静态库的缺点:
- 库函数被包含在每一个运行的进程中,会造成主存的浪费。
- 目标文件的size过大
- 每次更新一个模块都需要重新编译,更新困难,使用不方便。
动态库: 是一个目标文件,包含代码和数据,它可以在程序运行时动态的加载并链接。修改动态库不需要重新编译目标文件,只需要更新动态库即可。动态库还可以同时被多个进程使用。在linux下生成动态库 gcc -c a.c -fPIC -o a.o gcc -shared -fPIC a.o -o a.so. 这里的PIC含义就是生成位置无关代码,动态库允许动态装入修改,这就必须要保证动态库的代码被装入时,可执行程序不依赖与动态库被装入的位置,即使动态库的长度发生变化也不会影响调用它的程序。
动态链接器:
在加载可执行文件时,加载器发现在可执行文件的程序头表中有.interp段,其中包含了动态连接器路径ld-linux.so . 加载器加载动态链接器,动态链接器完成相应的重定位工作后,再将控制权交给可执行文件。

程序头: Type Offset VirtAddr PhysAddr FileSiz MemSiz Flags Align PHDR 0x0000000000000040 0x0000000000400040 0x0000000000400040 0x00000000000001f8 0x00000000000001f8 R E 8 INTERP 0x0000000000000238 0x0000000000400238 0x0000000000400238 0x000000000000001c 0x000000000000001c R 1 [正在请求程序解释器:/lib64/ld-linux-x86-64.so.2]
位置无关代码PIC:
其中动态库用到的一个核心概念就是与代码无关PIC。共享库代码位置可以是不确定的,即使代码长度发生变化也不影响调用它的程序,动态链接器是不会把可执行文件的代码段数据段与动态链接库合并的。那么这里牵涉到模块内与模块间的引用和跳转问题。
模块内的跳转和引用:
目标文件与静态库中模块内的跳转大致相同。如下代码:
//b.c
static int temp = 12344; extern int a; void add(int c) { a += c; temp += c; }
//a.c
int a = 1000;
void add(int c);
int main()
{
int c = 123;
add(c);
return 0;
}
我们将b.c编译为动态库,这里的temp就是模块内的引用,我们将动态库反编译可以看到
471 00000000000006a8 <add>: 472 6a8: 55 push %rbp 473 6a9: 48 89 e5 mov %rsp,%rbp 474 6ac: 89 7d fc mov %edi,-0x4(%rbp) 475 6af: 48 8b 05 2a 09 20 00 mov 0x20092a(%rip),%rax # 200fe0 < _DYNAMIC+0x1d0> 476 6b6: 8b 10 mov (%rax),%edx 477 6b8: 8b 45 fc mov -0x4(%rbp),%eax 478 6bb: 01 c2 add %eax,%edx 479 6bd: 48 8b 05 1c 09 20 00 mov 0x20091c(%rip),%rax # 200fe0 < _DYNAMIC+0x1d0> 480 6c4: 89 10 mov %edx,(%rax) 481 6c6: 8b 15 5c 09 20 00 mov 0x20095c(%rip),%edx # 201028 < temp> 482 6cc: 8b 45 fc mov -0x4(%rbp),%eax 483 6cf: 01 d0 add %edx,%eax 484 6d1: 89 05 51 09 20 00 mov %eax,0x200951(%rip) # 201028 < temp>
785 0000000000201028 <temp>: #数据段temp
786 201028: 38 30 cmp %dh,(%rax)
这里的mov 0x20095c(%rip),%edx 取rip中下一条指令地址+0x20095c 的数据放到edx寄存器中,地址为0x201028 正是temp的地址。模块内的函数跳转与此类似。
模块间的跳转和引用:
首先看一下全局变量的引用,看上例中b.so的反编译 这里引用了一个全局变量a 它的定义在另一个模块a.o 中
471 00000000000006a8 <add>: 472 6a8: 55 push %rbp 473 6a9: 48 89 e5 mov %rsp,%rbp 474 6ac: 89 7d fc mov %edi,-0x4(%rbp) 475 6af: 48 8b 05 2a 09 20 00 mov 0x20092a(%rip),%rax # 200fe0 < _DYNAMIC+0x1d0> 476 6b6: 8b 10 mov (%rax),%edx 477 6b8: 8b 45 fc mov -0x4(%rbp),%eax 478 6bb: 01 c2 add %eax,%edx 479 6bd: 48 8b 05 1c 09 20 00 mov 0x20091c(%rip),%rax # 200fe0 < _DYNAMIC+0x1d0> 764 Disassembly of section .got: 765 766 0000000000200fd0 <.got>: 767 ... 768 769 Disassembly of section .got.plt: 770 771 0000000000201000 <_GLOBAL_OFFSET_TABLE_>: 772 201000: 10 0e adc %cl,(%rsi) 773 201002: 20 00 and %al,(%rax)
