘要效果差强人意。对后者的研究并不是很多,人类语言包括字、词、短语、句子、段落、文档这几个level,研究难度依次递增,理解句子、段落尚且困难,何况是文档,这是摘要生成最大的难点。
二、Extractive抽取式算法 - TextRank
https://www.cnblogs.com/xueyinzhe/p/7101295.html
https://www.cnblogs.com/chenbjin/p/4600538.html
TextRank是一种用来做关键词提取的算法,也可以用于提取短语和自动摘要,因为TextRank是基于PageRank的。PageRank设计之初是用于Google的网页排名的,以该公司创办人拉里·佩奇(Larry Page)之姓来命名。Google用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。PageRank通过互联网中的超链接关系来确定一个网页的排名,其公式是通过一种投票的思想来设计的:如果我们要计算网页A的PageRank值(以下简称PR值),那么我们需要知道有哪些网页链接到网页A,也就是要首先得到网页A的入链,然后通过入链给网页A的投票来计算网页A的PR值。这样设计可以保证达到这样一个效果:当某些高质量的网页指向网页A的时候,那么网页A的PR值会因为这些高质量的投票而变大,而网页A被较少网页指向或被一些PR值较低的网页指向的时候,A的PR值也不会很大,这样可以合理地反映一个网页的质量水平。那么根据以上思想,佩奇设计了下面的公式:
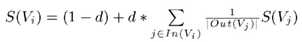
该公式中,Vi表示某个网页,Vj表示链接到Vi的网页(即Vi的入链),S(Vi)表示网页的PR值,In(Vi)表示网页Vi的所有入链的集合,Out(Vj)表示网页Vj中的链接指向的网页的集合(即网页Vj链接的网页集合),d表示阻尼系数,是用来克服这个公式中 "d *" 后面部分的固有缺陷,即如果仅仅只有求和的部分,那么该公式将无法处理没有入链的网页的PR值,因为此时根据公式,这些网页的PR值为0,但实际情况不是如此,所以加入了一个阻尼系数来确保每个网页都有一个大于0的PR值,根据实验结果,在0.85的阻尼系数下,大约100多次的迭代PR值就能收敛到一个稳定的值,而当阻尼系数接近1时,需要迭代的次数会骤然增加很多,且排序不稳定。公式中S(Vj)前面的分数指的是Vj所有出链指向的网页应该平分Vj的PR值,这样才算是把自己的票分给了自己链接到的网页。
比如:a、b、c表示网页
S(Va) = (1 – 0.85) + 0.85 * ((1/2)*S(Vb) + (1/1) * S(Vc))
= 0.15 + 0.85 * (0.5 + 1) = 1.425
S(Vb) = 0.15
S(Vc) = 0.575
More iterations ……
1、TextRank算法提取关键词
提取出若干关键词,若原文本中存在若干个关键词相邻的情况,那么这些关键词可以构成一个关键短语。
TextRank是由PageRank改进而来,其公式有颇多相似之处,这里给出TextRank的公式:
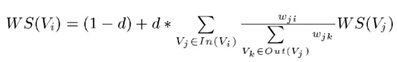
可以看出,该公式仅仅比PageRank多了一个权重项Wji,用来表示两个节点之间的边连接有不同的重要程度,单词i和单词j共现的次数越多,权重Wij就越大。TextRank用于关键词提取的算法如下:
1)把给定的文本T按照完整句子进行切割,即T=[S1, S2, ..., Sm];# 分句
2)对于每个句子Si(属于T),进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即Si = [t_{i,1}, t_{i,2}, ..., t_{i,n} ],其中t_{i,j}表示保留后的候选关键词;
3)构建候选关键词图G =(V, E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边,当且仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口的大小,即最多共现K个单词;
4)根据上面的公式,迭代传播各节点的权重,直至收敛;
5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词;
6)由(5)得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成关键词短语。
2、TextRank算法提取关键词短语
提取关键词短语的方法基于关键词提取,可以简单认为:如果提取出的若干关键词在文本中相邻,那么构成一个被提取的关键短语。
3、TextRank算法生成摘要
将文本中的每个句子分别看做一个节点,如果两个句子有相似性,那么认为这两个句子对应的节点之间存在一条无向有权边,权值Wji是相似度,然后通过pagerank算法计算得到的重要性最高的若干句子可以当作摘要。考察句子相似度的方法是下面这个公式:
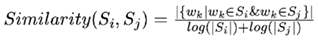
公式中,Si、Sj分别表示两个句子i和j,|Si|为句子i的单词数量,Wk表示句子中的词,那么分子部分的意思是同时出现在两个句子中的同一个词的个数,分母是对句子中词的个数求对数之和,分母这样设计可以遏制较长的句子在相似度计算上的优势。
(1)根据以上相似度公式循环计算任意两个节点之间的相似度,
(2)根据阈值去掉两个节点之间相似度较低的边连接,构建出节点连接图,然后计算TextRank值(PR值),
(3)然后使用幂迭代法不断更新节点PR值,直到收敛,最终的PR值为句子的重要性得分。
(4)最后对所有TextRank值排序,选出TextRank值最高的几个节点对应的句子作为摘要。
无监督TextRank算法优势:
1)TextRank不依赖于文本单元的局部上下文,而是考虑全局信息,从全文中不断迭代采样的文本信息进行文本单元重要性学习;
