Ajax简介:
- Ajax ,全称为 Asynchronous JavaScript and XML ,即异步的 JavaScript XML 它是利用 JavaScript 在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。页面在后台与服务器进行了数据交互,获取到数据之后,再利用 JavaScript 改变网页,这样网页内容就会更新了。 http://www.w3school.com.cn/ajax/ajax_xmlhttprequest_send.asp。
- Ajax 加载数据 就是发送了一个 Ajax 请求,可以用 requests 来模拟 Ajax 请求,就可以成功抓取数据了。
- 基本原理
- 发送 Ajax 请求到网页更新的这个过程可以简单分为以下 3 步:
- 发送请求;
- 解析内容;
- 渲染网页;
- 发送请求
- JavaScript 可以实现页面的各种交互功能,Ajax 也是由 JavaScript 实现的,实际上执行了如下代码:
var xmlhttp; if (windows.XMLHttpRequest) { // code for IE7+, Firefox, Chrome, Opera, Safari xmlhttp =new XMLHttpRequest(); } else {// code for IE6, IE5 xmlhttp =new ActiveXObject("Microsoft.XMLHTTP"); } xmlhttp.open("POST","/ajax/",true); xmlhttp.send();
JavaScript 对 Ajax 最底层的实现,实际上就是新建了 XMLHttpRequest 对象,然后调用 onreadystatechange 属性设置了监听,然后调用 open()和 send ()方法向某个链接(也就是服务器)送了请求。用 Python 实现请求发送之后,可以得到响应结果,但这里请求的发送变成 JavaScript 来完成。由于设置了监听,所以当服务器返回响应时, onreadystatechange 对应的方法便会被触发,然后在这个方法里面解析响应内容即可。
- JavaScript 可以实现页面的各种交互功能,Ajax 也是由 JavaScript 实现的,实际上执行了如下代码:
-
解析内容
-
得到响应之后,onreadystatechange 属性对应的方法便会被触发,此时利用 xmlhttp 的 responseText 属性便可取到响应内容。类似于 Python 中利用 requests 向服务器发起请求,然后得到响应的过程。那么返回内容可能是 HTML,可能是 JSON,接下来只需要在方法中用 JavaScript 进一步处理即可。如:如果是 JSON 的话,可以进行解析和转化
-
- 渲染网页
- JavaScrip 有改变网页内容的能力,解析完响应内容之后,就可以调用 JavaScript 来针对解析完的 内容对网页进行下一步处理了。比如,通过 document.getElementByid().innerHTML 这样的操作,便可以对某个元素内的源代码进行更改,这样网页显示的内容就改变了,这样的操作也被称作 DOM 操作,即对 Document 网页文档进行操作,如更改、删除等。
- document.getElementByid("myDiv").innerHTML=xmlhttp. responseText 便将 ID 为 myDiv 的节点内部的 HTML 代码更改为服务器返回的内容,这样 myDiv 元素内部便会呈现出服务器返回的数据,网页的部分内容看上去就更新了。
- 这3个步骤其实都是由 JavaScript 完成的,它完成了整个请求 、解析和渲染的过程。
- 再回想微博的下拉刷新,其实就是 JavaScript 向服务器发送了 Ajax 请求,然后获取新的微博数据,将其解析,并将其谊染在网页中。
