一、Linux & Shell
1.1 常用命令
top、ps -ef 、netstat、df -h 、tail、cat
1.2 查看端口号:netstat -nlpt / ss
查看进程:ps -ef
查看磁盘:df -h / du
查看内存:top free -h
查看cpu:top
查看io情况:iotop iostat
1.3 awk cut sort send
1.4 单引号和双引号的区别
单引号不去变量值,双引号取变量值
'$do_date' $do_date
"$do_date" 2021-08-11
'"$do_date"' "$do_date"
"'$do_date'" '2021-08-11'
1.5 写过哪些脚本?
1)集群启动脚本
#!/bin/bash case $1 in "start"){ for i in hadoop1 hadoop2 hadoop3 do ssh $i 启动命令(使用绝对路径) done };; "stop"){ for i in hadoop1 hadoop2 hadoop3 do ssh $i 停止命令(使用绝对路径) done };; esac
2)离线数仓、分层脚本
#!/bin/bash 定义一些变量:APP库名、do_date:今天 - 1 sql="先写出一天的逻辑,若有时间,替换为变量do_date,遇到表名,前面加$APP,用到自定义函数,前面加APP" 如果是ods层,创建lzo索引 hive -e $sql
3)sqoop同步脚本
1.6 停止脚本,忘记进程号
ps -ef | grep 脚本名称 | grep -v grep | awk '{print $2}' | xargs kill
或者
pgrep -f 脚本名称 | xargs kill
二、Hadoop
2.1 入门
1)常用端口号
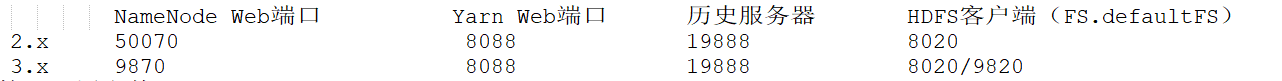
2)核心配置文件
2.x core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、slaves
3.x core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、workers
2.2 HDFS
1)读流程
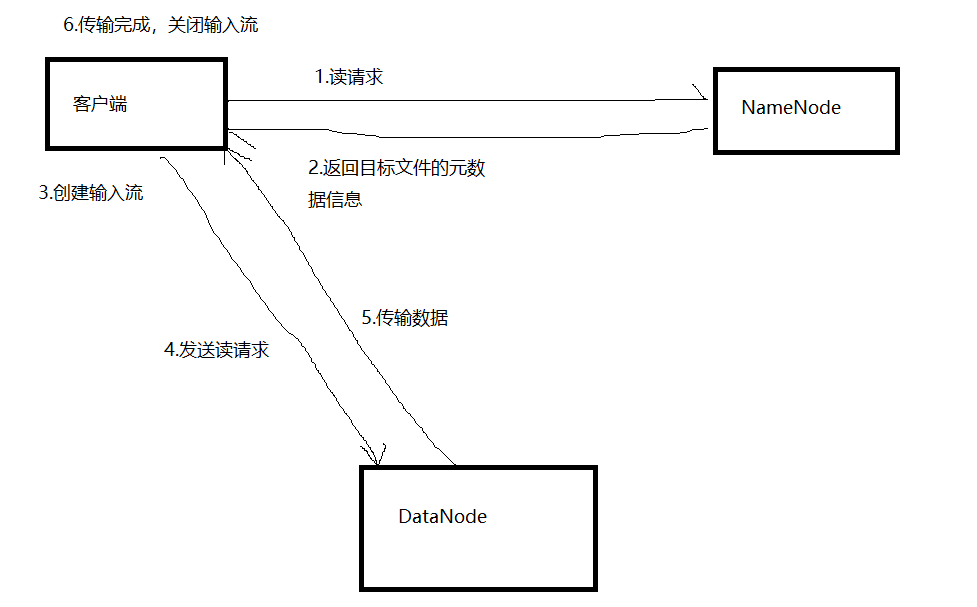
2)写请求
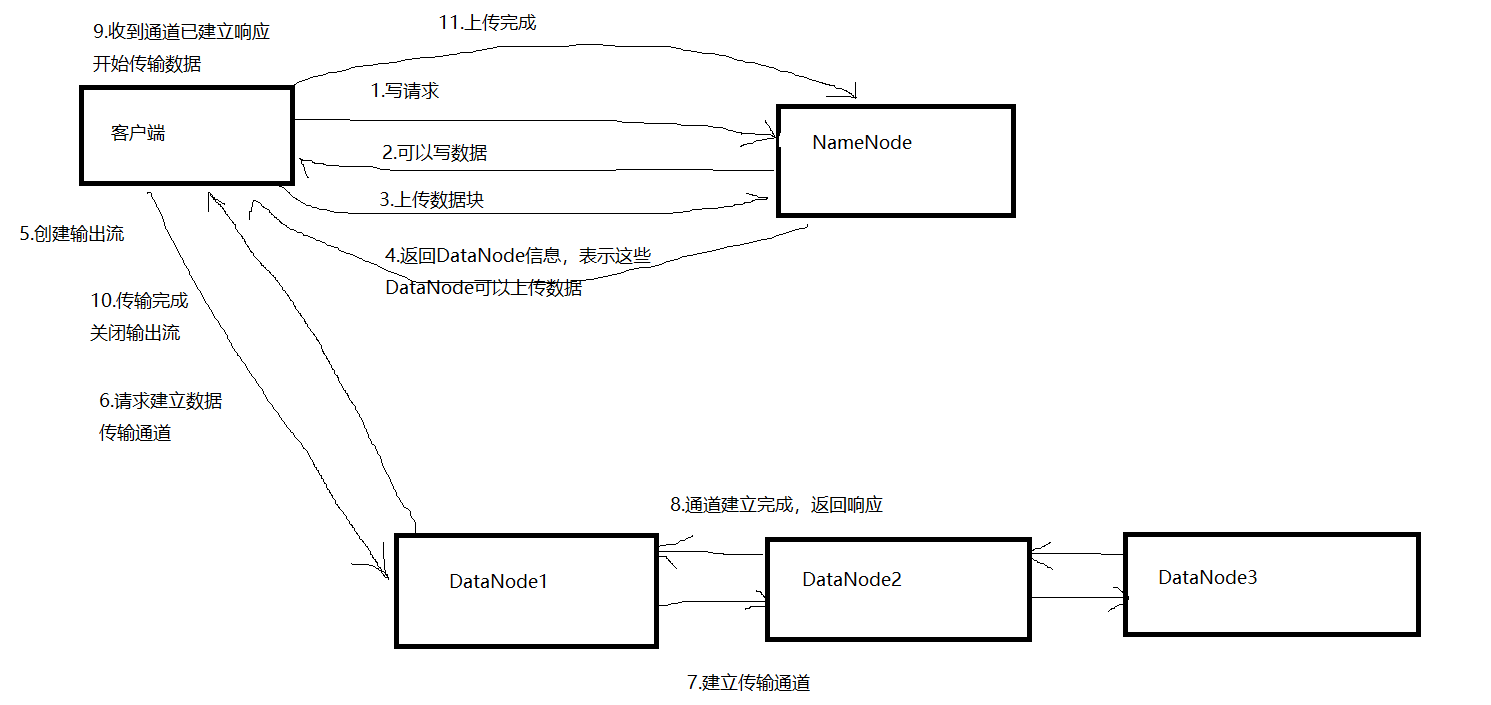
3)块大小
1.x:64M
2.x:128M
3.x:128M
Hive:256,使用CombineHiveInputFormat设定
企业怎么选?
