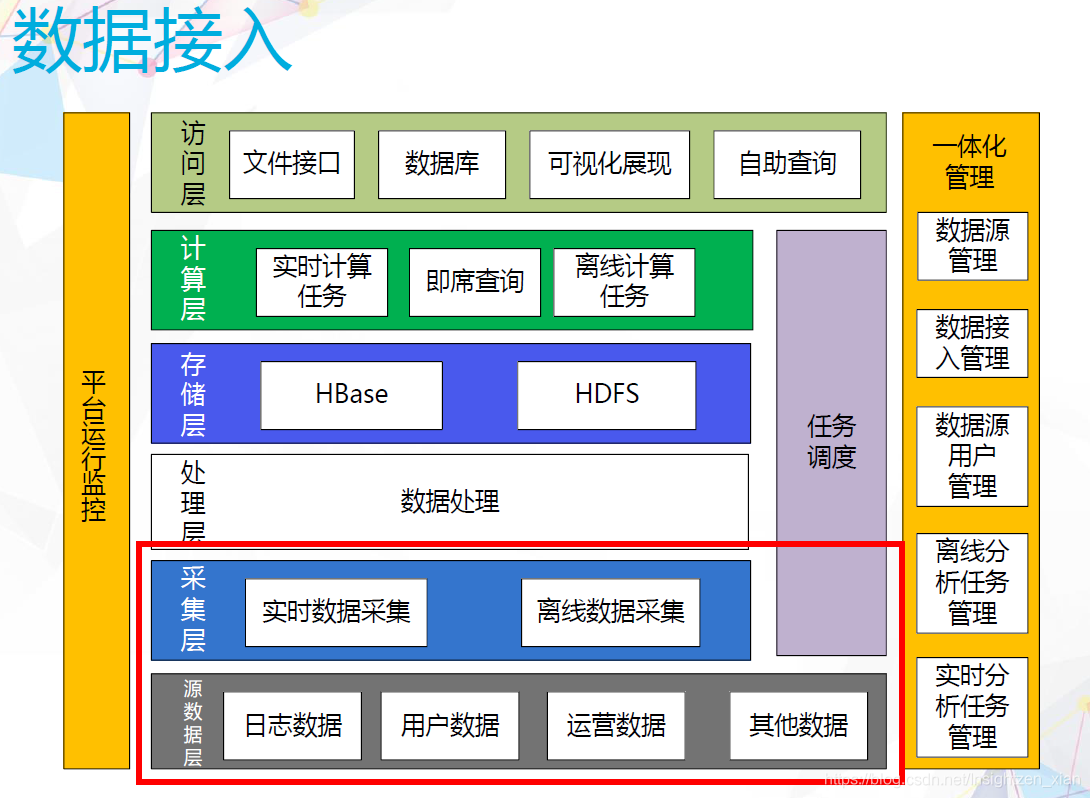
统一数据接入
数据接入就是对于不同的数据来源、不同的合作伙伴,完成数据采集、数据传输、数据处理、数据缓存到行业统一的数据平台的过程。
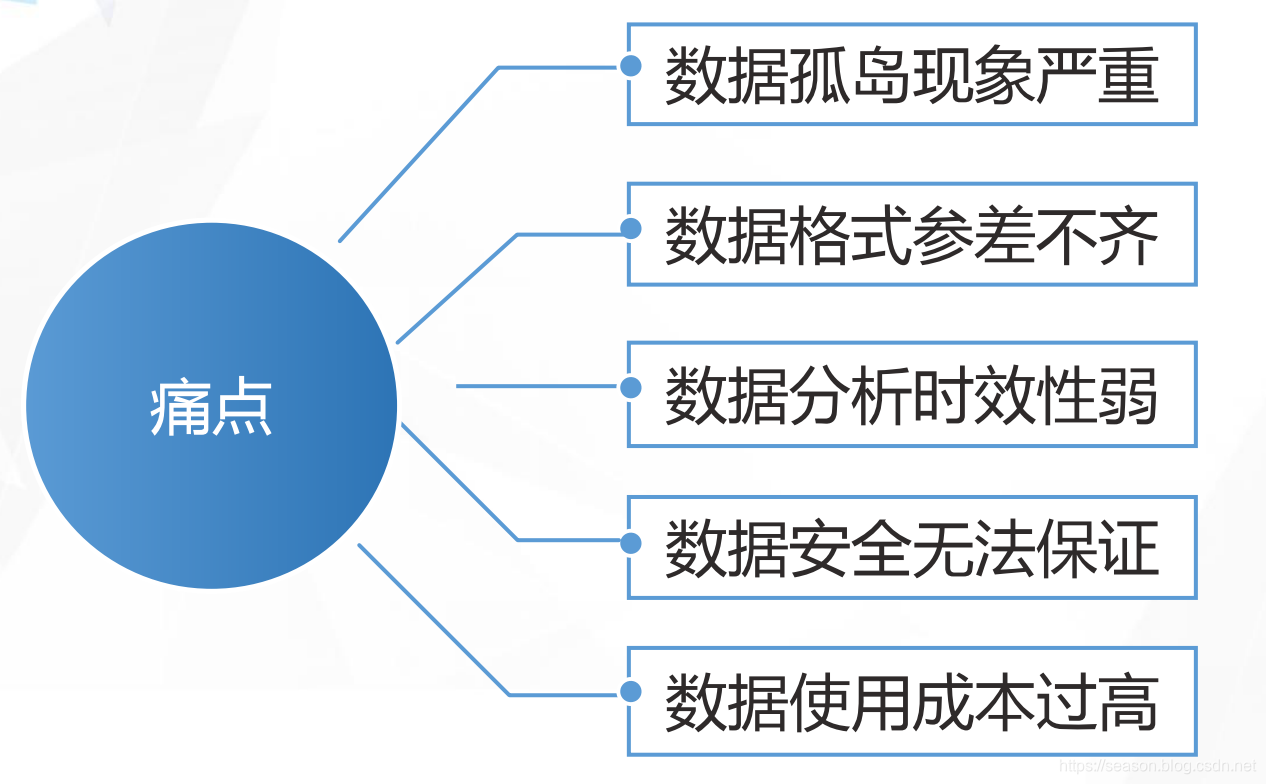
大数据接入处理面临的问题

数据接入的三个阶段
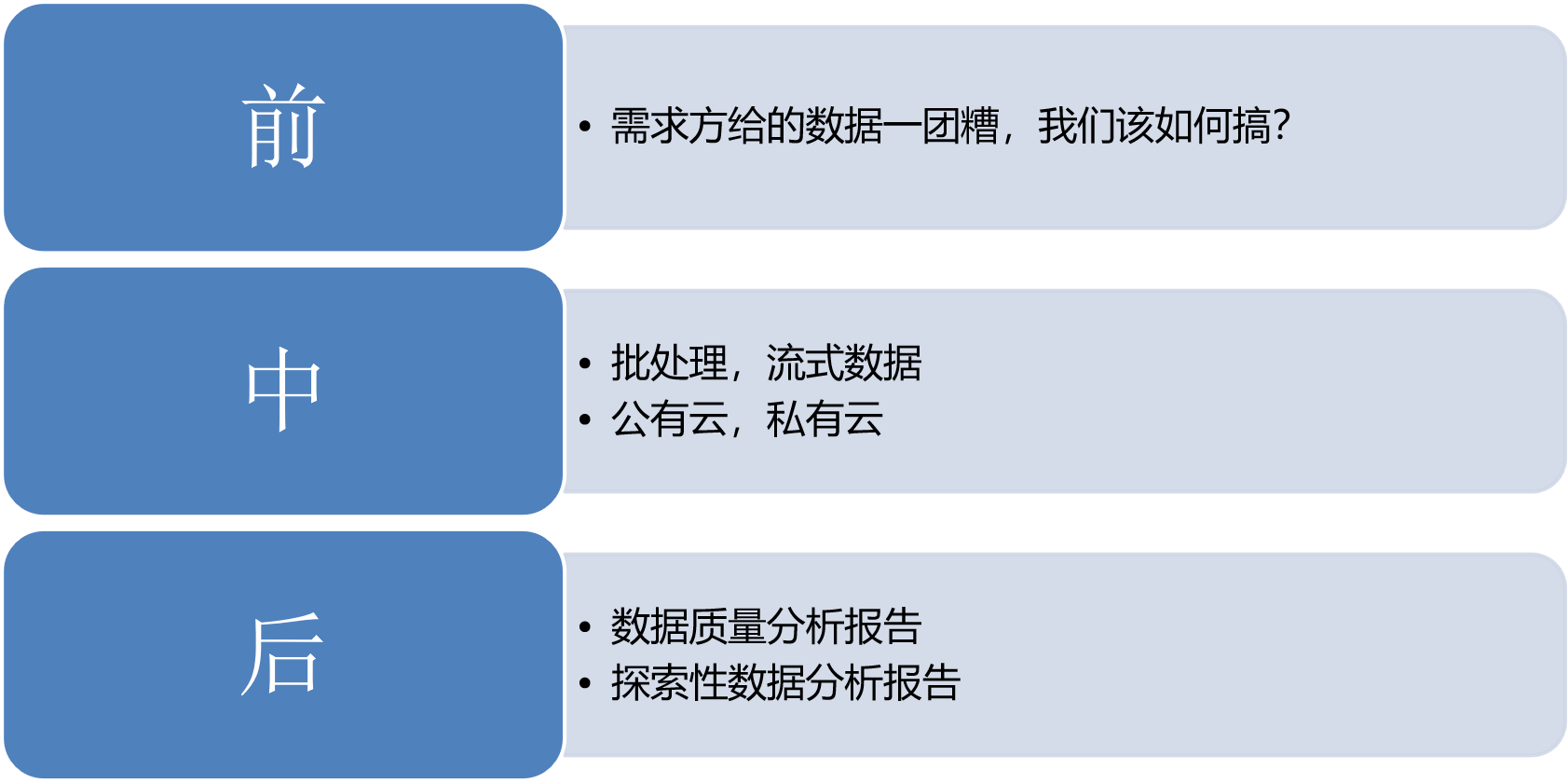
前
0.非结构化数据----(word,excel,图片,pdf,扫描件,视频)
1.文本文件----(txt,csv)----utf-8
(踩过的坑-gbk编码和数据中换行符触发spark2.2 加载文件的bug(multiline 和gbk 不能共同作用))
2.数据库(full dump,请求接口)
3.去ioe,集群迁徙
数据格式,字段,内容要求:
非结构化数据
0. 标签,背景模板,文档说明
结构化数据
数据字典,ER图,数据流图,系统截图,新人入职培训说明
1.所有文本文件要求编码格式utf8,csv 要求双引号包裹(字段中不要有回车换行)
2.数据库full dump 给出导出脚本及日志(yiyong数据的坑----没有导出脚本,看着报错一步步推断)
3.请求接口给出请求文档,及支持的最大并发数等指标
中
针对不同的数据来源,确定数据最终存储的格式,地点
后
1.数据质量核查
2.描述性统计分析
接入技术分析

批处理
优点:数据覆盖面广,时间跨度长,支撑业务范围广 ,计算准确度高;依靠历史数据预先计算相关数据模型
缺点:数据实效性不足 存储空间、存储类型需求大