- 发送请求
一、Ajax分析方法
- 查看请求
- 需要借助浏览器的开发者工具,以 Chrome 浏览器为例介绍。(用 Chrome 浏览器打开 博的链接 https://m.weibo.cn/u/2830678474,选择 检查”选项)
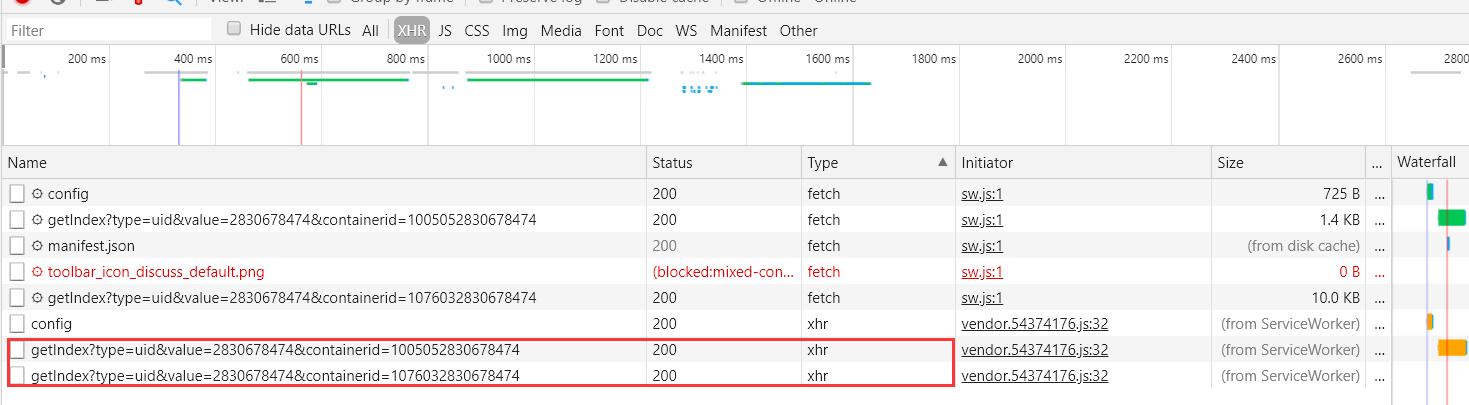
- Ajax 有其特殊的请求类型 ,叫作 xhr。一个名称以 getlndex 头的请求,其 Type 为 xhr,就是 Ajax 请求。
- 点击请求后,其中 Request Headers 中有 个信息为 X-Requested-With:XMLHt Request ,这就标记了此请求是 Ajax 请求。
- 随后点击 Preview,即可看到响应的内容,它是 JSON 格式的 这里 Chrome 为我们自动做 解析,点击箭头即可展开和收起相应内容。这里的返回结果是个人信息,如昵称、简介、头像等,这也是用来渲染个人 页所使用的数据 JavaScript 接收到这些数据之后,再执行相应的渲染方法,整个页面就渲染出来了。 也可以切换到 Response 选项卡,从中观察到真实的返回数据
- 切回到第一个请求,观察 Response :最原始的链接 https://m.weibo.cn/u/2830678474 返回的结果,其代码只有不到 50 行,结构也简单,只执行了一些 JavaScript。所以,我们看到的微博页面的真实数据并不是最原始的页面返回的,而是后来执行 JavaScript 后再次向后台发送了 Ajax 请求,浏览器到数据后再进一步渲染出来的
- 过滤请求
- 再利用 Chrome 开发者具的筛选功能筛选出所有的 Ajax 请求。点击 XHR。
- 滑动页面,可以看到页面底部有一条条新的微博被刷出,而开发者工具下方也一个个出现 Ajax 请求,
- 随意点开一个条目,都可以清楚地看到 Request URL、Request Headers、Response Headers、Response Body,此时要模拟请求和提取就非常简单了
二、Ajax 结果提取
- 分析请求
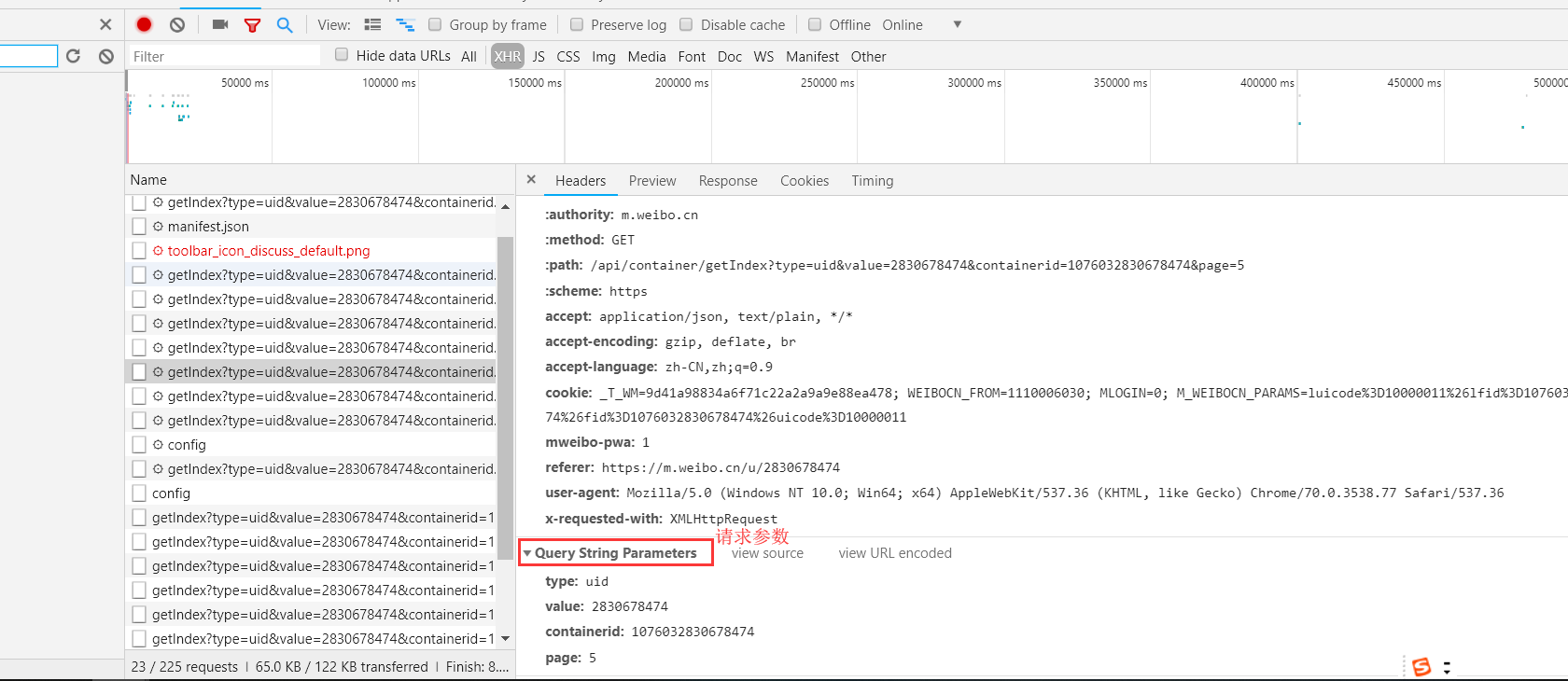
- 打开 Ajax 的 XHR 过滤器,加载新的微博内容。选定其中一个请求,分析它的参数信息。点击该请求,进入详情页面
- 这些是 GET 类型的请求,请求链接为 https://m.weibo.cn/api/container/getlndex?type=uid&value=2830678474&containerid= I 076032830678474&page=2。请求的参数有4个:type、value、containerid和page。
- 他们的type、value、containerid 始终如一。type 始终为 uid, value 的值就是页面链接中的数字,这就是用户的 id。containerid 就是 107603 加上用户 id。改变值就是 page,这个参数是用来控制分页的, page=1 代表第 1 页, page=2 代表第二页,以此类推
- 分析响应
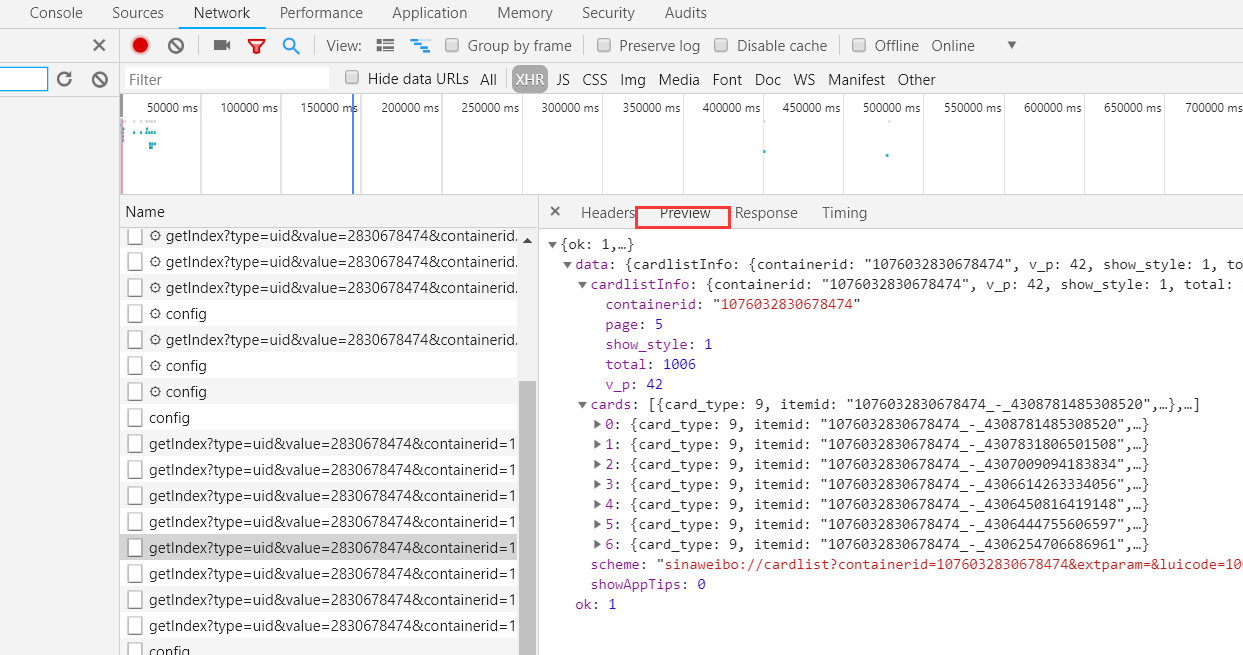
- 观察响应内容
-
这个内容是 JSON 格式,浏览器开发者工具自动做了解析以方便我们查看。最关键的两部分信息就是 cardlistlnfo 和 cards:cardlistlnfo包含一个比较重要的信息 total,其实是微博的总数量,可以根据这个数字来估算分页数;cards 是一个列表,它包含 10 个元素。
- 这个元素有一个比较重要的字段 mblog。 展开,可发现它包含的正是微博信息,如 attitudes count (赞数目)、comments_count(评论数目)、reposts_count(转发数目)created at(发布时间)、text(微博正文)等,而且都是些格式化的内容