2)TextRank识别文本中各种实体间的连接关系,利用了推荐的思想。文本单元会推荐与之相关的其他文本单元,推荐的强度是基于文本单元的重要性不断迭代计算得到。被其他句子高分推荐的句子往往在文本中更富含信息量,因此得分也高;
3)TextRank实现了"文本冲浪"的思路,意思与文本凝聚力类似。对于文本中的某一概念c,我们往往更倾向于接下来看与概念c相关的其他概念;
4)通过迭代机制,TextRank能够基于连接的文本单元的重要性来计算文本单元得分。
TextRank算法存在的问题及解决策略:
1)摘要句子重复; 去除相似句子
2)摘要开头句子不适合作为句子;
3)部分摘要句子太长。 限定摘要句子长度
三、Abstractive抽取式算法
自动总结(Automatic Summarization)类型的模型一直是研究热点。直接抽出重要的句子的抽取式方法较为简单,有如textrank之类的算法,而生成式(重新生成新句子)较为复杂,效果也不尽如人意。目前比较流行的Seq2Seq模型,由 Sutskever等人提出,基于一个Encoder-Decoder的结构将source句子先Encode成一个固定维度d的向量,然后通过Decoder部分一个字符一个字符生成Target句子。添加入了Attention注意力分配机制后,使得Decoder在生成新的Target Sequence时,能得到之前Encoder编码阶段每个字符的隐藏层的信息向量Hidden State,使得生成新序列的准确度提高。
encoder-decoder框架的工作机制是:先使用encoder,将输入编码到语义空间,得到一个固定维数的向量,这个向量就表示输入的语义;然后再使用decoder,将这个语义向量解码,获得所需要的输出,如果输出是文本的话,那么decoder通常就是语言模型。这种机制的优缺点都很明显,优点:非常灵活,并不限制encoder、decoder使用何种神经网络,也不限制输入和输出的模态(例如image caption任务,输入是图像,输出是文本);而且这是一个端到端(end-to-end)的过程,将语义理解和语言生成合在了一起,而不是分开处理。缺点的话就是由于无论输入如何变化,encoder给出的都是一个固定维数的向量,存在信息损失;在生成文本时,生成每个词所用到的语义向量都是一样的,这显然有些过于简单。
这里主要介绍两种算法:1)seq2seq + attention模型;2)基于Pointer Network的生成式摘要算法
1、seq2seq + attention模型
- 自然语言处理中的自注意力机制 seq2seq + attention机制的应用 深度学习中Attention Mechanism详细介绍:原理、分类及应用
1)seq2seq
RNN最重要的一个变种:N vs M,这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型,即序列到序列模型。原始的N vs N RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。序列形的数据就不太好用原始的神经网络处理了,为了建模序列问题,RNN引入了隐状态h(hidden state)的概念,h可以对序列形的数据提取特征,接着再转换为输出。
为此,Encoder-Decoder结构先将输入数据编码成一个上下文向量c:
得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
拿到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。具体做法就是将c当做之前的初始状态h0输入到Decoder中:
还有一种做法是将c当做每一步的输入:
由于这种Encoder-Decoder结构不限制输入和输出的序列长度,因此应用的范围非常广泛,比如:
机器翻译。Encoder-Decoder的最经典应用,事实上这一结构就是在机器翻译领域最先提出的
文本摘要。输入是一段文本序列,输出是这段文本序列的摘要序列。
阅读理解。将输入的文章和问题分别编码,再对其进行解码得到问题的答案。
语音识别。输入是语音信号序列,输出是文字序列。
…………
2)attention机制
a. 概念
Attention是一种用于提升基于RNN(LSTM或GRU)的Encoder + Decoder模型的效果的的机制(Mechanism),一般称为Attention Mechanism。Attention Mechanism目前非常流行,广泛应用于机器翻译、语音识别、图像标注(Image Caption)等很多领域,之所以它这么受欢迎,是因为Attention给模型赋予了区分辨别的能力,例如,在机器翻译、语音识别应用中,为句子中的每个词赋予不同的权重,使神经网络模型的学习变得更加灵活(soft)。比如在图像标注应用中,可以解释图片不同的区域对于输出Text序列的影响程度

通过上述Attention Mechanism在图像标注应用的case可以发现,Attention Mechanism与人类对外界事物的观察机制很类似,当人类观察外界事物的时候,一般不会把事物当成一个整体去看,往往倾向于根据需要选择性的去获取被观察事物的某些重要部分,比如我们看到一个人时,往往先Attention到这个人的脸,然后再把不同区域的信息组合起来,形成一个对被观察事物的整体印象。因此,Attention Mechanism可以帮助模型对输入的X每个部分赋予不同的权重,抽取出更加关键及重要的信息,使模型做出更加准确的判断,同时不会对模型的计算和存储带来更大的开销,这也是Attention Mechanism应用如此广泛的原因。
在Encoder-Decoder结构中,Encoder把所有的输入序列都编码成一个统一的语义特征c再解码,因此,c中必须包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个c可能存不下那么多信息,就会造成翻译精度的下降。 所谓注意力机制,就是说在生成每个词的时候,对不同的输入词给予不同的关注权重。谷歌博客里介绍神经机器翻译系统时所给出的动图形象地展示了attention。