(226条消息) 协方差矩阵的计算及意义_hi_linda的博客-CSDN博客_协方差矩阵计算
(226条消息) 什么是协方差,怎么计算?为什么需要协方差?_xiao_lxl的专栏-CSDN博客_协方差
声明:博文转自https://blog.csdn.net/mr_hhh/article/details/78490576
一、首先看一个比较简洁明了的协方差计算介绍:
1. 协方差定义
X、Y 是两个随机变量,X、Y 的协方差 cov(X, Y) 定义为:
其中,
2. 协方差矩阵定义
矩阵中的数据按行排列与按列排列求出的协方差矩阵是不同的,这里默认数据是按行排列。即每一行是一个observation(or sample),那么每一列就是一个随机变量。
协方差矩阵:
协方差矩阵的维度等于随机变量的个数,即每一个 observation 的维度。在某些场合前边也会出现 1 / m,而不是 1 / (m - 1).
3. 求解协方差矩阵的步骤
举个例子,矩阵 X 按行排列:
1. 求每个维度的平均值
2. 将 X 的每一列减去平均值
其中:
3. 计算协方差矩阵
---------------------
作者:Rise_1024
来源:CSDN
原文:https://blog.csdn.net/mr_hhh/article/details/78490576
版权声明:本文为博主原创文章,转载请附上博文链接!
二、再来看一下协方差矩阵的意义:
协方差代表的意义是什么?
在概率论中,两个随机变量 X 与 Y 之间相互关系,大致有下列3种情况:

情况一,如上, 当 X, Y 的联合分布像上图那样时,我们可以看出,大致上有: X 越大 Y 也越大, X 越小 Y 也越小,这种情况,我们称为“正相关”。

情况二, 如上图, 当X, Y 的联合分布像上图那样时,我们可以看出,大致上有:X 越大Y 反而越小,X 越小 Y 反而越大,这种情况,我们称为“负相关”。

情况三,如上图, 当X, Y 的联合分布像上图那样时,我们可以看出:既不是X 越大Y 也越大,也不是 X 越大 Y 反而越小,这种情况我们称为“不相关”。
怎样将这3种相关情况,用一个简单的数字表达出来呢?
在图中的区域(1)中,有 X>EX ,Y-EY>0 ,所以(X-EX)(Y-EY)>0;
在图中的区域(2)中,有 X<EX ,Y-EY>0 ,所以(X-EX)(Y-EY)<0;
在图中的区域(3)中,有 X<EX ,Y-EY<0 ,所以(X-EX)(Y-EY)>0;
在图中的区域(4)中,有 X>EX ,Y-EY<0 ,所以(X-EX)(Y-EY)<0。
当X 与Y 正相关时,它们的分布大部分在区域(1)和(3)中,小部分在区域(2)和(4)中,所以平均来说,有E(X-EX)(Y-EY)>0 。
当 X与 Y负相关时,它们的分布大部分在区域(2)和(4)中,小部分在区域(1)和(3)中,所以平均来说,有(X-EX)(Y-EY)<0 。
当 X与 Y不相关时,它们在区域(1)和(3)中的分布,与在区域(2)和(4)中的分布几乎一样多,所以平均来说,有(X-EX)(Y-EY)=0 。
所以,我们可以定义一个表示X, Y 相互关系的数字特征,也就是协方差
cov(X, Y) = E(X-EX)(Y-EY)
当 cov(X, Y)>0时,表明 X与Y 正相关;
当 cov(X, Y)<0时,表明X与Y负相关;
当 cov(X, Y)=0时,表明X与Y不相关。
这就是协方差的意义。
三、此部分进行更系统的说明:
声明:博文转自 https://blog.csdn.net/ybdesire/article/details/6270328
协方差的定义
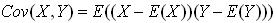
对于一般的分布,直接代入E(X)之类的就可以计算出来了,但真给你一个具体数值的分布,要计算协方差矩阵,根据这个公式来计算,还真不容易反应过来。网上值得参考的资料也不多,这里用一个例子说明协方差矩阵是怎么计算出来的吧。
记住,X、Y是一个列向量,它表示了每种情况下每个样本可能出现的数。比如给定
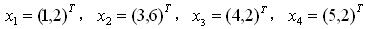
则X表示x轴可能出现的数,Y表示y轴可能出现的。注意这里是关键,给定了4个样本,每个样本都是二维的,所以只可能有X和Y两种维度。所以
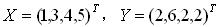
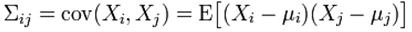
用中文来描述,就是:
协方差(i,j)=(第i列的所有元素-第i列的均值)*(第j列的所有元素-第j列的均值)
这里只有X,Y两列,所以得到的协方差矩阵是2x2的矩阵,下面分别求出每一个元素:
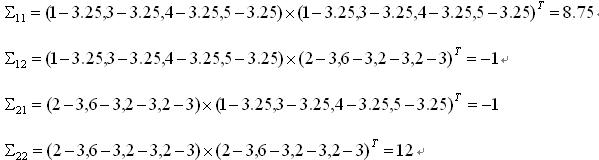
所以,按照定义,给定的4个二维样本的协方差矩阵为:
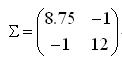
用matlab计算这个例子
z=[1,2;3,6;4,2;5,2]
cov(z)
ans =
2.9167 -0.3333
-0.3333 4.0000
可以看出,matlab计算协方差过程中还将元素统一缩小了3倍。所以,协方差的matlab计算公式为:
协方差(i,j)=(第i列所有元素-第i列均值)*(第j列所有元素-第j列均值)/(样本数-1)
下面在给出一个4维3样本的实例,注意4维样本与符号X,Y就没有关系了,X,Y表示两维的,4维就直接套用计算公式,不用X,Y那么具有迷惑性的表达了。