流式
优点:高效查询、快速响应、“热数据”价值高效利用
缺点:上下文关联密切场景业务支撑不足
1.数据接入手段
1)socket方式
c/s交互模式,传输协议采用tcp/udp
优点:1.易于编程,java提供了多种框架,屏蔽了底层通信细节以及数据传输转换细节。2.容易控制权限。通过传输层协议https,加密传输的数据,使得安全性提高
3.通用性比较强,无论客户端是.net架构,java,python 都是可以的。尤其是webservice规范,使得服务变得通用
缺点:1.服务器和客户端必须同时工作,当服务器端不可用的时候,整个数据交互是不可进行。2 当传输数据量比较大的时候,严重占用网络带宽,可能导致连接超时。使得在数据量交互的时候,服务变的很不可靠
2)ftp/文件共享服务器方式
适合大数据量的交互,约定文件格式、命名规则。批量处理数据
优点:
在数据量大的情况下,可以通过文件传输,不会超时,不占用网络带宽
方案简单,易操作
缺点:
实时性不强
必须约定文件数据的格式,当改变文件格式的时候,需要各个系统都同步做修改
3)message形式
Java消息服务(Java Message Service)是message数据传输的典型的实现方式。
系统A和系统B通过一个消息服务器进行数据交换。系统A发送消息到消息服务器,如果系统B订阅系统A发送过来的消息,消息服务器会消息推送给B。双方约定消息格式即可。目前市场上有很多开源的jms消息中间件,比如 使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ等
优点:
