概
从 stochastic differential equation (SDE) 角度看 diffusion models.
符号说明
- \(\bm{x}(t), t \in [0, T]\) 为 \(\bm{x}\) 在时间 \(t\) 的一个状态;
- \(p_t(\bm{x}) = p(\bm{x}(t))\), \(\bm{x}\) 在时间 \(t\) 所服从的分布;
- \(p_{st}(\bm{x}(t)|\bm{x}(s)), 0 \le s < t \le T\), 从 \(\bm{x}(s)\) 到 \(\bm{x}(t)\) 的转移核 (transition kernel);
- \(\bm{s}_{\theta}(\bm{x}, t)\), 为 score \(\nabla_{\bm{x}} \log p_t(\bm{x})\) 的一个近似, 通常用神经网络拟合.
Wiener process
Wiener process \(X(t, w)\) 是这样的一个随机过程:
- \(X(0) = 0\);
- \(X(t+\Delta t) - X(t)\) 和 \(X(s)\) 是独立的 (感觉就是马氏性);
- \(X(t + \Delta t) - X(t) \sim \mathcal{N}(0, \Delta t)\), 服从方差为 \(\Delta t\) 的正态分布;
- \(\lim_{\Delta \rightarrow 0} X(t + \Delta t) = X(t)\), 关于 \(t\) 是连续的.
本文所关注的是带 drift \(\mu\) 的 Wiener 随机过程:
其中 \(W_t\) 服从一般的 Wiener process.
我们可以用下列的 SDE 来描述该随机过程中的增量 (一般形式):
其中
其中 \(\text{d} \bm{w}\) 特指一般 Wiener process 中的增量, 即 \(\bm{w}(t + \Delta t) - \bm{w}(t) \sim \mathcal{N}(\bm{0}, \Delta t)\).
它的逆过程可以描述为:
主要内容
- \(\bm{x}(0) \rightarrow \bm{x}(T)\), 逐渐加噪的过程;
- \(\bm{x}(T) \rightarrow \bm{x}(0)\), 逐步采样的过程.
而这两个方程可以看成是两个(正反) SDE 的离散过程.
反向采样
我们首先讲反向采样, 这样会更容易理解前向中的一些设计. 我们知道, 一旦有了 (SDE-) 和 score function \(\nabla_x \log p_t(\bm{x})\), 就可以通过一些离散求解方法去逐步'生成'解 \(\bm{x}(0)\) 了.

Numerical SDE solvers
有很多数值解法可以用于反向采样: Euler-Maruyama, stochastic Runge-Kutta methods, Ancestral sampling.
本文提出了一种 reverse diffusion sampling (Ancestral sampling 是这个的一特例):
- 对于\[\text{d} \bm{x} = \bm{f}(\bm{x}, t) \text{d} t + \bm{G}(\bm{x}, t) \text{d} \bm{w}, \]采用\[\bm{x}_{i + 1} = \bm{x}_i + \bm{f}_i(\bm{x}_i) + G_i \bm{z}_i, i=0,1,\cdots, N - 1 \]的更新方式;
- 类似地, 对于(简化)\[\text{d} \bm{x} = \{ \bm{f}(\bm{x}, t) - \bm{G}(\bm{x}, t) \bm{G}(\bm{x}, t)^T \nabla_{\bm{x}} \log p_t(\bm{x}) \} \text{d} t + \bm{G}(t) \text{d} \bm{w}, \]采用 (注意, 符号是反的)\[\bm{x}_i = \bm{x}_{i + 1} - \bm{f}_{i+1}(\bm{x}_{i+1}) + \bm{G}_{i+1} \bm{G}_{i+1}^T \nabla_{\bm{x}} \log p_{i+1}(\bm{x}_{i+1}) + \bm{G}_{i+1} \bm{z}_{i+1}. \]
Predictor-corrector samplers
假设我们知道 \(\nabla_x \log p_t(\bm{x})\) 或者它的一个近似 \(\bm{s}_{\theta}(\bm{x}, t)\). 我们就可以通过 score-based MCMC 来采样了, 比如 Langevin MCMC 和 HMC (here).
利用 Langevin MCMC, 步骤如下:
其中 \(\epsilon\) 为步长.
注: MCMC 采样的过程是保证连续采样的点最终趋向于分布 \(p(\bm{x})\), 而不是说整个流程产生点符合 inverse 随机过程 !
整体的 PC samplers 框架如下:

其中 Predictor 可以是任意的 numeric solvers, Corrector 是 MCMC. 这相当于, 通过数值求解随机过程, 但是由于存在误差, 可能导致实际的 \(\bm{x}_i\) 偏离它的分布, 故再通过 MCMC 进行纠正.