- 我们请求一个接口,就可以得到 10 条微博,而且请求时只需要改变 page 参数即可。只需一个简单循环,就可以获取所有微博了
- 观察响应内容
- 实例模拟Ajax请求
- 首先,定义一个方法来获取每次请求的结果。在请求时,page是一个可变参数,所以将它作为方法的参数传递进来,代码:
from urllib.parse import urlencode import requests base_url = 'https://m.weibo.cn/api/container/getlndex?' headers = { 'Host': 'm.weibo.cn', 'Referer': 'https://m.weibo.cn/u/2830678474', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest', } def get_page(page): params = { 'type': 'uid', 'value': '2830678474', 'containerid': '1076032830678474', 'page': page } url = base_url + urlencode(params) try: response = requests.get(url, headers=headers) if response.status_code == 200: return response.json() except requests.ConnectionError as e: print( 'Error' , e.args) 也可:
 View Code
View Codefrom pyquery import PyQuery as pq import requests def getPage(page): url = 'https://m.weibo.cn/api/container/getIndex?'#在怎么来?分析Ajax请求 hd = {"User-Agent": 'Mozilla'} # 模仿浏览器 params = {'type': 'uid', 'value': '2830678474', 'containerid': '1076032830678474', 'page': page} # 作为参数增加到url中去 try: response = requests.get(url, headers=headers, params=params) response.raise_for_status() return response.json() # 解析为JSON返回 --snip--
首先,定义 base_url 来表示请求的 URL 的前半部分。然后,构造参数字典,其中 type、value、containerid 是固定参数, page 是可变参数。调用 urlencode()方法将参数转化为 -- URL的 GET 请求参数,类似于 type=uid&value=2830678474&containerid=1076032830678474&page=2 这样的形式。base_url 与参数拼合形成一个新的 URL。判断响应的状态码,如果是 200 ,则直接调用 json()方法将内容解析为JSON 返回,否则不返回任何信息。如果出现异常,则捕获并输出其异常信息。
- 需要定义一个解析方法,用来从结果中提取想要的信息,如这次想保存微博的 id、正文、赞数、评论数和转发数这几个内容,可以先遍历 cards,然后获取 mblog 中的各个信息,赋值为一个新的字典返回:
from pyquery import PyQuery as pq def parse_page(json): if json: items = json.get('data').get('cards') for item in items: item = item.get('mblog') if item == None: #注意:如果不添加返回None,可能因为有部分无返回值导致报错 continue weibo = {} weibo['id'] = item.get('id') weibo['text'] = pq(item.get('text')).text() weibo['attitudes'] = item.get('attitudes_count') weibo['comments'] = item.get('comments_count') weibo['reposts'] = item.get('reposts_count') yield weibo
借助 pyquery 将正文中的 HTML签去掉。
-
遍历 page,将提取到的结果输出:
if __name__ == '__main__': for page in range(1,11): json = get_page(page) results = parse_page(json) for result in results: print(result)
- 将结果保存到 MongoDB 数据库:
from pymongo import MongoClient client = MongoClient() db = client['weibo'] collection =db['weibo'] def save_to_mongo(result): if collection.insert(result): print('Save to mongo')

三、分析 Ajax爬取今日头条街拍美图
- 抓取分析
- 打开第一个网络请求,这个请求的 URL 就是当前的链接 http://www.toutiao.com/search/?keyword=街拍,打开 Preview 选项卡查看 Response Body。 如果页面中的内容是根据第一个请求得到的结果渲染出来的,那么第一个请求的源代码中必然会包含页面结果中的文字。可以尝试搜索结果的标题,如“路人”。 如果网页源代码中并没有包含这两个 ,搜索匹配结果数目为0。可以初步判断这 些内容是由 Ajax 加载,然后用 JavaScript 渲染出来的。接下来,可以切换到 XHR 过滤选项卡, 查看有没有 Ajax 请求。
- 实战演练
- 实现方法 get_page()来加载单个 Ajax 请求的结果。其中唯一变化的参数就是 offset ,所以将它当作参数传递:
- 第二次请求的 offset 值为20,第三次为 40,第四次为 60 ,所以 offset 值就是偏移量。
import requests from urllib.parse import urlencode def get_page(offset): params = { 'offset': offset, 'format': 'json', 'keyword': '街拍', 'autoload': 'true', 'count': '20', 'cur_tab': '1', 'from': 'search_tab' } base_url = 'https://www.toutiao.com/search_content/?' url = base_url + urlencode(params) try: resp = requests.get(url) if codes.ok == resp.status_code: return resp.json() except requests.ConnectionError: return None
这里用 urlencode()方法构造请求的 GET 参数,然后用 requests 请求这个链接,如果返回状 态码为 200(ok),则调用 response 的 json()方法将结果转为 JSON 格式,然后返回。
-