(3)与matlab计算验证
Z=[1 2 3 4;3 4 1 2;2 3 1 4]
cov(Z)
ans =
1.0000 1.0000 -1.0000 -1.0000
1.0000 1.0000 -1.0000 -1.0000
-1.0000 -1.0000 1.3333 0.6667
-1.0000 -1.0000 0.6667 1.3333
可知该计算方法是正确的。我们还可以看出,协方差矩阵都是方阵,它的维度与样本维度有关(相等)。参考2中还给出了计算协方差矩阵的源代码,非常简洁易懂,在此感谢一下!
参考:
[1] http://en.wikipedia.org/wiki/Covariance_matrix
[2] http://www.cnblogs.com/cvlabs/archive/2010/05/08/1730319.html
---------------------
作者:ybdesire
来源:CSDN
原文:https://blog.csdn.net/ybdesire/article/details/6270328
版权声明:本文为博主原创文章,转载请附上博文链接!
什么是协方差,怎么计算?为什么需要协方差?




# 均值,方差和标准差
学过概率统计的孩子都知道,统计里最基本的概念就是样本的均值,方差,或者再加个标准差。首先我们给你一个含有n个样本的集合,依次给出这些概念的公式描述,这些高中学过数学的孩子都应该知道吧,一带而过。

很显然,均值描述的是样本集合的中间点,它告诉我们的信息是很有限的,而标准差给我们描述的则是样本集合的各个样本点到均值的距离之平均。以这两个集合为例,[0,8,12,20]和[8,9,11,12],两个集合的均值都是10,但显然两个集合差别是很大的,计算两者的标准差,前者是8.3,后者是1.8,显然后者较为集中,故其标准差小一些,标准差描述的就是这种“散布度”。之所以除以n-1而不是除以n,是因为这样能使我们以较小的样本集更好的逼近总体的标准差,即统计上所谓的“无偏估计”。而方差则仅仅是标准差的平方。
# 为什么需要协方差?
上面几个统计量看似已经描述的差不多了,但我们应该注意到,标准差和方差一般是用来描述一维数据的,但现实生活我们常常遇到含有多维数据的数据集,最简单的大家上学时免不了要统计多个学科的考试成绩。面对这样的数据集,我们当然可以按照每一维独立的计算其方差,但是通常我们还想了解更多,比如,一个男孩子的猥琐程度跟他受女孩子欢迎程度是否存在一些联系啊,嘿嘿~协方差就是这样一种用来度量两个随机变量关系的统计量,我们可以仿照方差的定义:

来度量各个维度偏离其均值的程度,标准差可以这么来定义:

协方差的结果有什么意义呢?如果结果为正值,则说明两者是正相关的(从协方差可以引出“相关系数”的定义),也就是说一个人越猥琐就越受女孩子欢迎,嘿嘿,那必须的~结果为负值就说明负相关的,越猥琐女孩子越讨厌,可能吗?如果为0,也是就是统计上说的“相互独立”。
从协方差的定义上我们也可以看出一些显而易见的性质,如:

协方差多了就是协方差矩阵
上一节提到的猥琐和受欢迎的问题是典型二维问题,而协方差也只能处理二维问题,那维数多了自然就需要计算多个协方差,比如n维的数据集就需要计算 n! / ((n-2)!*2) 个协方差,那自然而然的我们会想到使用矩阵来组织这些数据。给出协方差矩阵的定义:

这个定义还是很容易理解的,我们可以举一个简单的三维的例子,假设数据集有三个维度,则协方差矩阵为

可见,协方差矩阵是一个对称的矩阵,而且对角线是各个维度上的方差。
# Matlab协方差实战
上面涉及的内容都比较容易,协方差矩阵似乎也很简单,但实战起来就很容易让人迷茫了。必须要明确一点,协方差矩阵计算的是不同维度之间的协方差,而不是不同样本之间的。这个我将结合下面的例子说明,以下的演示将使用Matlab,为了说明计算原理,不直接调用Matlab的cov函数(蓝色部分为Matlab代码)。
首先,随机产生一个10*3维的整数矩阵作为样本集,10为样本的个数,3为样本的维数。
mysample = fix(rand(10,3)*50)
根据公式,计算协方差需要计算均值,那是按行计算均值还是按列呢,我一开始就老是困扰这个问题。前面我们也特别强调了,协方差矩阵是计算不同维度间的协方差,要时刻牢记这一点。样本矩阵的每行是一个样本,每列为一个维度,所以我们要按列计算均值。为了描述方便,我们先将三个维度的数据分别赋值:
-
>> dim1 = mysample(:,1);
-
>> dim2 = mysample(:,2);
-
>> dim3 = mysample(:,3);
计算dim1与dim2,dim1与dim3,dim2与dim3的协方差:
-
>> sum((dim1 - mean(dim1)) .* (dim2 - mean(dim2))) / (size(mysample, 1) - 1) %得到 -147.0667
-
>> sum((dim1 - mean(dim1)) .* (dim3 - mean(dim3))) / (size(mysample, 1) - 1) %得到 -82.2667
-
>> sum((dim2 - mean(dim2)) .* (dim3 - mean(dim3))) / (size(mysample, 1) - 1) %得到 76.5111
搞清楚了这个后面就容易多了,协方差矩阵的对角线就是各个维度上的方差,下面我们依次计算:
-
>> var(dim1) %得到 227.8778
-
>> var(dim2) %得到 179.8222
-
>> var(dim3) %得到 156.7111
这样,我们就得到了计算协方差矩阵所需要的所有数据,调用Matlab自带的cov函数进行验证:
>> cov(mysample)
把我们计算的数据对号入座,是不是一摸一样?
# Update
今天突然发现,原来协方差矩阵还可以这样计算,先让样本矩阵中心化,即每一维度减去该维度的均值,使每一维度上的均值为0,然后直接用新的到的样本矩阵乘上它的转置,然后除以(N-1)即可。其实这种方法也是由前面的公式推导而来,只不过理解起来不是很直观,但在抽象的公式推导时还是很常用的!同样给出Matlab代码实现:
-
>> temp = mysample - repmat(mean(mysample), 10, 1);
-
>> result = temp' * temp ./ (size(mysample, 1) - 1)

# 总结
理解协方差矩阵的关键就在于牢记它计算的是不同维度之间的协方差,而不是不同样本之间,拿到一个样本矩阵,我们最先要明确的就是一行是一个样本还是一个维度,心中明确这个整个计算过程就会顺流而下,这么一来就不会迷茫了~






 4万+ 13万+
4万+ 13万+