如果是大厂,256M
一般企业,128M
4)NameNode,并发、内存
线程数:20 * log e N
内存:
2.x:默认 2000M
3.x:动态分配
5)小文件
危害:占用NameNode内存,一个文件150字节
影响MapTask的数量
解决:har归档、使用CombineTextInputFormat来进行切片、JVM重用,设置为10
6)异构存储
7)纠删码
计算换空间
8)集群扩容、减少节点
加节点:新的节点配置好,白名单
减节点:黑名单
2.3 MR
shuffle过程及优化

整体优化:
(1)NodeManager默认内存8G,需要根据服务器实际配置灵活调整,例如128G内存,配置为100G左右,yarn.nodemanager.resource.memory-mb
(2)单任务默认内存8G,需要根据该任务的数据量灵活调整,例如128m数据,配置1G内存,yarn-scheduler.maximum-allocation-mb
(3)控制分配给MapTask的内存上限,默认内存大小为1G,若数据量是128m,正常不需要调整内存,若数据量大于128m,可以增加至4~5G
(4)控制分配给ReduceTask的内存上限,默认内存大小为1G,若数据量是128m,正常不需要调整内存,若数据量大于128m,可以增加ReduceTask内存大小为4~5G
(5)控制MapTask堆内存大小
(6)控制ReduceTask堆内存大小
(7)增加MapTask和ReduceTask的CPU核数
(8)增加每个Container的CPU核数和内存大小
(9)在hdfs-site.xml中配置多磁盘
(10)设置NameNode的工作线程池数量,若集群规模为8台,此参数设置为41,该值可以通过python命令计算出来
2.4 Yarn
1)工作机制
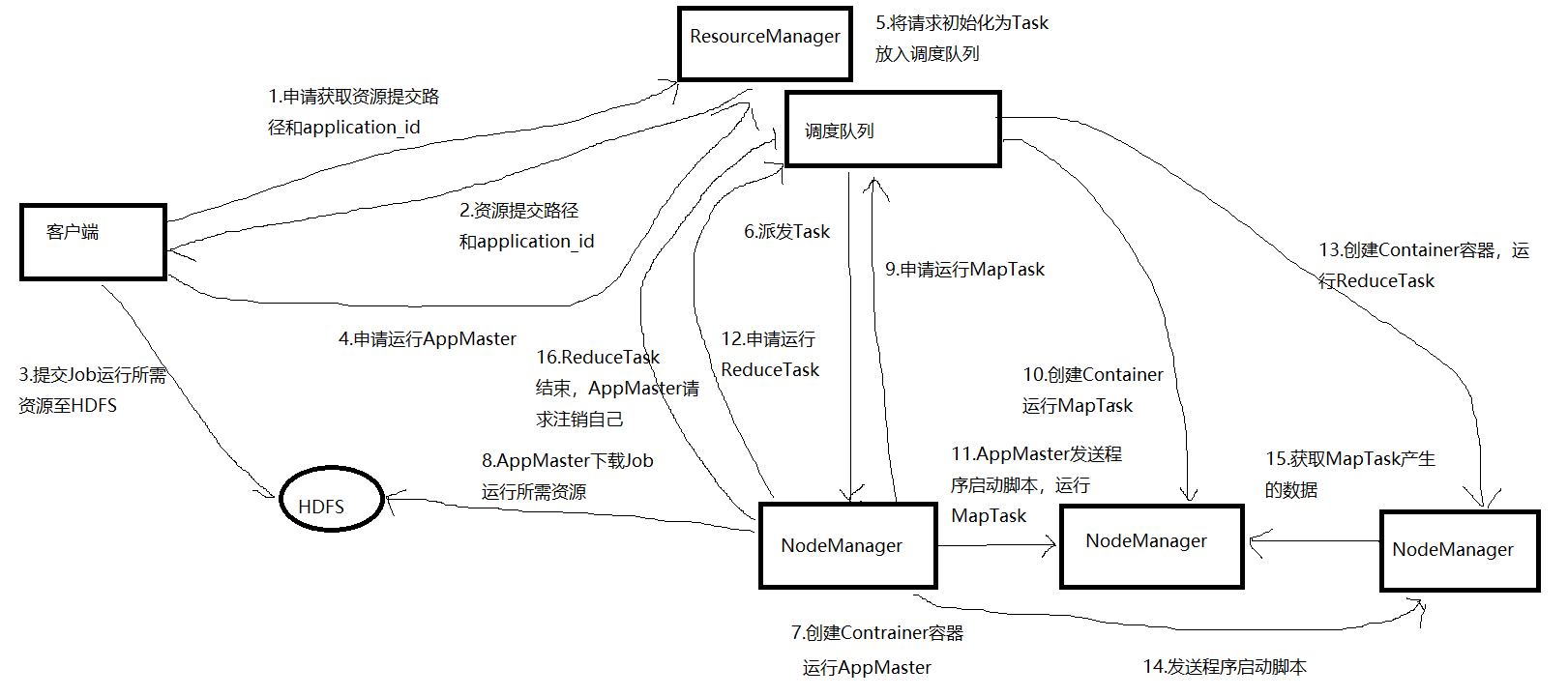
2)调度器:
FIFO:单队列,先进先出,先提交的先执行,资源足够,后面任务也执行
容量(apache默认):多队列,每个都是FIFO,队列之间可以借用资源
公平(CDH默认):多队列,公平享有资源,队列之间也可以借用资源
企业怎么选?
大厂选公平
一般选容量
为什么要多队列?
单队列,一个出问题,其他可能受影响
多队列如何设置?
按照业务分:下单、支付、登录、购物、收藏
好处是可以实现业务降级,让重要的业务优先获得资源执行
三、Zookeeper
3.1 选举机制
半数机制:超过一半存活,集群才可用
脑裂问题:基于半数机制,可以避免脑裂问题
3.2 常用命令
ls、get、deleteall、delete、create
3.3 适用场景
1)高可用的协调者
2)动态配置中心
3)Clickhouse的副本表
4)组件的依赖:kafka、hbase
3.4 集群规模:奇数台
10台服务器:3个
20台服务器:5个
50台服务器:7个
100台服务器:9个
200台服务器:11个
节点不是越多越好:越多,花费更多的时间在同步、通信上
3.5 Paxos算法
Paxos算法解决的是一个分布式系统如何就某个值(决议)达成一致。一个典型的场景是,在一个分布式数据库系统中,如果各个节点的初始状态一致,每个节点执行相同的操作序列,那么他们最后能够得到一个一致的状态。为了保证每个节点执行相同的命令序列,需要在每一条指令上执行一个“一致性算法”以保证每个节点看到的指令一致。zookeeper使用的zab算法是该算法的一个实现。在Paxos算法中,有三种角色:Proposer (提议者),Acceptor(接受者),Learners(记录员)
Proposer提议者:只要Proposer(提议者)发的提案被半数以上的Acceptor(接受者)接受,Proposer(提议者)就认为该提案例的value被选定了。
Acceptor接受者:只要Acceptor(接受者)接受了某个提案,Acceptor(接受者)就认为该提案例的value被选定了
Learner记录员:Acceptor(接收者)告诉Learner(记录员)哪个value是提议者的提案被选定的,Learner(记录员)就认为该value被选定。
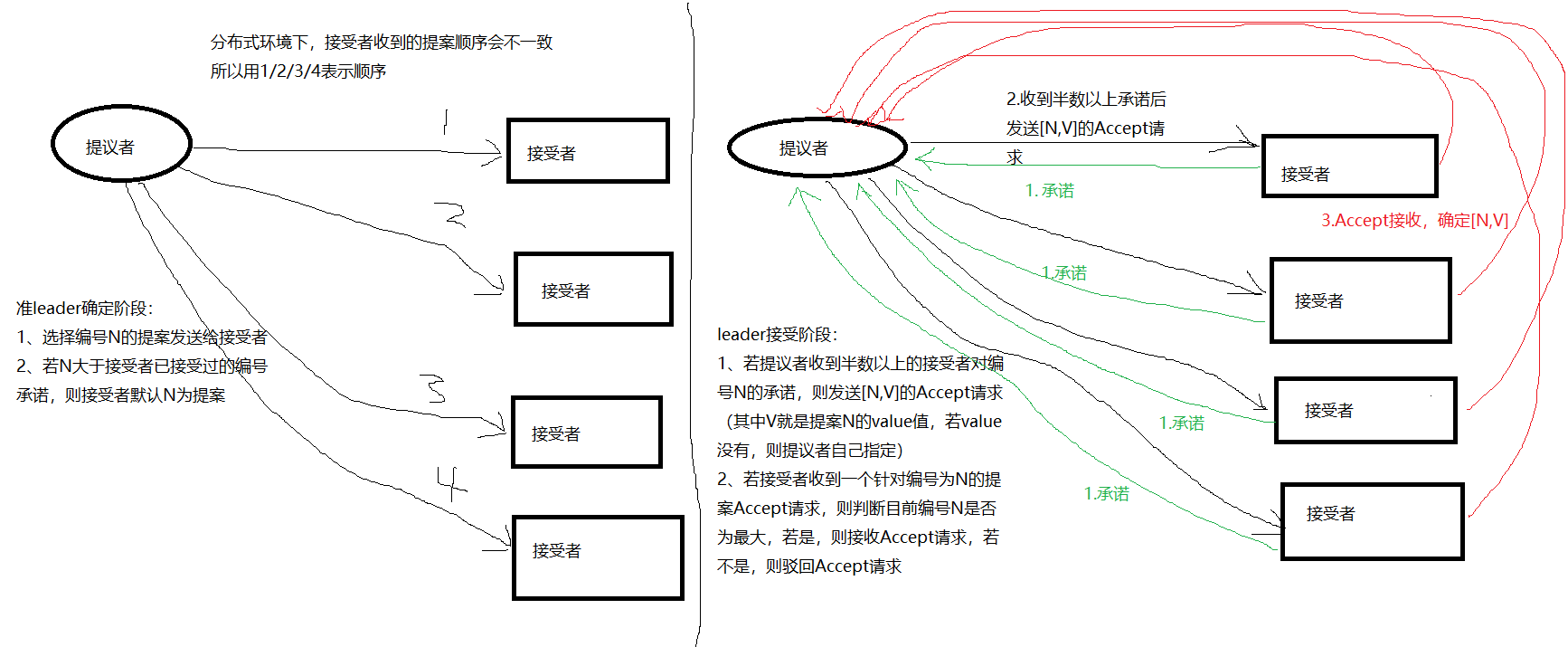
Paxos算法分为两个阶段,具体如下:
阶段一 (准leader 确定 ):
(a) Proposer (提议者)选择一个提案编号 N,然后向半数以上的Acceptor (接受者)发送编号为 N 的 Prepare(准备) 请求。
(b) 如果一个 Acceptor(接受者) 收到一个编号为 N 的 Prepare(准备) 请求,且 N 大于该 Acceptor (接受者)已经响应过的所有 Prepare (准备)请求的编号,那么它就会将它已经接受过的编号最大的提案(如果有的话)作为响 应反馈给 Proposer(提议者),同时该Acceptor (接受者)承诺不再接受任何编号小于 N 的提案。
阶段二 (leader 确认):
(a) 如果 Proposer (提议者)收到半数以上 Acceptor(接受者) 对其发出的编号为 N 的 Prepare(准备) 请求的响应,那么它就会发送一个针对[N,V]提案的 Accept (接受)请求给半数以上的 Acceptor(接受者)。注意:V 就是收到的响应中编号最大的提案的 value ,如果响应中不包含任何提案,那么V 就由 Proposer(提议者) 自己决定。
(b) 如果 Acceptor(接受者) 收到一个针对编号为 N 的提案的 Accept(接受) 请求,只要该 Acceptor (接受者)没有对编号大于 N 的 Prepare 请求做出过响应,它就接受该提案。
3.6 CAP原则
C:强一致性
A:高可用性
P:分区容错性
四、Flume
4.1 组成
1)taildir source
支持断电续传、多目录
哪个版本产生? apache 1.7
原理:读取完数据,将offset保存到磁盘的文件中
如果flume挂了,可能产生少量重复,怎么办?
不处理:考虑效率,下游再处理(清洗去重、开窗取第一条)
处理:自定义事务(不推荐)
支不支持子文件夹的递归?不支持,需要自定义;还有就是我们使用的时候很规范,不会出现子文件
2)channel
memory channel:基于内存,效率高,可靠性低,默认100个Event
file channel:基于磁盘,效率低,可靠性高,默认100万个Event
kafka channel:基于kafka磁盘,效率高、可靠性高,省略了sink阶段,效率 > memory channel + kafka sink
哪个版本产生?apache 1.6
为什么没火?有bug
哪个版本火的?apache 1.7,解决了bug
企业怎么选?
若对接kafka,优先选择kafka channel
若对接的不是kafka:
若是金融公司或对数字敏感的,可以考虑可靠性高的file channel
若是一般企业,普通日志,考虑速度快的memory channel
3)hdfs sink
小文件问题:
滚动大小:128M(块大小)
滚动时间:1小时
event数量:0,表示禁用,每个event大小不一
4)事务
source 到 channel是put事务
channel 到 sink是take事务
4.2 三个器
1)拦截器
ETL拦截器:轻度清洗,过滤掉Json格式不完整的数据
能不能不用?可以不用,下游再清洗
时间连接器:提取日志时间,作为分区的依据,避免零点漂移问题
定义步骤:
定义一个类,实现Interceptor接口,重写4个方法
初始化
单Event、多Event
close
定义静态内部类,继承Interceptor.Builder
打Jar包,上传至flume/bin,然后在配置文件中指定,全类型$Builder
2)Channel 选择器
复制(默认):event发往所有的channel,项目里用默认
多路复用:event有选择性的发往对应的channel
3)监控器
ganglia:尝试提交的次数远远大于成功提交的次数,说明发生了大量的失败、重试,程序有问题
4.3 挂了怎么办
1)处理方式:尝试重启、看日志定位问题
2)分析影响范围:
数据丢:如果是memory channel,可能最多会丢100个event
数据重:如果是taildir source,可能产生少量重复
保障:日志服务器有30天的备份
4.4 优化
1)内存:在flume-env.sh修改,默认2000M-->调整为4~6G
2)台数:活动时,提前增加服务器
怎么增加?首先让新服务器与Kafka、HDFS接通,数据能正常流通,然后再打开Nginx的配置文件,添加转发的新服务器地址与端口即可
3)hdfs sink 小文件问题
滚动大小:128M(块大小)
滚动时间:1小时
event数量:0,表示禁用,每个event大小不一
4)file channel配置多磁盘多目录
五、Kafka
5.1 基本信息
1)组成:生产者、消费者、Broker、Zookeeper
2)副本:默认1个 -->2个
3)压测:使用官方提供的脚本,测出生产者峰值速率和消费者峰值速率
4)台数 = 2 * (生产者峰值生产速率 * 副本数 / 100)+ 1,我们公司是 2 * (50 * 2 / 100)+ 1 = 3台
5)分区数:
期望的吞吐率是 Tt = 100M/s,创建一个单分区的主题,进行压测,求出生产者单分区生产峰值Tp和消费者单分区消费峰值Tc
分区数 = Tt / min(Tp,Tc),我们公司是 100 / min(50,20) = 5个分区
6)保存时间:默认7天 --> 3天
7)消费者消费策略:
Range(默认):尽量的均分,可能产生数据倾斜(同时订阅多个Topic时)
假设主题有10个分区,三个消费者
C0 0,1,2,3
C1 4,5,6
C2 7,8,9
RoundBobin(轮询):以分区为单位,取Hash,取模(如果同时订阅多个Topic,每个消费者订阅的Topic要一致)
Sticky: 粘性的, 发生rebalance之后,尽量复用之前的分配关系
8)ISR:主要的作用就是Leader挂了之后,谁来当老大的问题
老版本:延迟时间、延迟条数
新版本:延迟时间
hw高水位机制、leo(log-end-offset)
9)监控
kafka eagle
10)几个Topic
离线数仓:采集日志数据时用到一个Topic
实时数仓:ods(日志、业务各一个)+ dwd(14个) + dwm(4个)+ dws(1个)= 18个左右
11)数据量多少?
