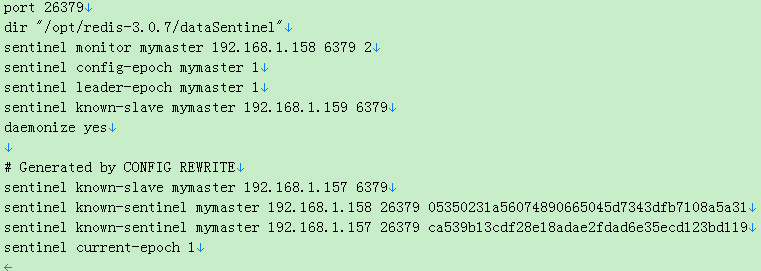
一、sentinel.conf
1 port 26379 2 dir /opt/redis-3.0.7/dataSentinel 3 sentinel monitor mymaster 192.168.1.157 6379 2 4 sentinel down-after-milliseconds mymaster 30000 5 sentinel parallel-syncs mymaster 1 6 sentinel failover-timeout mymaster 180000 7 daemonize yes
二、配置文件说明
1、port:当前 sentinel 服务运行的端口为 26379
2、dir:Sentinel服务运行时使用的临时文件夹为 /opt/redis-3.0.7/dataSentinel
3、sentinel monitor mymaster 195.168.1.157 6379 2:
1)表示 sentinel 监视一个名为 mymaster 的 redis 主实例,主实例IP地址为 195.168.1.157,端口为 6379
2)行末尾的“2”用于 sentinel 集群,当集群中有2个 sentinel 认为 master 宕掉时才会认定该 master 不可用
除了上述配置外我们发现接下来的配置项都依据如下格式
sentinel <option_name> <master_name> <option_value>
4、sentinel down-after-milliseconds mymaster 30000:
1)sentinel 会向 master 发送心跳 PING 来确认 master 是否存活,如果 maste r在“一定时间范围”内不回应 PONG 或者是回复了一个错误消息,那么这个 sentinel 会主观地(单方面地)认为这个 master 已经不可用了( subjectively down , 简称为 SDOWN )而这个 down-after-milliseconds 就是用来指定这个“一定时间范围”的,单位是毫秒
2)需要注意的是,这个时候 sentinel 并不会马上进行 failover 主备切换,这个 sentinel 还需要参考集群中其他 sentinel 的意见,如果超过某个数量的 sentinel 也主观地认为该 master 死了,那么这个 master 就会被客观地(objectively down,简称为 ODOWN)认为已经死了,需要一起做出决定的 sentinel 数量在上一条配置中进行配置
5、sentinel parallel-syncs mymaster 1:
1)在发生failover主备切换时,这个选项指定了最多可以有多少个 slave 同时对新的 master 进行同步,这个数字越小,完成 failover 所需的时间就越长,但是如果这个数字越大,就意味着越多的 slave 因为 replication 而不可用。可以通过将这个值设为 1 来保证每次只有一个slave处于不能处理命令请求的状态。
6、sentinel failover-timeout mymaster 180000:
1)如果在该时间(毫秒)内未能完成failover操作,则认为该failover失败
7、daemonize yes:
1)后台运行
三、部署及运行
1、将 sentinel.conf 拷贝到各主从节点的 redis 目录下,我的在 /opt/redis-3.0.7
2、进入 /opt/redis-3.0.7/src 执行 ./redis-sentinel /opt/redis-3.0.7/sentinel.conf 启动(启动的前提是各redis主从节点均已正常启动)
四、验证
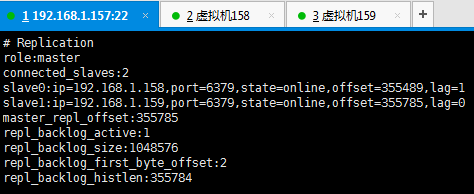
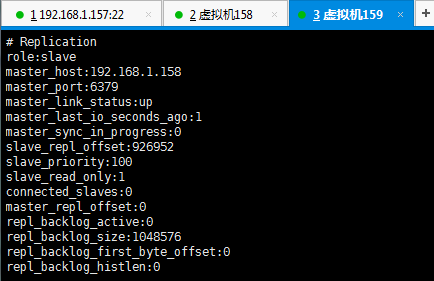
主节点:192.168.1.157
从节点:192.168.1.158、192.168.1.159
1、master 节点
1)info
2)sentinel.conf

2、slave节点(截图时主节点已经通过 sentinel 转换为158,正常情况图中 master 地址应为192.168.1.157)
1)info
2)sentinel.conf
五、总结
在编辑验证部分前已经通过对157虚拟机掉电测试,158成功被转换成master角色。
关闭 sentinel 可执行 ./redis-cli -p 26379 shutdown