再实现一个解析方法:提取每条数据的 image_list 字段中的每一张图片链接,将图片链接和图片所属的标题一并返回,此时可以构造一个生成器。实现代码:
def get_images(json): if json.get('data'): data = json.get('data') for item in data: if item.get('cell_type') is not None: continue title = item.get('title') images = item.get('image_list')for image in images: yield { 'image': 'https:' + image.get('url'), 'title': title }
-
接下来,实现一个保存图片的方法 save_image(),其中 item 是前面 get_images()方法返回的字典。首先根据 item 的 title 来创建文件夹,然后请求图片链接,获取图片的二进制数据,以二进制的形式写入文件。图片的名称可以使用其内容的 MD5 值,这样可以去除重复。代码:
import os from hashlib import md5 def save_image(item): img_path = 'img' + os.path.sep + item.get('title') if not os.path.exists(img_path): os.makedirs(img_path) try: resp = requests.get(item.get('image')) if codes.ok == resp.status_code: file_path = img_path + os.path.sep + '{file_name}.{file_suffix}'.format( file_name=md5(resp.content).hexdigest(), file_suffix='jpg') if not os.path.exists(file_path): with open(file_path, 'wb') as f: f.write(resp.content) print('Downloaded image path is %s' % file_path) else: print('Already Downloaded', file_path) except requests.ConnectionError: print('Failed to Save Image,item %s' % item)
-
最后,只需要构造一个时fset 数组,遍历 offset ,提取图片链接,并将其下载:
from multiprocessing.pool import Pool def main(offset): json = get_page(offset) for item in get_images(json): print(item) save_image(item) GROUP_START = 0 GROUP_END = 7 if __name__ == '__main__': pool = Pool() groups = ([x * 20 for x in range(GROUP_START, GROUP_END + 1)]) pool.map(main, groups) pool.close() pool.join()
定义分页的起始页数和终止页数,分别为 GROUP_START和 GROUP_END ,利用了多线程的线程池,调用其 map()方法实现多线程下载。
- 第二次请求的 offset 值为20,第三次为 40,第四次为 60 ,所以 offset 值就是偏移量。
- 实现方法 get_page()来加载单个 Ajax 请求的结果。其中唯一变化的参数就是 offset ,所以将它当作参数传递: