第 1 章 HQL 是如何转换为 MR 任务的
1.1 Hive 的核心组成介绍
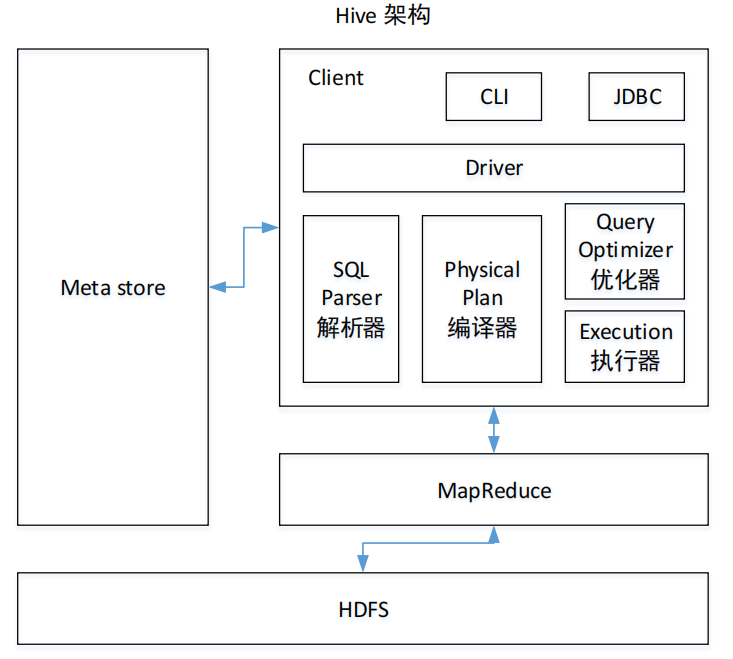
1)用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc 访问 hive)、WEBUI(浏览器访问 hive)
2)元数据:Metastore
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;默认存储在自带的 derby 数据库中,推荐使用 MySQL 存储 Metastore
3)Hadoop
使用 HDFS 进行存储,使用 MapReduce 进行计算。
4)驱动器:Driver
5)解析器(SQL Parser)
将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL 语义是否有误。
6)编译器(Physical Plan)
将 AST 编译生成逻辑执行计划。
7)优化器(Query Optimizer)
对逻辑执行计划进行优化。
8)执行器(Execution)
把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来说,就是 MR/Spark。
1.2 HQL 转换为 MR 任务流程说明
HQL编译为MR任务流程介绍:
1)进入程序,利用Antlr框架定义HQL的语法规则,对HQL完成词法语法解析,将HQL转换为为AST(抽象语法树);
2)遍历AST,抽象出查询的基本组成单元QueryBlock(查询块),可以理解为最小的查询执行单元;
3)遍历QueryBlock,将其转换为OperatorTree(操作树,也就是逻辑执行计划),可以理解为不可拆分的一个逻辑执行单元;
4)使用逻辑优化器对OperatorTree(操作树)进行逻辑优化。例如合并不必要的ReduceSinkOperator,减少Shuffle数据量;
5)遍历OperatorTree,转换为TaskTree。也就是翻译为MR任务的流程,将逻辑执行计划转换为物理执行计划;
6)使用物理优化器对TaskTree进行物理优化;
7)生成最终的执行计划,提交任务到Hadoop集群运行。
第 2 章 HQL 转换为 MR 源码详细解读
2.1 HQL 转换为 MR 源码整体流程介绍
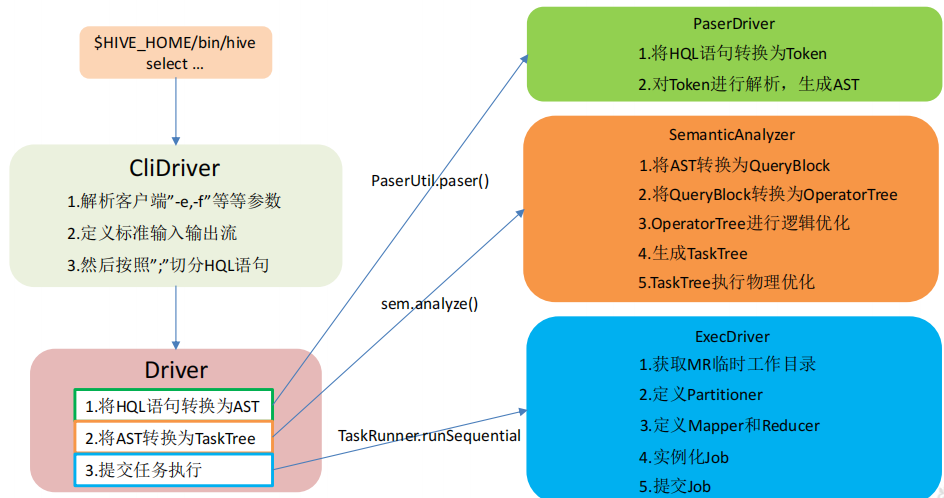
2.2 程序入口 — CliDriver
众所周知,我们执行一个 HQL 语句通常有以下几种方式:
1)$HIVE_HOME/bin/hive 进入客户端,然后执行 HQL;
2)$HIVE_HOME/bin/hive -e “hql”;
3)$HIVE_HOME/bin/hive -f hive.sql;
4)先开启 hivesever2 服务端,然后通过 JDBC 方式连接远程提交 HQL。
可 以 知 道 我 们 执 行 HQL,主 要 依 赖 于 $HIVE_HOME/bin/hive 和 $HIVE_HOME/bin/。hivesever2 两种脚本来实现提交HQL,而在这两个脚本中,最终启动的 JAVA 程序的主类为“org.apache.hadoop.hive.cli.CliDriver”,所以其实 Hive 程序的入口就是“CliDriver”这个类。
2.3 HQL 的读取与参数解析
2.3.1 找到“CliDriver”这个类的“main”方法
public static void main(String[] args) throws Exception { int ret = new CliDriver().run(args); System.exit(ret); }
2.3.2 主类的 run 方法
//进入run方法 public int run(String[] args) throws Exception { //解析系统参数 OptionsProcessor oproc = new OptionsProcessor(); if (!oproc.process_stage1(args)) { return 1; } //在加载核心配置单元类之前,重新初始化log4j boolean logInitFailed = false; String logInitDetailMessage; try { logInitDetailMessage = LogUtils.initHiveLog4j(); } catch (LogInitializationException e) { logInitFailed = true; logInitDetailMessage = e.getMessage(); } //标准输入输出以及错误输出流的定义,后续需要输入 HQL 以及打印控制台信息 CliSessionState ss = new CliSessionState(new HiveConf(SessionState.class)); ss.in = System.in; try { ss.out = new PrintStream(System.out, true, "UTF-8"); ss.info = new PrintStream(System.err, true, "UTF-8"); ss.err = new CachingPrintStream(System.err, true, "UTF-8"); } catch (UnsupportedEncodingException e) { return 3; } //解析用户参数 if (!oproc.process_stage2(ss)) { return 2; } ...//对参数进行封装 HiveConf conf = ss.getConf(); for (Map.Entry<Object, Object> item : ss.cmdProperties.entrySet()) { conf.set((String) item.getKey(), (String) item.getValue()); ss.getOverriddenConfigurations().put((String) item.getKey(), (String) item.getValue()); }
...
//更新线程名 ss.updateThreadName(); // Create views registry HiveMaterializedViewsRegistry.get().init(); // execute cli driver work try { return executeDriver(ss, conf, oproc); } finally { ss.resetThreadName(); ss.close(); } }
2.3.3 executeDriver 方法
/** * Execute the cli work * @param ss CliSessionState of the CLI driver * @param conf HiveConf for the driver session * @param oproc Operation processor of the CLI invocation * @return status of the CLI command execution * @throws Exception */ private int executeDriver(CliSessionState ss, HiveConf conf, OptionsProcessor oproc) throws Exception { CliDriver cli = new CliDriver(); cli.setHiveVariables(oproc.getHiveVariables()); ... //判断是否是mr程序,有的话在控制台打印警告 if ("mr".equals(HiveConf.getVar(conf, ConfVars.HIVE_EXECUTION_ENGINE))) { console.printInfo(HiveConf.generateMrDeprecationWarning()); } //初始化控制台阅读器 setupConsoleReader(); String line; int ret = 0; //0代表程序会正常退出 String prefix = ""; String curDB = getFormattedDb(conf, ss); String curPrompt = prompt + curDB; String dbSpaces = spacesForString(curDB); while ((line = reader.readLine(curPrompt + "> ")) != null) { //循环读取客户端的输入 HQL if (!prefix.equals("")) { //判断是否是空串 prefix += ' '; } if (line.trim().startsWith("--")) { //判断是否有注释 continue; } if (line.trim().endsWith(";") && !line.trim().endsWith("\;")) { //判断是否以分号结尾 line = prefix + line; ret = cli.processLine(line, true); //解析带分号的语句 prefix = ""; curDB = getFormattedDb(conf, ss); curPrompt = prompt + curDB; dbSpaces = dbSpaces.length() == curDB.length() ? dbSpaces : spacesForString(curDB); } else { prefix = prefix + line; curPrompt = prompt2 + dbSpaces; continue; } } return ret; }
2.3.4 processLine 方法
/** * Processes a line of semicolon separated commands * * @param line * The commands to process * @param allowInterrupting * When true the function will handle SIG_INT (Ctrl+C) by interrupting the processing and * returning -1 * @return 0 if ok */ public int processLine(String line, boolean allowInterrupting) { SignalHandler oldSignal = null; Signal interruptSignal = null; //判断输入是否是Ctrl+C,若是,则退出客户端 if (allowInterrupting) { // Remember all threads that were running at the time we started line processing. // Hook up the custom Ctrl+C handler while processing this line interruptSignal = new Signal("INT"); oldSignal = Signal.handle(interruptSignal, new SignalHandler() { private boolean interruptRequested; @Override public void handle(Signal signal) { boolean initialRequest = !interruptRequested; interruptRequested = true; // Kill the VM on second ctrl+c if (!initialRequest) { console.printInfo("Exiting the JVM"); System.exit(127); } // Interrupt the CLI thread to stop the current statement and return // to prompt console.printInfo("Interrupting... Be patient, this might take some time."); console.printInfo("Press Ctrl+C again to kill JVM"); // First, kill any running MR jobs HadoopJobExecHelper.killRunningJobs(); TezJobExecHelper.killRunningJobs(); HiveInterruptUtils.interrupt(); } }); } try { int lastRet = 0, ret = 0; // we can not use "split" function directly as ";" may be quoted List<String> commands = splitSemiColon(line); //按分号切分命令 String command = ""; for (String oneCmd : commands) { if (StringUtils.endsWith(oneCmd, "\")) { //若是分号,继续读取 command += StringUtils.chop(oneCmd) + ";"; continue; } else { command += oneCmd; } if (StringUtils.isBlank(command)) { //若是空行,继续读取 continue; } ret = processCmd(command); //解析命令,解析单行HQL ... } return lastRet; } finally { ... } }
2.3.5 processCmd 方法
public int processCmd(String cmd) { CliSessionState ss = (CliSessionState) SessionState.get(); ss.setLastCommand(cmd); ss.updateThreadName(); ... if (cmd_trimmed.toLowerCase().equals("quit") || cmd_trimmed.toLowerCase().equals("exit")) { //判断命令是否有quit或exit,若有则退出客户端 ... } else if (tokens[0].equalsIgnoreCase("source")) { //若开头是source,执行HQL文件 ... } else if (cmd_trimmed.startsWith("!")) { //若开头是!,解析Shell命令 ... } else { //以上三者都不是,则认为用户输入的为"select ..."正常的增删改查 HQL 语句,则进行 HQL 解析
