参数化是干嘛的呢,咱们在调用接口的时候,有入参,那参数里面的值如果经常变化的话,就得每次去改了,很麻烦,这时候咱们就把需要经常变的值,改成可以变化的或者是咱们提前设置好的一些值,这样的话,调用的时候就不用每次都改它的值了。
一、参数化方式
Jmeter参数化的方式有三种
1、用户定义的变量
这种就是为了方便管理参数,只能有一个值,比如说ip地址不经常变化的
2、函数生成器
函数生成器可以参照一定的规则生成数据,这样的比如说生成一些随机数
3、从文件中读取
文件读取就是事先写好一些数据,然后从文件中读取,这样的话,比如说登录接口,账号和密码都是我们事先注册好的
二、用户定义的变量
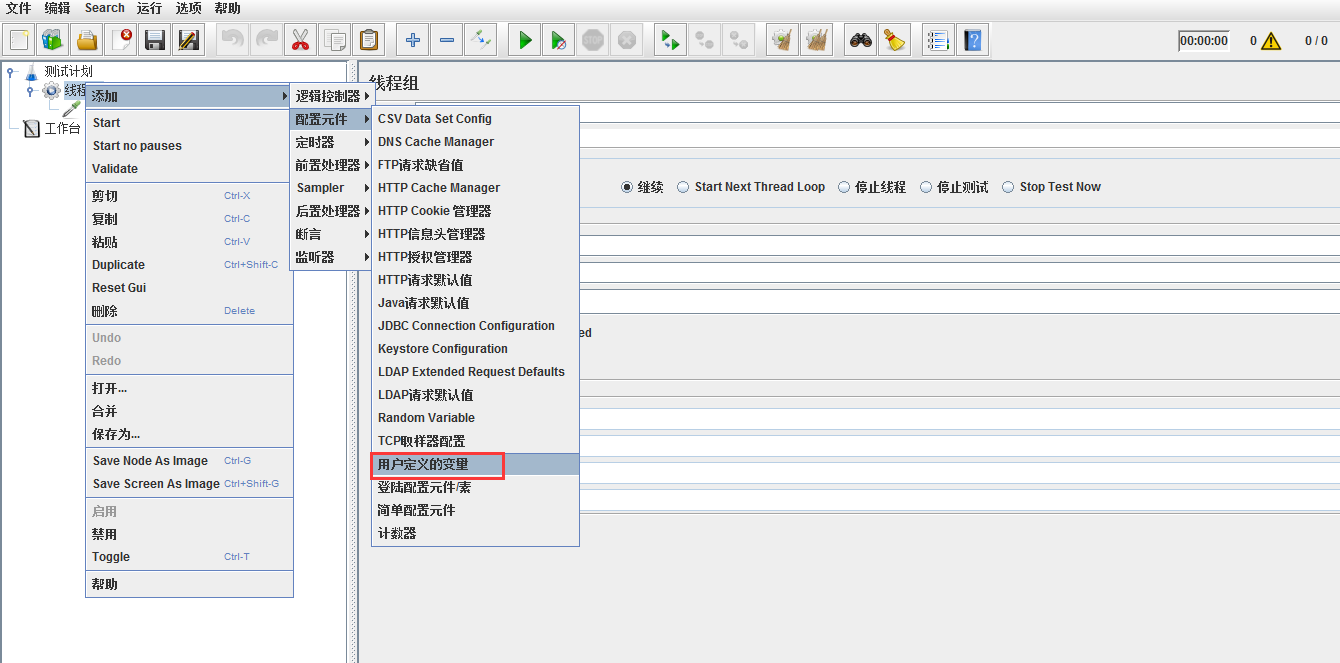
- 添加一个用户定义的变量
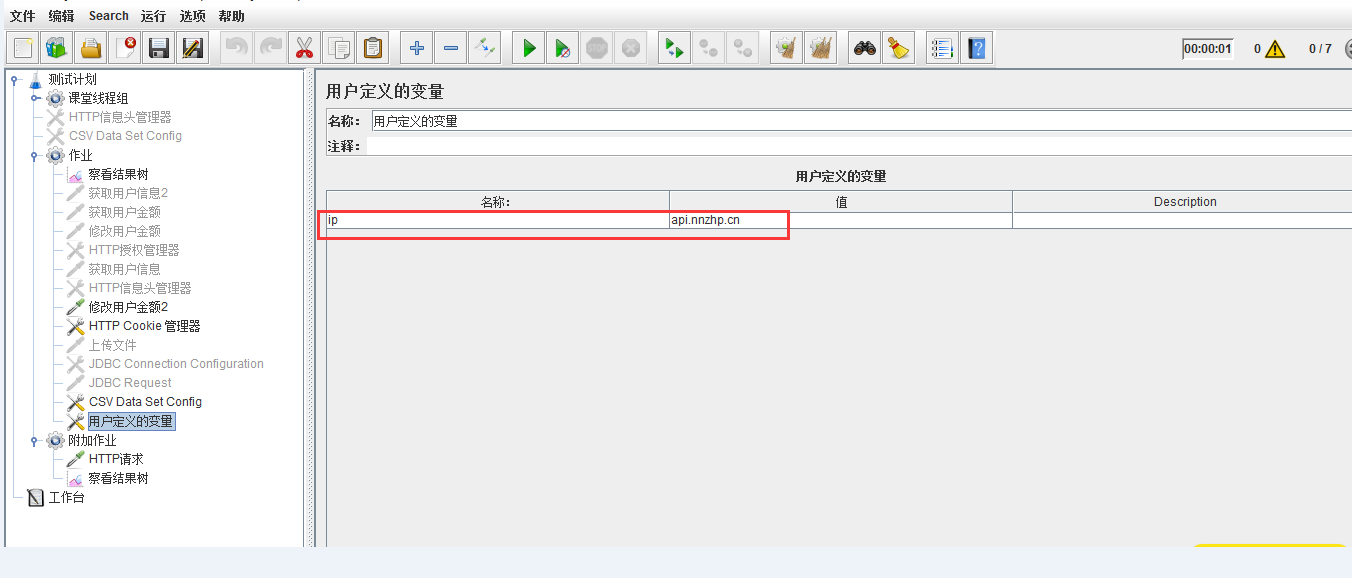
2.输入key和value,key就是这个参数的名称,也就是你在脚本里面取的值,value就是具体值了,如下为IP地址的参数化
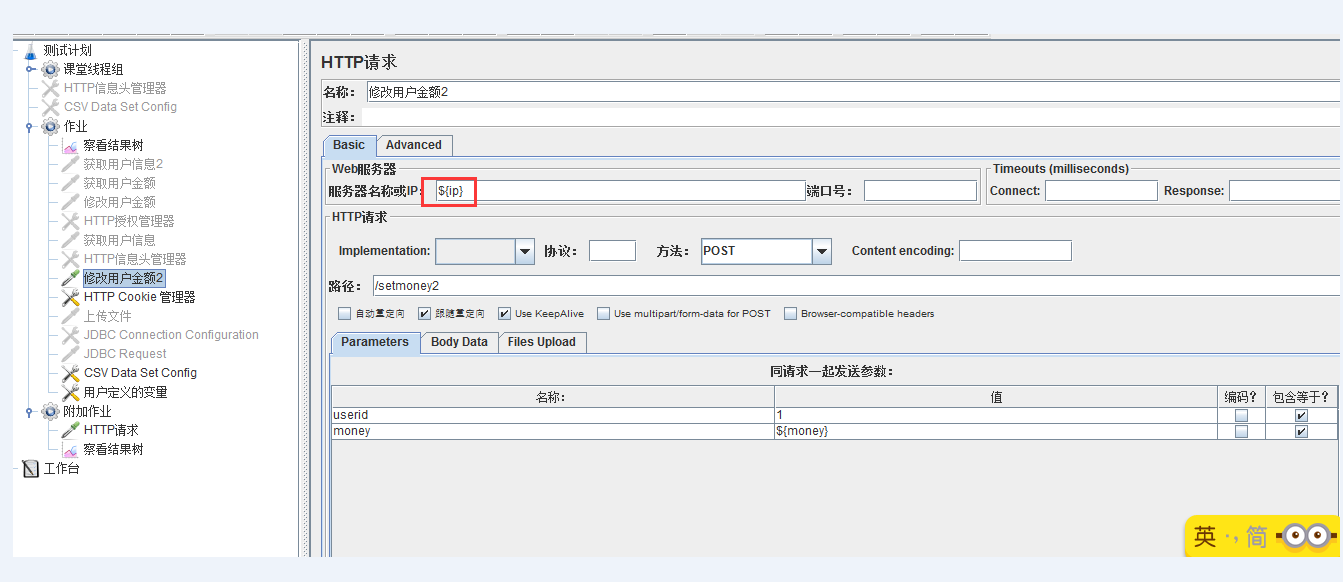
3. 在取参数化的值的时候,使用${ip}这样去取值,ip就是你取的变量名称。
二、函数生成器
函数助手的话,可以按照规则生成一些参数,比如说随机数取当前时间,最常用的就是这两种。
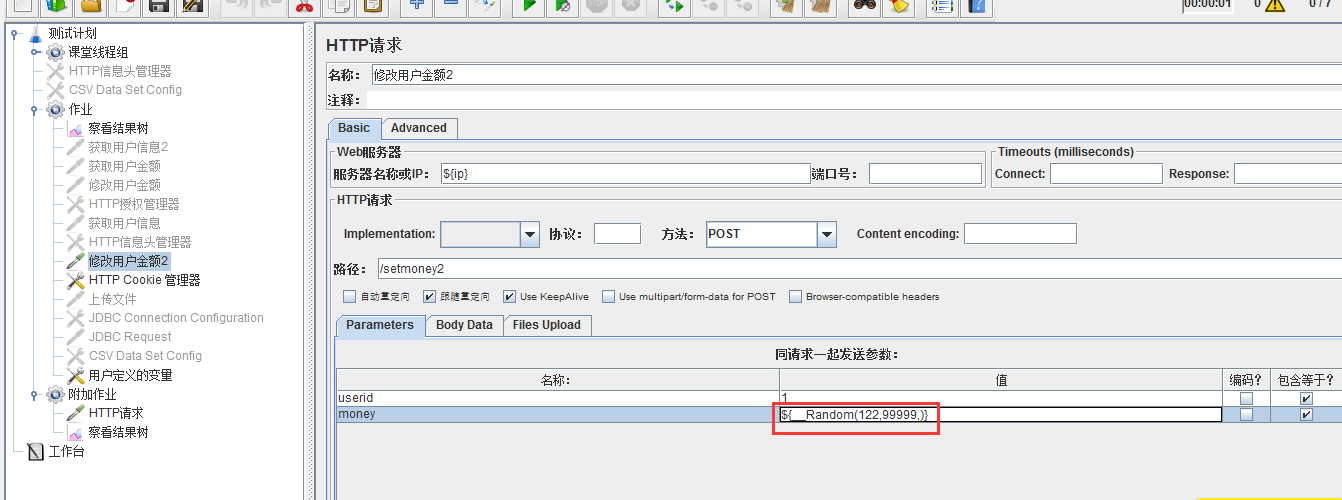
随机数__Random,可以在你指定的一个范围内取随机值
取当前时间__time,如果在有一些需要传时间的情况下可以使用,
日期格式是:yyyy-MM-dd HH:mm:ss 年-月-日-小时:分钟:秒
取唯一值__UUID,这个就是每次会生成一个随机的uuid,都是唯一的

将参数化的结果,放到请求的报文里如下:
三、从文件中读取
从文件中读取的话,三个步骤
1、读取文件
2、取文件内容里面的参数,给它一个名字
3、使用值
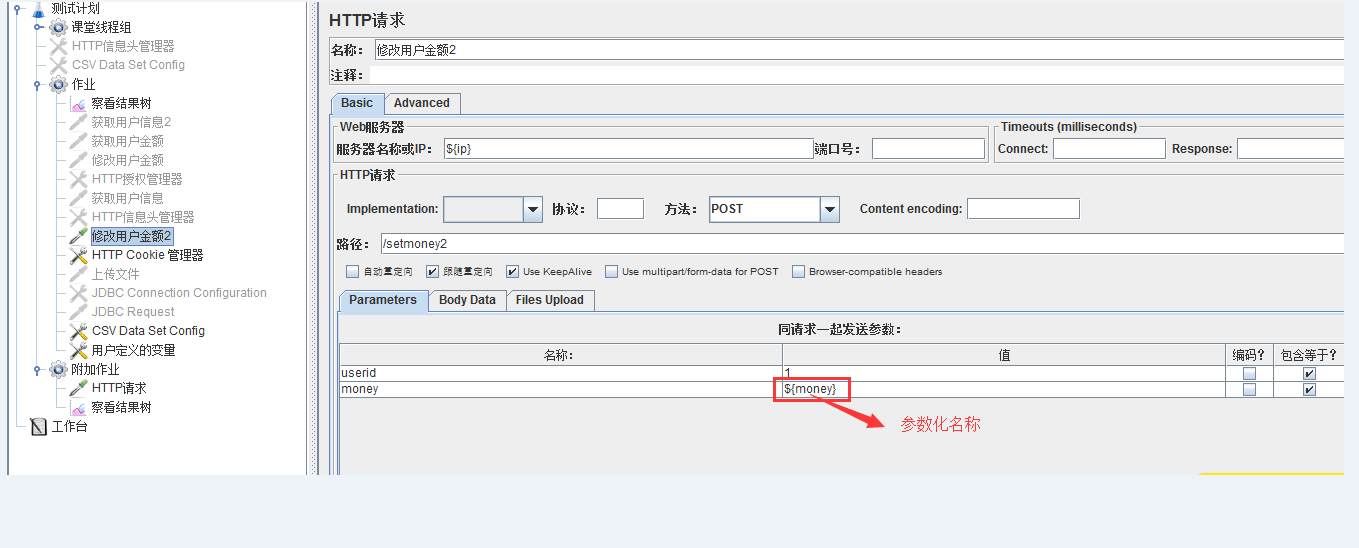
从文件读取的话,需要在线程组里面添加一个CSV Data Set Config,它就是做前面两步的操作的

将上述配置的参数化名称,放到请求报文里:
存放参数的文件内容编写如下,多个参数的话用”,”号区分