概
一篇非常传统的用因果解决 popular bias 的文章, 文中的术语可以借鉴一下.
符号说明
- \(\mathcal{U} = \{u_1, u_2, \cdots, u_n\}\), 用户;
- \(\mathcal{I} = \{i_1, i_2, \cdots, i_m\}\), items;
- \(Y \in \mathbb{R}^{n \times m}\), 交互矩阵, \(y_{ui} = 1\) 若用户 \(u\) 和产品 \(i\) 发生过交互, 否则为 \(y_{ui} = 0\);
因果模型

以上(左)图为例, \(I\) 是 \(K, Y\) 的共同祖先, 而 \(K\) 也是 \(Y\) 的祖先, 则我们可以用
\[Y_{i, k}
\]
来表示 \(do(I = i, K = k)\) 下 \(Y\) 的一个情况 (虽然这个简单情形, 等价于条件概率, 还是用 \(do\) 以作区分).
当 仅 \(do(I = i)\) 时, 表示成 \(Y_i = Y_{i, K_i}\).
- 通常用 causal effect 来衡量前提 \(i\) 对 \(Y\) 的一个影响程度:
\[\text{TE} := Y_{i} - Y_{i^*} = Y_{i, K_i} - Y_{i^*, K_{i^*}}.
\]
\(i^*\) 可以理解是一个默认值.
- 通常用 natural direct effect (NDE) 来衡量前提 \(i\) 对 \(Y\) 的一个直接影响 (而非通过 \(K\)):
\[\text{NDE} = Y_{i, K_{i^*}} - Y_{i^*, K_{i^*}}.
\]
- 相应的, 有衡量主要经过 \(K\) 造成的间接影响 total indirect effect (TIE):
\[\text{TIE} = Y_{i, K_i} - Y_{i, K_{i^*}} = \text{TE} - \text{NDE}.
\]
主要内容
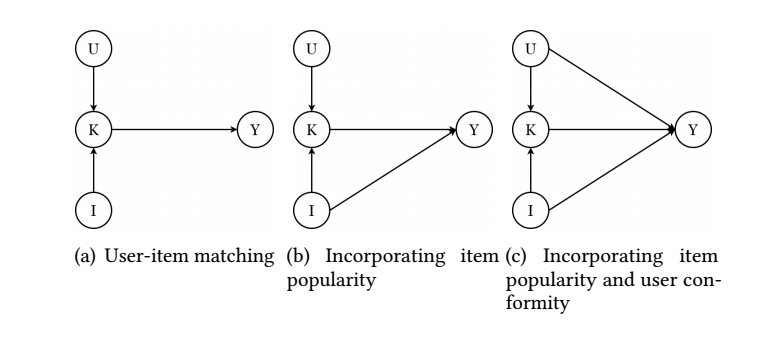
一般的推荐系统模型是通过用户 \(u\) 和产品 \(i\) 的一个匹配程度 \(\hat{y}_k\), 并以此为标准判断是否要进行推荐. 这种模式可以用上图的 (a) 来表示. 但是这种完全依赖匹配程度的预测是不准确的. 实际上:
- 对于两个功能相同的物品而言, 较为流行的那个往往更容易被用户所选择, 故产品 \(I\) 往往能够直接影响 \(Y\), 即 \(I \rightarrow Y\);
- 对于不同的用户而言, 有些用户喜欢探索流行的产品, 而有些用户则不然, 所以用户本身也会对 \(Y\) 产生直接的影响, \(U \rightarrow Y\).
所以更合理的因果模型应当如图 (c) 所示.