Probability Flow
这部分, 作者将 SDE 转换成了一个 ODE, 从而能够确定性地采样, 但是这部分内容没怎么看懂, 就只在这里记一笔. 需要注意的是, 和 SDE 不一样, 因为 ODE 不含随即项, 故我们可以通过现成的 black-box ODE solver 来求解方程, 并且通过给定不同的 \(\bm{x}(T) \sim p_T\), 便能有不同的解.
其大致流程如下:
条件采样
条件采样, 即给定 \(\bm{y}(0)\), 我们希望从条件分布
中采样. 一般来说, 我们会通过贝叶斯公式得到
但是我们通常难以估计先验 \(p(\bm{x}(0))\) 和 \(p(\bm{y}(0))\).
我们可以通过下列的 inverse-time SDE 来从 \(p_t(\bm{x}(t) | \bm{y})\) 中采样:
又
故当 \(\nabla_x \log p_t (\bm{y}(0)|\bm{x}(t))\) 可知时, 我们就可以采样了.
接下来, 我们讨论 \(p_t(\bm{y}(0)|\bm{x}(t))\) 可估计和难以直接估计的情况
可估计的情况
- \(\bm{y}(0)\) 为分类任务中的标签;
- 采样 \(\bm{x}(t)\);
- 利用交叉熵损失 训练一个 time-dependent 分类器:\[p_t(\bm{y}(0) | \bm{x}(t)). \]
难以估计的情况
此时我们注意到:
我们给出下面两个合理的假设:
- \(p(\bm{y}(t) | \bm{y}(0))\) 是可求的;
- \(p_t(\bm{x}(t)|\bm{y}(t), \bm{y}(0)) \approx p_t(\bm{x}(t)|\bm{y}(t))\), 这是因为对于 \(t\) 比较小的情况, \(\bm{y}(t) \approx \bm{y}(0)\), 而对于 \(t\) 比较大的情况, \(\bm{x}(t)\) 受 \(\bm{y}(t)\) 影响最大.
此时有
此时只要 \(\nabla_x \log p_t(\hat{y}(t)|\bm{x}(t))\) 可知便可代入求解了.
下面以 Imputation 为例进行讲解. 假设 \(\Omega(\bm{x}), \bar{\Omega}(\bm{x})\) 分别表示 观测的 和 缺失的 部分. 我们的目的是从
中采样. 按照上面的步骤, 我们只需要估计
即可. 实际上, 注意到由于本文的建模都是 element-wise 的, 所以
即仅 \(\hat{\Omega}\) 区域需要采样.
注: 这里的内容和原文 Appendix I.2 的推导有较大出入, 我是按照我自己的理解来的, 也没有实验过, 准确性存疑 !
前向扰动
根据前面的流程, 我们知道, 倘若我们能够估计出
那么我们就可以跟着随机过程一步一步地采样了, 而这需要用到 (denosing) score matching 作为训练目标:
其中 \(\lambda(\cdot)\) 为正的权重, 通常选择 \(\lambda \propto 1 / \mathbb{E} [\|\nabla_{\bm{x}(t)} \log p_{0t} (\bm{x}(t)|\bm{x}(0))\|_2^2]\), \(t \sim \mathcal{U}[0, T]\).
从上面目标函数的定义可知, 一般来说, 只有 \(p_{0t}\) 是显式可求的上面的才有意义, 对于更加一般的随机过程, 可以用 slice score matching 来绕开其中复杂的计算 (不过需要以更多的计算量为代价). 下面所介绍的, 都是可求的高斯分布.
SMLD
SMLD 定义了 \(\{\bm{x}_i\}_{i=1}^N\), 可以看成是 \(t = \frac{i}{N} \in [0, T = 1]\) 的离散的随机过程:
且满足
此时有:
我们进一步将其改写成 SDE 的形式 (即令 \(N \rightarrow \infty\) ):
当 \(\Delta t \rightarrow 0\) 时 (即 \(N \rightarrow \infty\) ) 有:
最后, 我们容易发现增量 \(\sqrt{\Delta t} \bm{z}(t) \sim \mathcal{N}(\bm{0}, \Delta t)\), 所构成的随机过程自然满足 Wiener process, 故
即不存在 drift 量.
DDPM
DDPM 定义了 \(\{\bm{x}_i\}_{i=1}^N\), 可以看成是 \(t = \frac{i}{N} \in [0, T = 1]\) 的离散的随机过程:
令 \(\bar{\beta}_i := N \beta_i\), 并定义
则 (3) 可以改写为
当 \(\Delta \rightarrow 0\), 有
其中第二项由一阶泰勒近似可以得到, 第二项和 SMLD 中的推理是类似的.