1 由于jms定义了规范,有很多的开源的消息中间件可以选择,而且比较通用。接入起来相对也比较简单
2 通过消息方式比较灵活,可以采取同步,异步,可靠性的消息处理,消息中间件也可以独立出来部署。
缺点:
1.学习jms相关的基础知识,消息中间件的具体配置,以及实现的细节对于开发人员来说还是有一点学习成本的
2 在大数据量的情况下,消息可能会产生积压,导致消息延迟,消息丢失,甚至消息中间件崩溃。
Flume+kafka
Flume作为日志收集工具,监控一个文件目录或者一个文件,当有新数据加入时,收集新数据发送给Kafka。Kafka用来做数据缓存和消息订阅。Kafka里面的消息可以定时落地到HDFS上,也可以用Spark Streaming来做实时处理,然后将处理后的数据落地到HDFS上。
Flume采集数据都是按行分割的,一行代表一条记录。如果原始数据不符合要求,需要对数据进行预处理。
数据库文件
1.Imp/exp方式使用dmp文件直接导入目标库
2.sqoop 关系型数据库与hadoop生态系统(hive,hdfs)进行数据转移
ETL(Extract-Transform-Load )工具:构建数据仓库
用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中去
Apache Camel、Apache Kafka、Apatar、Heka、Logstash、Scriptella、Talend、Kettle
2.接入技术选择
1.ETL工具
(Extract-Transform-Load )
2.定制研发
参考文献
《数据平台的实践及思考》 杨剑飞