为此, 作者设计了如下的一个框架:
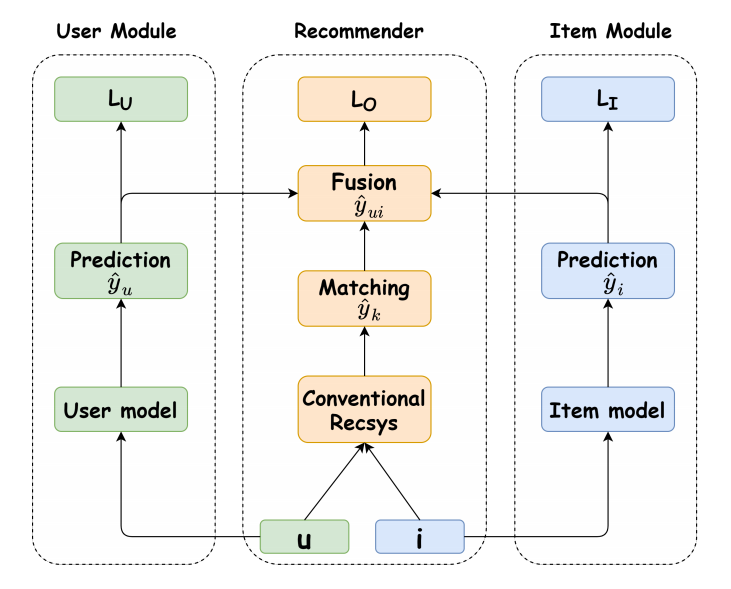
训练
- Recommender 部分, 以 \(u, i\) 为输入得到二者的匹配程度 \(\hat{y}_k\);
- User 部分, 以 \(u\) 为输入得到预测 \(\hat{y}_u\);
- Item 部分, 以 \(i\) 为输入得到预测 \(\hat{y}_i\);
- 将上述三者进行一个融合, 得到
\[\tag{1}
\hat{y}_{ui} = \hat{y}_k \cdot \sigma(\hat{y}_i) \cdot \sigma(\hat{y}_u),
\]
其中 \(\sigma\) 表示 Sigmoid.
- 训练 \(K \rightarrow Y\) 的一个预测能力:
\[L_O = \sum_{(u, i) \in D} -y_{ui} \log (\sigma(\hat{y}_{ui})) - (1 - y_{ui}) \log (1 - \sigma(\hat{y}_{ui}));
\]
- 训练 \(U \rightarrow Y\) 的一个预测能力:
\[L_O = \sum_{(u, i) \in D} -y_{ui} \log (\sigma(\hat{y}_{u})) - (1 - y_{ui}) \log (1 - \sigma(\hat{y}_{u}));
\]
- 训练 \(I \rightarrow Y\) 的一个预测能力:
\[L_O = \sum_{(u, i) \in D} -y_{ui} \log (\sigma(\hat{y}_{i})) - (1 - y_{ui}) \log (1 - \sigma(\hat{y}_{i})).
\]
注意到, 在融合的时候, (1) 中仅对 \(\hat{y}_i, \hat{y}_u\) 进行 \(\sigma(\cdot)\) 处理, 作者说这是为了突出 \(\hat{y}_k\) 的作用, 个人感觉这个显得不是那么的合理 (从概率角度).
推断
为了在推断的时候消除 \(I, U\) 本身引发的一些 bias, 作者希望通过 \(U, I \rightarrow\) 的一个 TIE 来进行预测, 即如下图 (b) 所示:
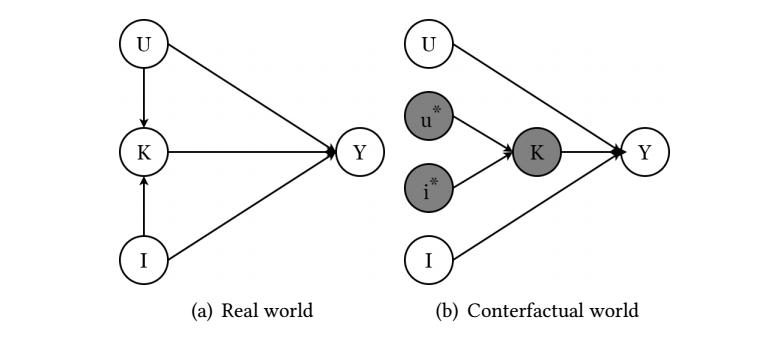
也可以用如下公式表示:
\[\text{TIE} = Y_{{u, i, K_{u,i}}} - Y_{u, i, K_{u^*, i^*}}
=\hat{y}_k \cdot \sigma(\hat{y}_i) \cdot \sigma(\hat{y}_u)
-c \cdot \sigma(\hat{y}_i) \cdot \sigma(\hat{y}_u),
\]
这里 \(c\) 是需要待定的一个超参数. 通过 \(\text{TIE}\) 的大小可以进行推荐.
总结
- 本文提出的方法可以说是显式地构建了一个所谓的合理的因果模型;
- 但是如何保证 \(\hat{y}_k\) 就是正确反映了二者匹配程度, 而不夹杂其它的 bias 呢?