最后, 可以总结为如下的 Wiener process:
接下来我们推导一下 DDPM 的 \(\bm{x}(t)\) 的条件分布. (3+) 两边取期望可知
其中 \(\bm{e}(t) = \mathbb{E}[\bm{x}(t)]\), 则
加上初值条件 \(\bm{e}(0) = \bm{e}_0\), 可得:
而 \(\bm{x}(t)\) 的协方差矩阵 \(\Sigma_{VP}(t)\) 满足
加上初始值 \(\Sigma_{VP}(0)\)可得
故服从
在已知 \(\bm{x}(0)\) 的条件下, \(\bm{e}(0) = \bm{x}(0), \Sigma_{VP}(0) = 0\), 故
注: 方差的公式的推导在另一篇论文中, 这里的方差求解是一般的基础的.
拓展
通过 SMLD 和 DDPM 两个例子可以发现, 我们只需要个性化定制 \(\bm{f}(\bm{x}, t)\) 和 \(\bm{G}(\bm{x}, t)\), 即可构造不同的前向扰动过程. 实际上, SMLD 和 DDPM 代表了两种不同的 SDE: Variance Exploding (VE) SDE 和 Variance Preserving (VP) SDE. 这是因为 SMLD 要求 \(\sigma_{\max} \rightarrow \infty\) 而由上面的推导可得, 倘若 \(\Sigma_{VP}(0) = I\) 或者 \(\int_{0}^t \beta (s) \text{d}s \rightarrow +\infty\)时, 方差都是收敛的.
sub-VP SDE
受 DDPM VP SDE 性质的启发, 作者设计了一种新的前向扰动过程:
和 DDPM 一样, \(\bm{x}(t)\) 的期望
而协方差为
它有两个性质:
- 当 \(\Sigma_{VP}(0) = \Sigma_{sub-VP}(0)\)时, \(\Sigma_{sub-VP} \preceq \Sigma_{VP}\), 即拥有更小的方差;
- \(\lim_{t \rightarrow} \Sigma_{sub-VP}(t) = I\) 当 \(\int_0^{+\infty} \beta(s) \text{d} s = +\infty\).
此外它的条件分布为:
具体的采样算法
PC sampling

Corrector
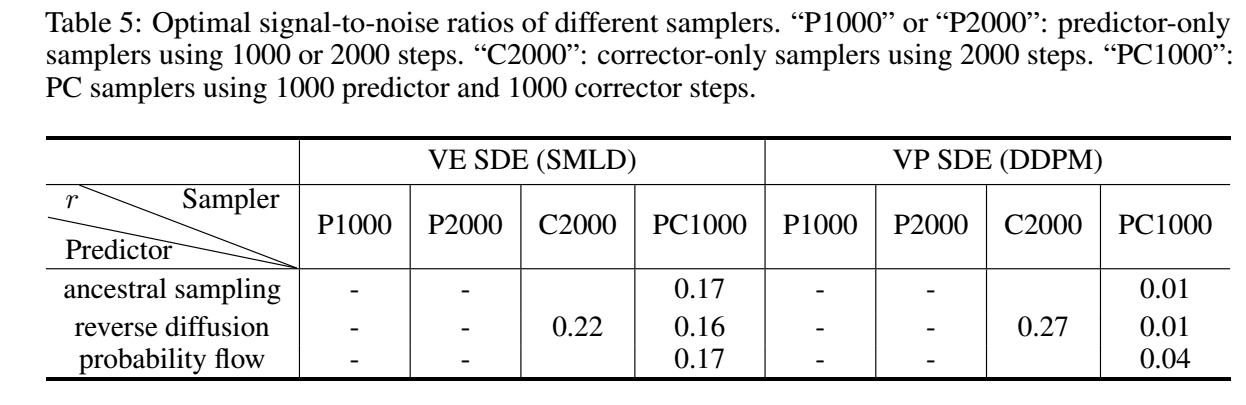
这里, 作者直接构造步长, 需要注意的是, 这里的 \(r\) 代表信噪比.

其它细节
- 网络结构: 和 DDPM 中的一致;
- 训练采用 \(N=1000\) scales;
- 采样的时候, 最后得到的 \(\bm{x}(0)\) 会带有人眼无法察觉但是影响 FID 指标的噪声, 故需要在结束的时候和 DDPM 一样接入去噪环节 (Tweedies' formula);
- 虽然训练的时候采取 \(N=1000\), 但是采样的时候可以 \(N=2000\) 甚至更多, 这个时候需要插值, 比如
- 最优的 信噪比 (singal-to-noise) \(r\) 如下图所示:
代码
[official]