60万日活,每条日志 0.5~2k,取均值1k,每人每天平均产生100条数据
一天的条数、数据量:
60万 * 100条 = 6千万条
6千万条 * 1k = 60000000k = 60000M = 60G
平均条数、速率:
条数 = 6千万条 / (24 * 60 * 60) ≈ 700多条
速率 = 700 * 1k ≈ 0.7 M/s(不到1M/s)
高峰条数、速率:
时间段:晚上8点到12点
均值的 2~20倍
条数 = 700 * (2~20) = 1400条/s ~ 14000条/s ≈ 1万多条/s
速率 = (1400条/s ~ 14000条/s) * 1k = 1.4M/s ~ 14M/s ≈ 10M/s左右
低谷条数、速率:
时间段:凌晨2点到5点
均值的 20分之一
条数 = 700 / 20 = 40条/s左右
速率 = 1400条/s * 1k ≈ 40k/s左右
12)磁盘空间
一天60G
60G * 保存3天 * 2个副本 / 0.7预留一些空间 ≈ 500多G,我们公司设置为1个T,多了一倍,完全够用
5.2 积压
提高消费能力
1)保证分区数 : 消费者线程数 = 1 : 1
默认1个分区 对应 一个 CPU核数
提高至 5个分区 : 5个CPU
2)提高单批次处理能力
flume:默认一个批次处理1000条数据 --> 3000条
flink:保证处理效率,不要产生反压
spark:限流参数调大
5.3 丢数
生产者:ack
0 发送完数据就不管了,效率高,可靠性低
1 发送完需要leader应答,效率中等,可靠性中等
-1 发送完需要leader和ISR中的所有follower应答,效率低,可靠性高
-1的情况有没有丢失数据?有,当ISR队列中只有leader时,这种情况相当于ack = 1,可以修改min.insync.replicas(默认1)--> 改为2
企业怎么选?
如果是金融公司,对数字敏感,主要考虑可靠性,选 -1
如果是一般企业,普通日志,主要考虑效率和可靠性,选1
Broker:Kafka接收到数据,先保存在页缓存中,之后再刷写到磁盘,如果页缓存中的数据丢失,此时也会丢数据
5.4 重复
因为重试发生重复,之前是1,2,3 --> 结果1,1,2,2,3
解决:事务 + 幂等性 + ack设置为-1
企业怎么选?
如果是金融公司,对数字敏感,主要考虑可靠性,选事务 + 幂等性 + ack设置为-1
如果是一般公司,普通日志,主要考虑可靠性和效率,选 ack设置为1
5.5 挂了
1)处理方式:尝试重启,看日志定位问题
2)影响范围:
丢:ack设置为1,当leader收到消息,未来得及同步就挂了,可能丢
重:可能重,没有事务,ack也不是-1
保障:日志服务器有30天备份,flume channel有缓存(kafka channel没有)
5.6 优化
1)内存:默认1G --> 6G
2)压缩
3)当网络延迟比较大时,提高通行时长
4)副本数:默认1个 --> 2个
5)保存时间:默认7天 --> 3天
5.7 为什么能高效读写?
1)分布式集群
2)顺序写磁盘,据官方介绍,顺序写 600M/s,随机写100k/s,因为顺序写磁盘省去了磁头的寻址时间
3)零拷贝
5.8 消费Kafka的数据有序性?
单分区内有序,多分区间无序
为什么讲究有序?
业务库表的数据,insert、update、delete,同一张表中的数据是有序的
解决:
1)单分区
2)让同一张表中的数据进入同一个分区
生产者API可以指定key,key取hash,对分区取模
key = 库名 + 表名