这里的mov 取地址是一个got数组的某个地址。GOT 全局偏移表,在data段的开始处的一个指针数组,每一个指针可以指向一个全局变量, GOT与引用数据的指令之间的相对距离固定,编译器为GOT每一项生成一个重定位项,加载时 动态链接器对GOT中的各项进行重定位,填入引用的地址。(32位 占4个字节 64位 8个字节)

每一个引用全局数据的目标模块都有一张自己的GOT,那么就需要一个额外的寄存器来保持GOT表目的地址。至于模块间的函数调用和跳转也可以使用此模块,但是这种情况下过程调用都要求三条额外的指令,Linux这里就使用了叫做延迟绑定的技术,将过程调用的绑定推迟到第一次调用该过程。这种技术是通过俩个数据结构之间的交互来实现,即GOT 和PLT 全局偏移表和过程链接表, 如果一个目标模块调用定义在共享库中的任何函数,那么它就有自己的GOT和PLT,GOT是data节的一部分,PLT是text节的一部分<深入理解计算机系统>
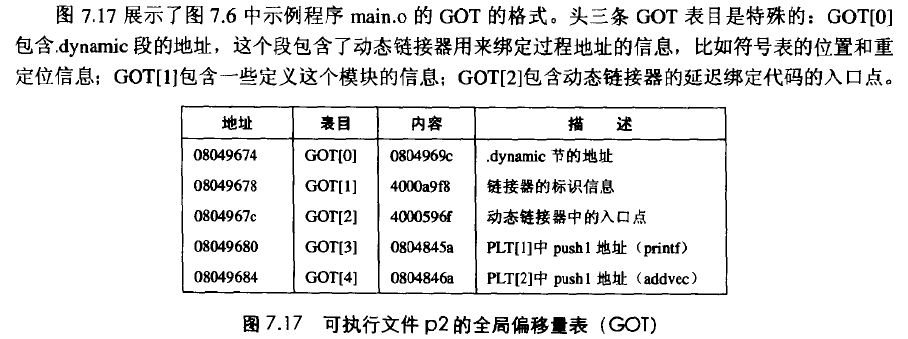
上图为 32 位linux。 从GOT[3]开始才是函数调用地址。我们将a.c b.so编译链接为可执行文件a, 反汇编a 观察函数add的调用(无关代码已省略)。(64位机器)
Disassembly of section .plt: 0000000000400580 <add@plt-0x10>: 400580: ff 35 82 0a 20 00 pushq 0x200a82(%rip) # 601008 <_GLOBAL_OFFSET_TABLE_+0x8> 400586: ff 25 84 0a 20 00 jmpq *0x200a84(%rip) # 601010 <_GLOBAL_OFFSET_TABLE_+0x10> 40058c: 0f 1f 40 00 nopl 0x0(%rax) 0000000000400590 <add@plt>: 400590: ff 25 82 0a 20 00 jmpq *0x200a82(%rip) # 601018 <_GLOBAL_OFFSET_TABLE_+0x18> // ////++++++++++++++++++++++ 400596: 68 00 00 00 00 pushq $0x0 40059b: e9 e0 ff ff ff jmpq 400580 <_init+0x20> 00000000004005a0 <__libc_start_main@plt>: 4005a0: ff 25 7a 0a 20 00 jmpq *0x200a7a(%rip) # 601020 <_GLOBAL_OFFSET_TABLE_+0x20> 4005a6: 68 01 00 00 00 pushq $0x1 4005ab: e9 d0 ff ff ff jmpq 400580 <_init+0x20> 00000000004006b0 <main>: 4006b0: 55 push %rbp 4006b1: 48 89 e5 mov %rsp,%rbp 4006b4: 48 83 ec 10 sub $0x10,%rsp 4006b8: c7 45 fc 7b 00 00 00 movl $0x7b,-0x4(%rbp) 4006bf: 8b 45 fc mov -0x4(%rbp),%eax 4006c2: 89 c7 mov %eax,%edi 4006c4: e8 c7 fe ff ff callq 400590 <add@plt> //call add-------------------------------- 4006c9: b8 00 00 00 00 mov $0x0,%eax 4006ce: c9 leaveq 4006cf: c3 retq Disassembly of section .got: 0000000000600ff8 <.got>: ... Disassembly of section .got.plt: #data段 无效反编译代码 0000000000601000 <_GLOBAL_OFFSET_TABLE_>: 601000: GOT[0] GOT 64位下每个条目8个字节 32位是4个字节 601008: GOT[1] 链接器标示信息
601010 GOT[2] 动态连接器入口地址 601017: 00 96 05 40 00 00 add %dl,0x4005(%rsi) 60101d: 00 00 add %al,(%rax) 60101f: 00 a6 05 40 00 00 add %ah,0x4005(%rsi) 601025: 00 00 add %al,(%rax) 601027: 00 b6 05 40 00 00 add %dh,0x4005(%rsi) 60102d: 00 00 add %al,(%rax) ...
我们可以看到main函数中跳转call add 跳转到了地址0x400590 处,执行 jmpq *0x200a82(%rip) 指令 跳转到 0x601018的地址 ,还是跳到GOT数组中的add位置。这个位置其实就是 jmpq *0x200a82(%rip)的下一条指令地址400596: 68 00 00 00 00 pushq $0x0。我们可以使用gdb看一下。
(gdb) disassemble main Dump of assembler code for function main: 0x00000000004006b0 <+0>: push %rbp 0x00000000004006b1 <+1>: mov %rsp,%rbp 0x00000000004006b4 <+4>: sub $0x10,%rsp => 0x00000000004006b8 <+8>: movl $0x7b,-0x4(%rbp) 0x00000000004006bf <+15>: mov -0x4(%rbp),%eax 0x00000000004006c2 <+18>: mov %eax,%edi 0x00000000004006c4 <+20>: callq 0x400590 <add@plt> 0x00000000004006c9 <+25>: mov $0x0,%eax 0x00000000004006ce <+30>: leaveq 0x00000000004006cf <+31>: retq End of assembler dump. (gdb) disassemble 0x400590 Dump of assembler code for function add@plt: 0x0000000000400590 <+0>: jmpq *0x200a82(%rip) # 0x601018 <add@got.plt> 这个地址就是GOT数组中add对应的那条 0x0000000000400596 <+6>: pushq $0x0 0x000000000040059b <+11>: jmpq 0x400580 End of assembler dump. (gdb) x 0x601018 0x601018 <add@got.plt>: 0x00400596
pushq $0x0 这条指令将add符号的ID压入栈,然后 jmpq 0x400580 它将会跳转到PLT[0]接下来的指令就是:
0000000000400580 <add@plt-0x10>: 400580: ff 35 82 0a 20 00 pushq 0x200a82(%rip) # 601008 <_GLOBAL_OFFSET_TABLE_+0x8> 链接器标示信息入栈 前面还有个ID 400586: ff 25 84 0a 20 00 jmpq *0x200a84(%rip) # 601010 <_GLOBAL_OFFSET_TABLE_+0x10> 跳转到链接器入口地址 40058c: 0f 1f 40 00 nopl 0x0(%rax)
跳转到动态连接器之后,链接器根据这两个栈中的信息(其实就是重定位描述符地址和索引值)得到 add的实际地址, 在将地址放入GOT[3]中 通过gdb详细看一下。
(gdb) n 6 add(c); 运行 add之前 (gdb) x /32x 0x601010 0x601010: 0xf7df0210 0x00007fff 0x00400596 0x00000000
这时GOT[3]add地址还不是add的实际地址 而是0000000000400590<add@plt>: jmp的目的地址0x00400596 0x601020 <__libc_start_main@got.plt>: 0xf7839a20 0x00007fff 0x004005b6 0x00000000 0x601030: 0x00000000 0x000003e8 0x00000000 0x00000000 0x601040: 0x00000000 0x00000000 0x00000000 0x00000000 0x601050: 0x00000000 0x00000000 0x00000000 0x00000000 0x601060: 0x00000000 0x00000000 0x00000000 0x00000000 0x601070: 0x00000000 0x00000000 0x00000000 0x00000000 0x601080: 0x00000000 0x00000000 0x00000000 0x00000000 (gdb) print add $2 = {<text variable, no debug info>} 0x7ffff7bd96a8 <add> add函数的地址 (gdb) n 7 return 0; (gdb) x /32x 0x601010 0x601010: 0xf7df0210 0x00007fff 0xf7bd96a8 0x00007fff
进入add GOT[3]中地址变为了 add的实际地址 再之后的
0000000000400590 <add@plt>: jmpq *0x200a82(%rip) 就会直接跳到add的地址 开始执行指令。
0x601020 <__libc_start_main@got.plt>: 0xf7839a20 0x00007fff 0x004005b6 0x00000000 0x601030: 0x00000000 0x00000463 0x00000000 0x00000000 0x601040: 0x00000000 0x00000000 0x00000000 0x00000000 0x601050: 0x00000000 0x00000000 0x00000000 0x00000000 0x601060: 0x00000000 0x00000000 0x00000000 0x00000000 0x601070: 0x00000000 0x00000000 0x00000000 0x00000000 0x601080: 0x00000000 0x00000000 0x00000000 0x00000000
这里可以看到被引用的函数调用之前 GOT中的地址并没有被值为函数的实际地址。之后实际地址就被装入,跳转到相应地址开始执行,之后就可以直接跳转运行了,只需要一个跳转指令即可。