try { try (CommandProcessor proc = CommandProcessorFactory.get(tokens, (HiveConf) conf)) { //执行真正的HQL,包括建库建表、查询、新增、修改、删除等等 if (proc instanceof IDriver) { // Let Driver strip comments using sql parser ret = processLocalCmd(cmd, proc, ss); } else { ret = processLocalCmd(cmd_trimmed, proc, ss); } } } catch (SQLException e) { ... } catch (Exception e) { throw new RuntimeException(e); } } ss.resetThreadName(); return ret; }
2.3.6 processLocalCmd 方法
int processLocalCmd(String cmd, CommandProcessor proc, CliSessionState ss) { boolean escapeCRLF = HiveConf.getBoolVar(conf, HiveConf.ConfVars.HIVE_CLI_PRINT_ESCAPE_CRLF); int ret = 0; if (proc != null) { if (proc instanceof IDriver) { IDriver qp = (IDriver) proc; PrintStream out = ss.out; long start = System.currentTimeMillis(); //获取本地时间 if (ss.getIsVerbose()) { out.println(cmd); } ret = qp.run(cmd).getResponseCode(); //执行内容,执行HQL if (ret != 0) { qp.close(); return ret; } // query has run capture the time long end = System.currentTimeMillis(); //再次获取本地时间 double timeTaken = (end - start) / 1000.0; //两者差值除1000,得到执行了多少秒 ArrayList<String> res = new ArrayList<String>(); printHeader(qp, out); //打印头信息 // print the results int counter = 0; //打印查询结果 try { if (out instanceof FetchConverter) { ((FetchConverter) out).fetchStarted(); } while (qp.getResults(res)) { for (String r : res) { if (escapeCRLF) { r = EscapeCRLFHelper.escapeCRLF(r); } out.println(r); } counter += res.size(); res.clear(); if (out.checkError()) { break; } } } catch (IOException e) { ... } qp.close(); if (out instanceof FetchConverter) { ((FetchConverter) out).fetchFinished(); } //控制台打印 console.printInfo( "Time taken: " + timeTaken + " seconds" + (counter == 0 ? "" : ", Fetched: " + counter + " row(s)")); } else { ... } } return ret; }
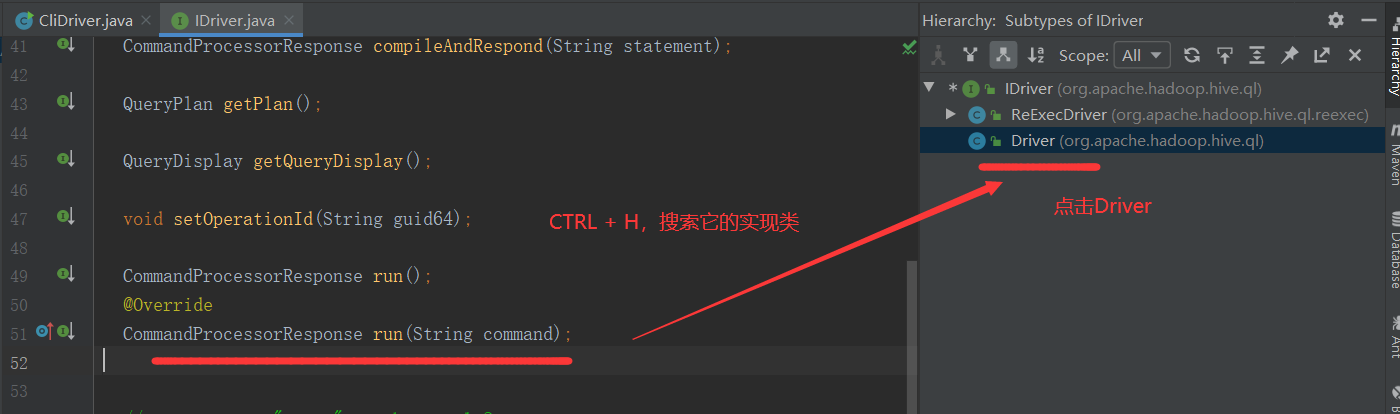
2.3.7 qp.run(cmd)方法
@Override
CommandProcessorResponse run(String command);
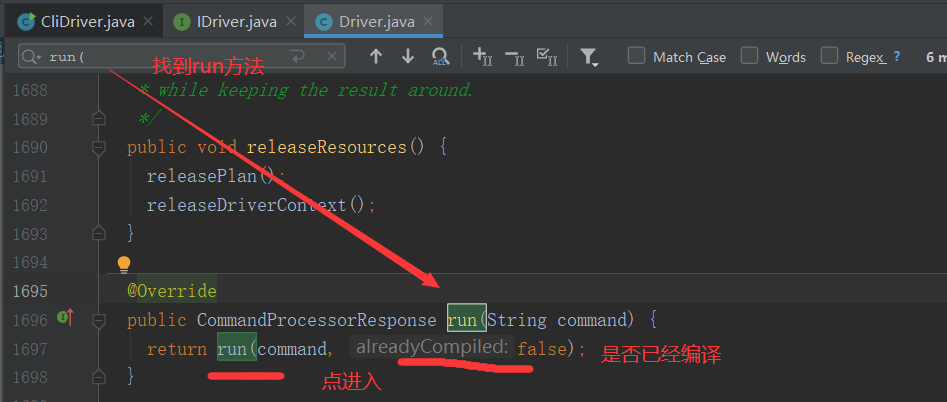
2.3.8 runInternal 方法
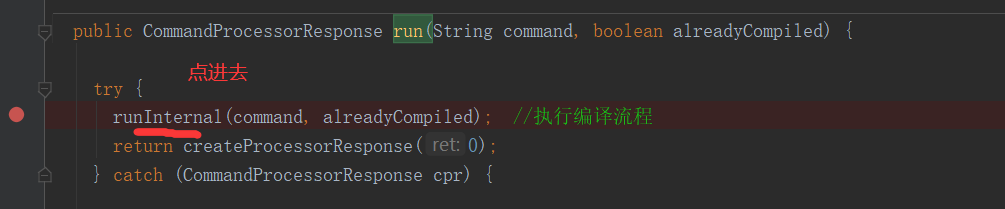
private void runInternal(String command, boolean alreadyCompiled) throws CommandProcessorResponse { errorMessage = null; SQLState = null; downstreamError = null; LockedDriverState.setLockedDriverState(lDrvState); lDrvState.stateLock.lock(); try { if (alreadyCompiled) { //判断是否编译 ... } else { lDrvState.driverState = DriverState.COMPILING; } } finally { lDrvState.stateLock.unlock(); } // a flag that helps to set the correct driver state in finally block by tracking if // the method has been returned by an error or not. boolean isFinishedWithError = true; try { ... if (!alreadyCompiled) { //如果没有编译,走这步 // compile internal will automatically reset the perf logger compileInternal(command, true); //编译,先将HQL语句解析为抽象语法树(解析器),再将抽象语法树编译为操作树(编译器),最后将操作树转为任务树并进行优化(优化器) // then we continue to use this perf logger perfLogger = SessionState.getPerfLogger(); } else { ... } ... try { execute(); //提交任务树执行(执行器) } catch (CommandProcessorResponse cpr) { rollback(cpr); throw cpr; } ... }
2.4 HQL 生成 AST(抽象语法树)
2.4.1 compileInternal 方法
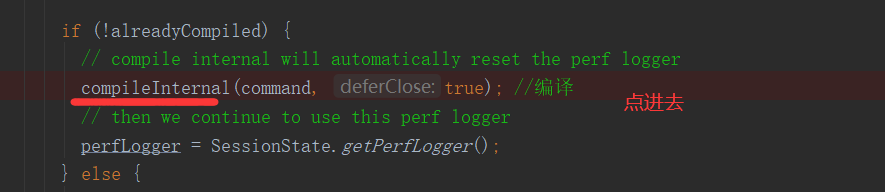
private void compileInternal(String command, boolean deferClose) throws CommandProcessorResponse { ... try { compile(command, true, deferClose); //编译操作 } catch (CommandProcessorResponse cpr) { ... } finally { compileLock.unlock(); } ... }
2.4.2 compile 方法
// deferClose indicates if the close/destroy should be deferred when the process has been // interrupted, it should be set to true if the compile is called within another method like // runInternal, which defers the close to the called in that method. private void compile(String command, boolean resetTaskIds, boolean deferClose) throws CommandProcessorResponse { ... try { ... ASTNode tree; try { tree = ParseUtils.parse(command, ctx); //获取抽象语法树(解析器工作) } catch (ParseException e) { parseError = true; throw e; } finally { hookRunner.runAfterParseHook(command, parseError); } ... sem.analyze(tree, ctx); //编译器、优化器在工作 ... } ... }
2.4.3 parse 方法


/** * Parses a command, optionally assigning the parser's token stream to the * given context. * * @param command * command to parse * * @param ctx * context with which to associate this parser's token stream, or * null if either no context is available or the context already has * an existing stream * * @return parsed AST */ public ASTNode parse(String command, Context ctx, String viewFullyQualifiedName) throws ParseException { if (LOG.isDebugEnabled()) { LOG.debug("Parsing command: " + command); } HiveLexerX lexer = new HiveLexerX(new ANTLRNoCaseStringStream(command)); //对HQL做语法、词法的解析,得到词法解析器HiveLexerX /** * 说明:Antlr 框架。Hive 使用 Antlr 实现 SQL 的词法和语法解析。Antlr 是一种语言识别 * 的工具,可以用来构造领域语言。 这里不详细介绍 Antlr,只需要了解使用 Antlr 构造特定 * 的语言只需要编写一个语法文件,定义词法和语法替换规则即可,Antlr 完成了词法分析、 * 语法分析、语义分析、中间代码生成的过程。 * Hive 中语法规则的定义文件在 0.10 版本以前是 Hive.g 一个文件,随着语法规则越来越 * 复杂,由语法规则生成的 Java 解析类可能超过 Java 类文件的最大上限,0.11 版本将 Hive.g * 拆成了 5 个文件,词法规则 HiveLexer.g 和语法规则的 4 个文件 SelectClauseParser.g, * FromClauseParser.g,IdentifiersParser.g,HiveParser.g。 * */ //将 HQL 中的关键词替换为 Token TokenRewriteStream tokens = new TokenRewriteStream(lexer); //将词法解析器传入TokenRewriteStream,获取tokens if (ctx != null) { if (viewFullyQualifiedName == null) { // Top level query ctx.setTokenRewriteStream(tokens); } else { // It is a view ctx.addViewTokenRewriteStream(viewFullyQualifiedName, tokens); } lexer.setHiveConf(ctx.getConf()); } HiveParser parser = new HiveParser(tokens); //对tokens做解析,得到HiveParser if (ctx != null) { parser.setHiveConf(ctx.getConf()); } parser.setTreeAdaptor(adaptor); HiveParser.statement_return r = null; try { r = parser.statement(); //进行语法解析,生成最终的 AST } catch (RecognitionException e) { e.printStackTrace(); throw new ParseException(parser.errors); } if (lexer.getErrors().size() == 0 && parser.errors.size() == 0) { LOG.debug("Parse Completed"); } else if (lexer.getErrors().size() != 0) { throw new ParseException(lexer.getErrors()); } else { throw new ParseException(parser.errors); } ASTNode tree = (ASTNode) r.getTree(); //从r中获取结果树 tree.setUnknownTokenBoundaries(); return tree; }
2.5 对 AST 进一步解析
接下来的步骤包括:
1)将 AST 转换为 QueryBlock 进一步转换为 OperatorTree;
2)对 OperatorTree 进行逻辑优化(LogicalOptimizer);
3)将 OperatorTree 转换为 TaskTree(任务树);
4)对 TaskTree 进行物理优化(PhysicalOptimizer)。
之所以将这 4 个步骤写在一起,是因为这几个步骤在源码中存在于一个方法中。
2.5.1 compile 方法(接 2.4.2 节 compile 方法继续往下)
// deferClose indicates if the close/destroy should be deferred when the process has been // interrupted, it should be set to true if the compile is called within another method like // runInternal, which defers the close to the called in that method. private void compile(String command, boolean resetTaskIds, boolean deferClose) throws CommandProcessorResponse { ... try { ... ASTNode tree; try { tree = ParseUtils.parse(command, ctx); //获取抽象语法树(解析器工作) } catch (ParseException e) { parseError = true; throw e; } finally { hookRunner.runAfterParseHook(command, parseError); } ... //进一步解析抽象语法树 sem.analyze(tree, ctx); //编译器、优化器在工作 ... } ... }
2.5.2 analyze 方法

public void analyze(ASTNode ast, Context ctx) throws SemanticException { initCtx(ctx); init(true); analyzeInternal(ast); }
2.5.3 analyzeInternal 方法
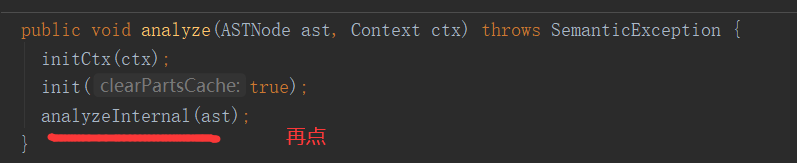
public abstract void analyzeInternal(ASTNode ast) throws SemanticException;
此方法为“org.apache.hadoop.hive.ql.parse.BaseSemanticAnalyzer”抽象类的抽象方法,我们进入实现类“org.apache.hadoop.hive.ql.parse.SemanticAnalyzer”的 analyzeInternal 方法
2.5.4 继续调用重载的 analyzeInternal 方法
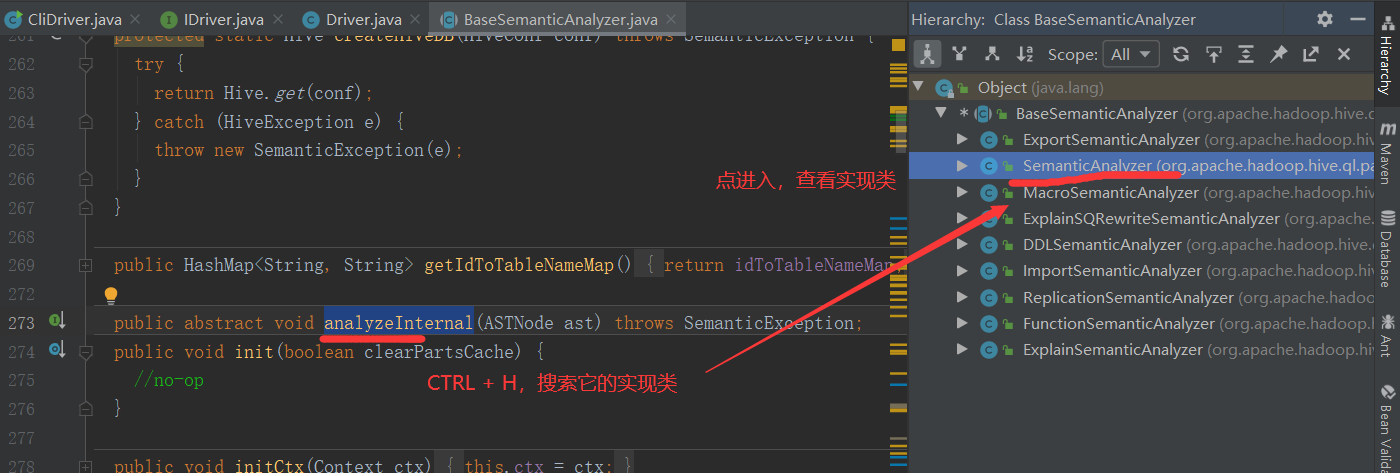
void analyzeInternal(ASTNode ast, PlannerContextFactory pcf) throws SemanticException { LOG.info("Starting Semantic Analysis"); // 1. Generate Resolved Parse tree from syntax tree (从语法树生成解析解析树) boolean needsTransform = needsTransform(); //change the location of position alias process here processPositionAlias(ast); PlannerContext plannerCtx = pcf.create(); //处理 AST,转换为 QueryBlock if (!genResolvedParseTree(ast, plannerCtx)) { return; } ... // 2. Gen OP Tree from resolved Parse Tree(解析来自解析树的生成树) Operator sinkOp = genOPTree(ast, plannerCtx); ... // 3. Deduce Resultset Schema (定义输出数据的 Schema) ... // 4. Generate Parse Context for Optimizer & Physical compiler(为优化器和物理编译器生成解析上下文) ... // 5. Take care of view creation(处理视图相关) ... // 6. Generate table access stats if required(如果需要,生成表访问统计信息) if (HiveConf.getBoolVar(this.conf, HiveConf.ConfVars.HIVE_STATS_COLLECT_TABLEKEYS)) { TableAccessAnalyzer tableAccessAnalyzer = new TableAccessAnalyzer(pCtx); setTableAccessInfo(tableAccessAnalyzer.analyzeTableAccess()); } // 7. Perform Logical optimization(执行逻辑优化) if (LOG.isDebugEnabled()) { LOG.debug("Before logical optimization " + Operator.toString(pCtx.getTopOps().values())); } //创建优化器 Optimizer optm = new Optimizer(); optm.setPctx(pCtx); optm.initialize(conf); //执行优化 pCtx = optm.optimize(); if (pCtx.getColumnAccessInfo() != null) { // set ColumnAccessInfo for view column authorization setColumnAccessInfo(pCtx.getColumnAccessInfo()); } if (LOG.isDebugEnabled()) { LOG.debug("After logical optimization " + Operator.toString(pCtx.getTopOps().values())); } // 8. Generate column access stats if required - wait until column pruning(如果需要,生成列访问统计信息 - 等到列修剪) // takes place during optimization(在优化期间发生) boolean isColumnInfoNeedForAuth = SessionState.get().isAuthorizationModeV2() && HiveConf.getBoolVar(conf, HiveConf.ConfVars.HIVE_AUTHORIZATION_ENABLED); if (isColumnInfoNeedForAuth || HiveConf.getBoolVar(this.conf, HiveConf.ConfVars.HIVE_STATS_COLLECT_SCANCOLS)) { ColumnAccessAnalyzer columnAccessAnalyzer = new ColumnAccessAnalyzer(pCtx); // view column access info is carried by this.getColumnAccessInfo(). setColumnAccessInfo(columnAccessAnalyzer.analyzeColumnAccess(this.getColumnAccessInfo())); } // 9. Optimize Physical op tree & Translate to target execution engine (MR, // TEZ..) (优化物理运算树并转换为目标执行引擎、执行物理优化) if (!ctx.getExplainLogical()) { TaskCompiler compiler = TaskCompilerFactory.getCompiler(conf, pCtx); compiler.init(queryState, console, db); //compile 为抽象方法,对应的实现类分别为 MapReduceCompiler、TezCompiler 和SparkCompiler compiler.compile(pCtx, rootTasks, inputs, outputs); fetchTask = pCtx.getFetchTask(); } //find all Acid FileSinkOperatorS QueryPlanPostProcessor qp = new QueryPlanPostProcessor(rootTasks, acidFileSinks, ctx.getExecutionId()); // 10. Attach CTAS/Insert-Commit-hooks for Storage Handlers(为存储处理程序附加 CTAS/Insert-Commit-hooks) ... // 11. put accessed columns to readEntity(将访问的列放入 readEntity) ... }
2.5.5 提交任务并执行(接 2.3.8 节 runInternal 方法继续往下)
private void runInternal(String command, boolean alreadyCompiled) throws CommandProcessorResponse { errorMessage = null; SQLState = null; downstreamError = null; LockedDriverState.setLockedDriverState(lDrvState); lDrvState.stateLock.lock(); try { if (alreadyCompiled) { //判断是否编译 ... } else { lDrvState.driverState = DriverState.COMPILING; } } finally { lDrvState.stateLock.unlock(); } // a flag that helps to set the correct driver state in finally block by tracking if // the method has been returned by an error or not. boolean isFinishedWithError = true; try { ... if (!alreadyCompiled) { //如果没有编译,走这步 // compile internal will automatically reset the perf logger compileInternal(command, true); //编译,先将HQL语句解析为抽象语法树(解析器),再将抽象语法树编译为操作树(编译器),最后将操作树转为任务树并进行优化(优化器) // then we continue to use this perf logger perfLogger = SessionState.getPerfLogger(); } else { ... } ... try { execute(); //提交任务树执行(执行器) } catch (CommandProcessorResponse cpr) { rollback(cpr); throw cpr; } ... }

private void execute() throws CommandProcessorResponse { ... try { ... //1.构建任务:根据任务树构建 MrJob setQueryDisplays(plan.getRootTasks()); int mrJobs = Utilities.getMRTasks(plan.getRootTasks()).size(); int jobs = mrJobs + Utilities.getTezTasks(plan.getRootTasks()).size() + Utilities.getSparkTasks(plan.getRootTasks()).size(); if (jobs > 0) { logMrWarning(mrJobs); console.printInfo("Query ID = " + queryId); console.printInfo("Total jobs = " + jobs); } ... perfLogger.PerfLogBegin(CLASS_NAME, PerfLogger.RUN_TASKS); // Loop while you either have tasks running, or tasks queued up while (driverCxt.isRunning()) { // Launch upto maxthreads tasks Task<? extends Serializable> task; while ((task = driverCxt.getRunnable(maxthreads)) != null) { //2.启动任务 TaskRunner runner = launchTask(task, queryId, noName, jobname, jobs, driverCxt); if (!runner.isRunning()) { break; } } ... } ... } //打印结果中最后的 OK if (console != null) { console.printInfo("OK"); } }
2.5.7 launchTask 方法
/** * Launches a new task * * @param tsk * task being launched * @param queryId * Id of the query containing the task * @param noName * whether the task has a name set * @param jobname * name of the task, if it is a map-reduce job * @param jobs * number of map-reduce jobs * @param cxt * the driver context */ private TaskRunner launchTask(Task<? extends Serializable> tsk, String queryId, boolean noName, String jobname, int jobs, DriverContext cxt) throws HiveException { if (SessionState.get() != null) { SessionState.get().getHiveHistory().startTask(queryId, tsk, tsk.getClass().getName()); } if (tsk.isMapRedTask() && !(tsk instanceof ConditionalTask)) { if (noName) { conf.set(MRJobConfig.JOB_NAME, jobname + " (" + tsk.getId() + ")"); } conf.set(DagUtils.MAPREDUCE_WORKFLOW_NODE_NAME, tsk.getId()); Utilities.setWorkflowAdjacencies(conf, plan); cxt.incCurJobNo(1); console.printInfo("Launching Job " + cxt.getCurJobNo() + " out of " + jobs); } tsk.initialize(queryState, plan, cxt, ctx.getOpContext()); TaskRunner tskRun = new TaskRunner(tsk); //添加启动任务 cxt.launching(tskRun); // Launch Task:根据是否可以并行来决定是否并行启动 Task if (HiveConf.getBoolVar(conf, HiveConf.ConfVars.EXECPARALLEL) && tsk.canExecuteInParallel()) { // Launch it in the parallel mode, as a separate thread only for MR tasks if (LOG.isInfoEnabled()){ LOG.info("Starting task [" + tsk + "] in parallel"); } //可并行任务启动,实际上还是执行 tskRun.runSequential(); tskRun.start(); } else { if (LOG.isInfoEnabled()){ LOG.info("Starting task [" + tsk + "] in serial mode"); } //不可并行任务,则按照序列顺序执行任务 tskRun.runSequential(); } return tskRun; }
2.5.8 runSequential 方法

/** * Launches a task, and sets its exit value in the result variable. */ public void runSequential() { int exitVal = -101; try { exitVal = tsk.executeTask(ss == null ? null : ss.getHiveHistory()); //执行任务 } catch (Throwable t) { if (tsk.getException() == null) { tsk.setException(t); } LOG.error("Error in executeTask", t); } result.setExitVal(exitVal); if (tsk.getException() != null) { result.setTaskError(tsk.getException()); } }
2.5.9 executeTask 方法
/** * This method is called in the Driver on every task. It updates counters and calls execute(), * which is overridden in each task * * @return return value of execute() */ public int executeTask(HiveHistory hiveHistory) { try { this.setStarted(); if (hiveHistory != null) { hiveHistory.logPlanProgress(queryPlan); } int retval = execute(driverContext); //执行 this.setDone(); if (hiveHistory != null) { hiveHistory.logPlanProgress(queryPlan); } return retval; } catch (IOException e) { throw new RuntimeException("Unexpected error: " + e.getMessage(), e); } }
2.5.10 execute 方法
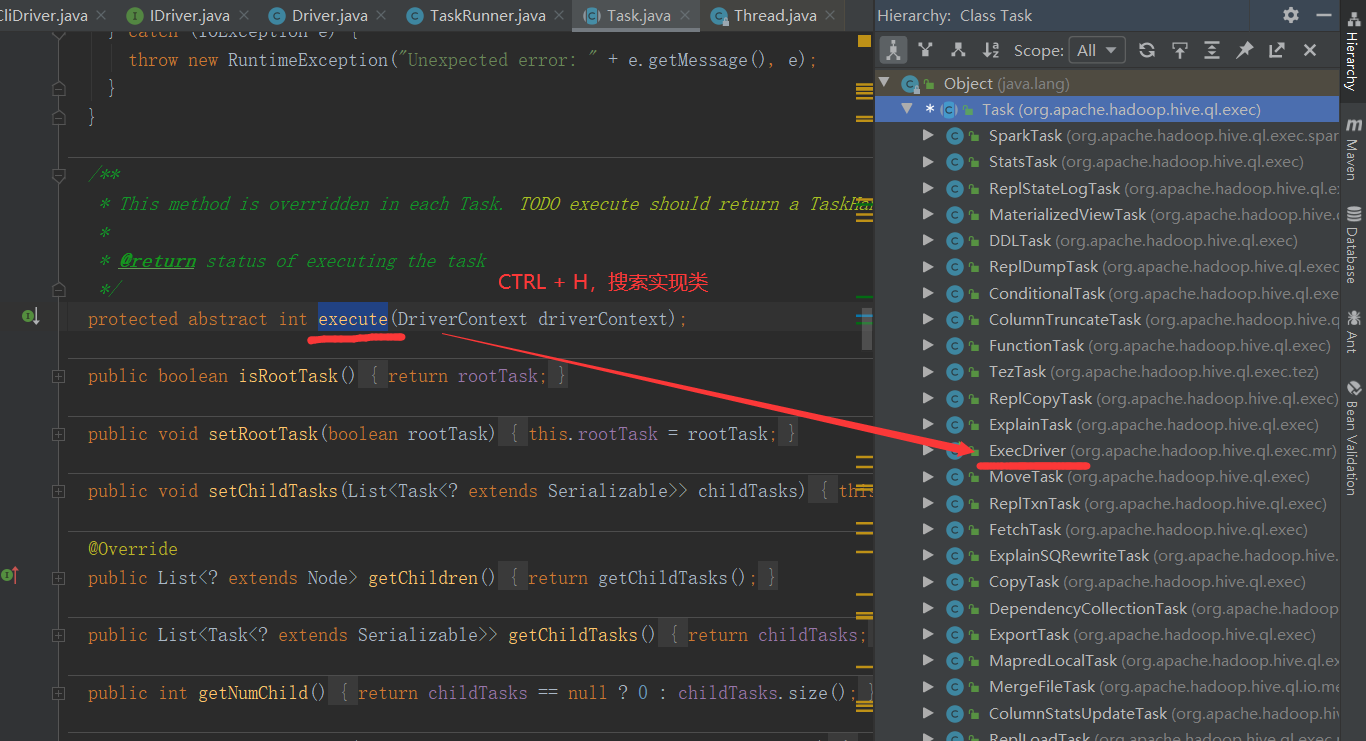
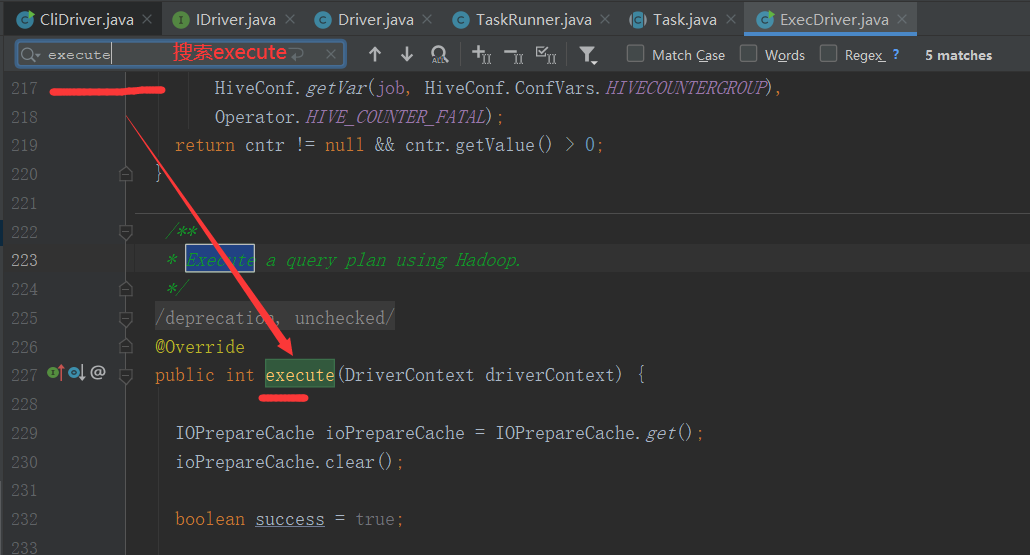
/** * Execute a query plan using Hadoop. */ @SuppressWarnings({"deprecation", "unchecked"}) @Override public int execute(DriverContext driverContext) { IOPrepareCache ioPrepareCache = IOPrepareCache.get(); ioPrepareCache.clear(); boolean success = true; //构建上下文环境 Context ctx = driverContext.getCtx(); boolean ctxCreated = false; Path emptyScratchDir; JobClient jc = null; if (driverContext.isShutdown()) { LOG.warn("Task was cancelled"); return 5; } MapWork mWork = work.getMapWork(); ReduceWork rWork = work.getReduceWork(); try { if (ctx == null) { ctx = new Context(job); ctxCreated = true; } emptyScratchDir = ctx.getMRTmpPath(); FileSystem fs = emptyScratchDir.getFileSystem(job); fs.mkdirs(emptyScratchDir); } catch (IOException e) { e.printStackTrace(); console.printError("Error launching map-reduce job", " " + org.apache.hadoop.util.StringUtils.stringifyException(e)); return 5; } HiveFileFormatUtils.prepareJobOutput(job); //See the javadoc on HiveOutputFormatImpl and HadoopShims.prepareJobOutput() job.setOutputFormat(HiveOutputFormatImpl.class); job.setMapRunnerClass(ExecMapRunner.class); job.setMapperClass(ExecMapper.class); job.setMapOutputKeyClass(HiveKey.class); job.setMapOutputValueClass(BytesWritable.class); try { String partitioner = HiveConf.getVar(job, ConfVars.HIVEPARTITIONER); job.setPartitionerClass(JavaUtils.loadClass(partitioner)); } catch (ClassNotFoundException e) { throw new RuntimeException(e.getMessage(), e); } propagateSplitSettings(job, mWork); job.setNumReduceTasks(rWork != null ? rWork.getNumReduceTasks().intValue() : 0); job.setReducerClass(ExecReducer.class); // set input format information if necessary setInputAttributes(job); // Turn on speculative execution for reducers boolean useSpeculativeExecReducers = HiveConf.getBoolVar(job, HiveConf.ConfVars.HIVESPECULATIVEEXECREDUCERS); job.setBoolean(MRJobConfig.REDUCE_SPECULATIVE, useSpeculativeExecReducers); String inpFormat = HiveConf.getVar(job, HiveConf.ConfVars.HIVEINPUTFORMAT); if (mWork.isUseBucketizedHiveInputFormat()) { inpFormat = BucketizedHiveInputFormat.class.getName(); } LOG.info("Using " + inpFormat); try { job.setInputFormat(JavaUtils.loadClass(inpFormat)); } catch (ClassNotFoundException e) { throw new RuntimeException(e.getMessage(), e); } // No-Op - we don't really write anything here .. job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); int returnVal = 0; boolean noName = StringUtils.isEmpty(job.get(MRJobConfig.JOB_NAME)); if (noName) { // This is for a special case to ensure unit tests pass job.set(MRJobConfig.JOB_NAME, "JOB" + Utilities.randGen.nextInt()); } try{ MapredLocalWork localwork = mWork.getMapRedLocalWork(); if (localwork != null && localwork.hasStagedAlias()) { if (!ShimLoader.getHadoopShims().isLocalMode(job)) { Path localPath = localwork.getTmpPath(); Path hdfsPath = mWork.getTmpHDFSPath(); FileSystem hdfs = hdfsPath.getFileSystem(job); FileSystem localFS = localPath.getFileSystem(job); FileStatus[] hashtableFiles = localFS.listStatus(localPath); int fileNumber = hashtableFiles.length; String[] fileNames = new String[fileNumber]; for ( int i = 0; i < fileNumber; i++){ fileNames[i] = hashtableFiles[i].getPath().getName(); } //package and compress all the hashtable files to an archive file String stageId = this.getId(); String archiveFileName = Utilities.generateTarFileName(stageId); localwork.setStageID(stageId); CompressionUtils.tar(localPath.toUri().getPath(), fileNames,archiveFileName); Path archivePath = Utilities.generateTarPath(localPath, stageId); LOG.info("Archive "+ hashtableFiles.length+" hash table files to " + archivePath); //upload archive file to hdfs Path hdfsFilePath =Utilities.generateTarPath(hdfsPath, stageId); short replication = (short) job.getInt("mapred.submit.replication", 10); hdfs.copyFromLocalFile(archivePath, hdfsFilePath); hdfs.setReplication(hdfsFilePath, replication); LOG.info("Upload 1 archive file from" + archivePath + " to: " + hdfsFilePath); //add the archive file to distributed cache DistributedCache.createSymlink(job); DistributedCache.addCacheArchive(hdfsFilePath.toUri(), job); LOG.info("Add 1 archive file to distributed cache. Archive file: " + hdfsFilePath.toUri()); } } work.configureJobConf(job); List<Path> inputPaths = Utilities.getInputPaths(job, mWork, emptyScratchDir, ctx, false); Utilities.setInputPaths(job, inputPaths); Utilities.setMapRedWork(job, work, ctx.getMRTmpPath()); if (mWork.getSamplingType() > 0 && rWork != null && job.getNumReduceTasks() > 1) { try { handleSampling(ctx, mWork, job); job.setPartitionerClass(HiveTotalOrderPartitioner.class); } catch (IllegalStateException e) { console.printInfo("Not enough sampling data.. Rolling back to single reducer task"); rWork.setNumReduceTasks(1); job.setNumReduceTasks(1); } catch (Exception e) { LOG.error("Sampling error", e); console.printError(e.toString(), " " + org.apache.hadoop.util.StringUtils.stringifyException(e)); rWork.setNumReduceTasks(1); job.setNumReduceTasks(1); } } jc = new JobClient(job); // make this client wait if job tracker is not behaving well. Throttle.checkJobTracker(job, LOG); if (mWork.isGatheringStats() || (rWork != null && rWork.isGatheringStats())) { // initialize stats publishing table StatsPublisher statsPublisher; StatsFactory factory = StatsFactory.newFactory(job); if (factory != null) { statsPublisher = factory.getStatsPublisher(); List<String> statsTmpDir = Utilities.getStatsTmpDirs(mWork, job); if (rWork != null) { statsTmpDir.addAll(Utilities.getStatsTmpDirs(rWork, job)); } StatsCollectionContext sc = new StatsCollectionContext(job); sc.setStatsTmpDirs(statsTmpDir); if (!statsPublisher.init(sc)) { // creating stats table if not exists if (HiveConf.getBoolVar(job, HiveConf.ConfVars.HIVE_STATS_RELIABLE)) { throw new HiveException(ErrorMsg.STATSPUBLISHER_INITIALIZATION_ERROR.getErrorCodedMsg()); } } } } Utilities.createTmpDirs(job, mWork); Utilities.createTmpDirs(job, rWork); SessionState ss = SessionState.get(); // TODO: why is there a TezSession in MR ExecDriver? if (ss != null && HiveConf.getVar(job, ConfVars.HIVE_EXECUTION_ENGINE).equals("tez")) { // TODO: this is the only place that uses keepTmpDir. Why? TezSessionPoolManager.closeIfNotDefault(ss.getTezSession(), true); } HiveConfUtil.updateJobCredentialProviders(job); // Finally SUBMIT the JOB! if (driverContext.isShutdown()) { LOG.warn("Task was cancelled"); return 5; } rj = jc.submitJob(job); if (driverContext.isShutdown()) { LOG.warn("Task was cancelled"); killJob(); return 5; } this.jobID = rj.getJobID(); updateStatusInQueryDisplay(); returnVal = jobExecHelper.progress(rj, jc, ctx); success = (returnVal == 0); } catch (Exception e) { ... } finally { ... } ... }
第 3 章 Hive 源码 Debug 介绍
3.1 Debug 环境准备
3.1.1 下载源码包
下载 Hive 源码包,自行编译一下,建议在 Linux 环境下编译,然后将整个编译好的包全部拷贝到 IDEA 工作目录中并使用 IDEA 打开。该文档是以 Hive3.1.2 版本作为讲解的。在资料包中提供了已经编译好的 Hive 源码包。
3.1.2 打开项目配置项,添加远程连接配置组
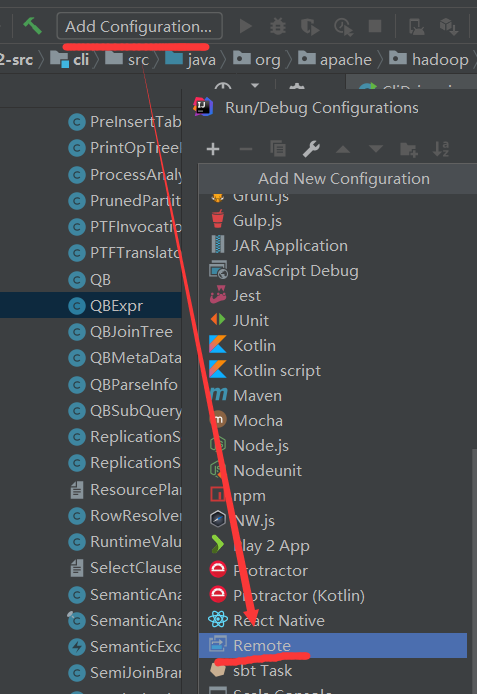
3.1.3 添加配置信息

3.2 测试
3.2.1 在 CliDriver 类的 run 方法中随意打上断点

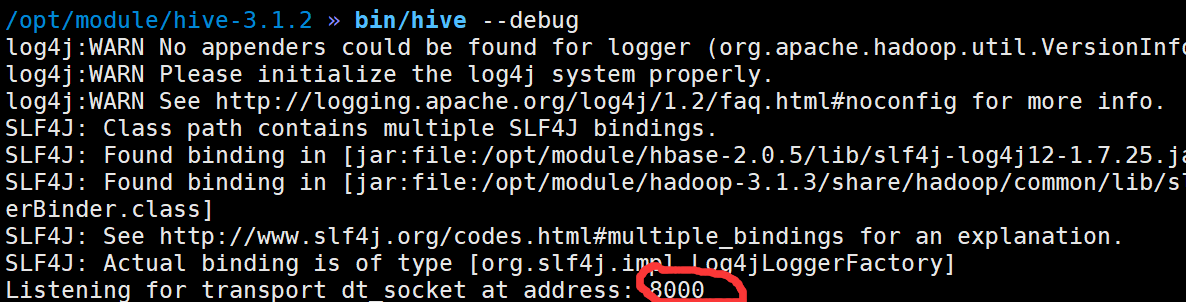
3.2.2 开启 Hive 客户端 Debug 模式
$HIVE_HOME/bin/hive --debug
3.2.3 使用 debug 模式启动本地项目

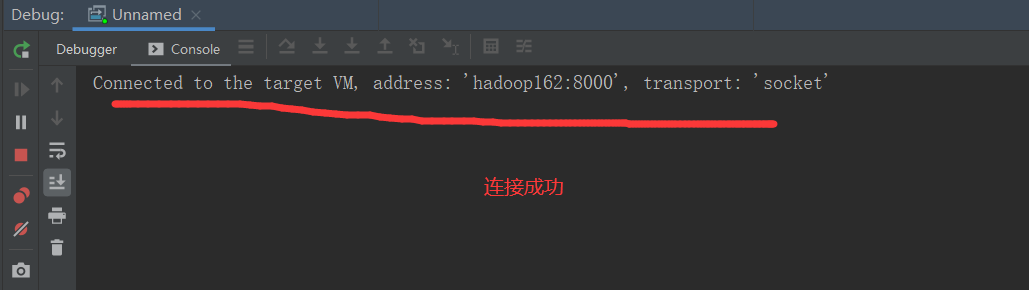
3.2.4 在 Hive 客户端中执行 HQL,切换到 IDEA 中查看
1)在 IDEA 中查看断点

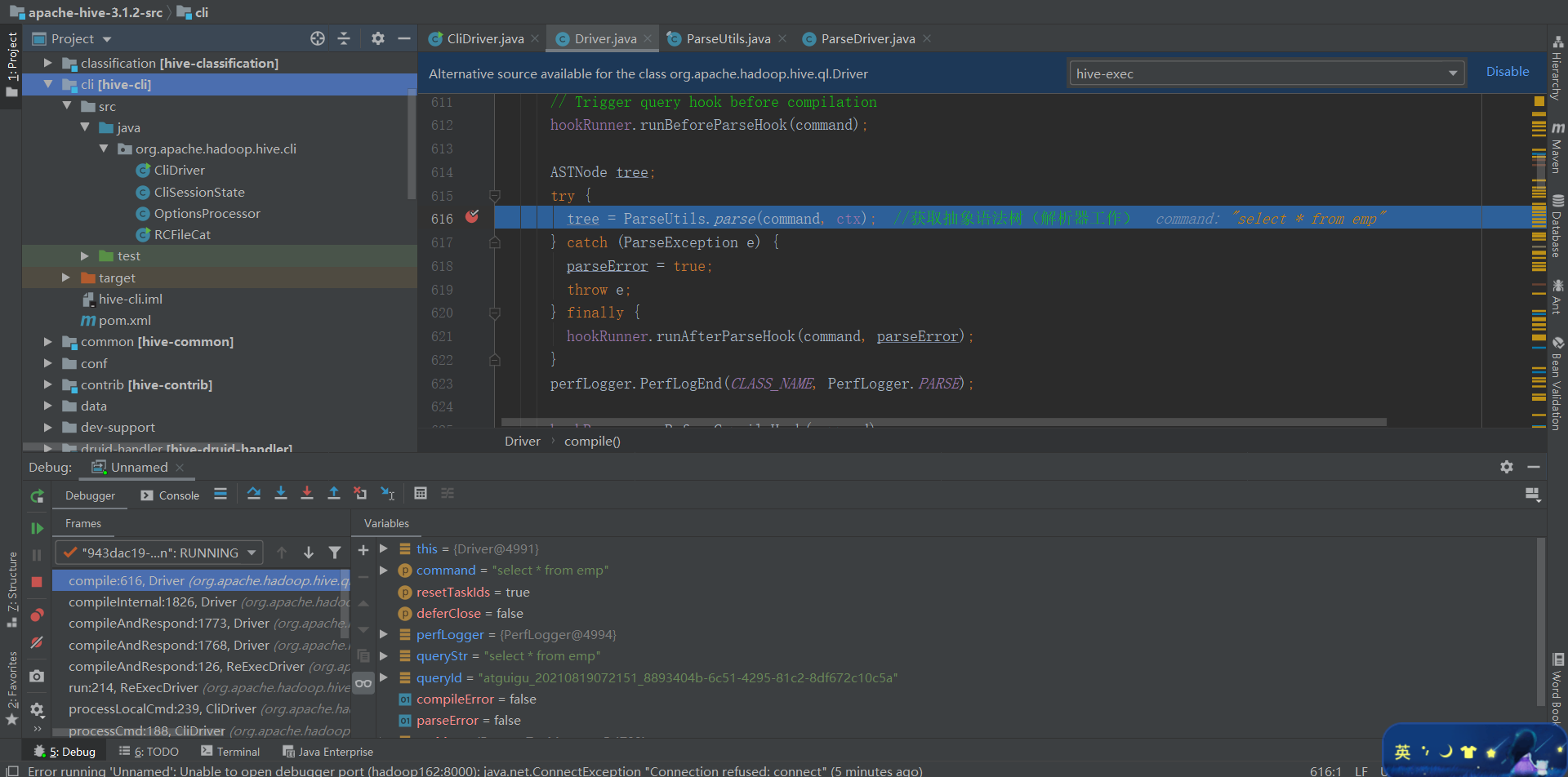
2)在 Hive Debug 模式客户端查看
