一、HBase 是什么
Apache HBase is the Hadoop database,distributed scalable,versioned, non-relational database modeled after Google's Bigtable. (Apache HBase是 Hadoop 数据库,是模仿 Google 的 Bigtable 建模的分布式可伸缩,版本化,非关系型数据库)。
可以随机的、实时的进行大数据的读写。
十几亿行、上百万列,可以运行在普通机器上。
数据可以存储在 HDFS。
面向列的。
二、数据存储现状
1、RDBMS (Relational Database Management System)
* MySQL、Oracle、SQL Server ... ...
* 有类型且结构化数据
* 实体类对应着数据库中的表
* 每一条记录对应着数据库表中的行(row)
* Query:groupBy、Join ... ...
缺点:大数据,数据量大且会对其做很多操作来抽取出我们有意义的结果。
(1)实时查询
(2)集群成本高
(3)RDBMS 横向扩展来增加的效率是有限的
(4)RDBMS 中 MySQL、Oracle收费,Hadoop开源
2、HDFS (Hadoop Distributed File System)
* NameNode、SecondaryNameNode、DataNode 三部分
* NameNode 用来管理文件系统的命名空间、集群配置信息和存储块的复制等;
SecondaryNameNode 并非是NameNode的备份,它作为 NameNode的辅助,用来分担NameNode的工作量,辅助NameNode定期合并 fsimage 和 edit file,控制edit file的大小在限制范围内;
DataNode 是文件存储的基本单元,用来存储Block到本地文件系统中,并定期的将所有Block的信息发送给 NameNode。
* 处理超大文件 TB、PB
* 对硬件的要求低,可以运行在廉价的商用机器集群上
缺点:
(1)没办法实时查询:HDFS 处理大型数据集分析任务,主要是达到高的数据吞吐量而设计的,高延迟则是作为代价。
(2)随机读写没法做到很好的支持:HDFS是块存储,可以随机读写文件块,但是对文件不支持随机读写,因为一个文件块中有很多文件
(3)无法高效存储小文件
3、NoSQL Not Only SQL
* HBase、Redis ... ...
三、HBase 在 Hadoop 中的位置
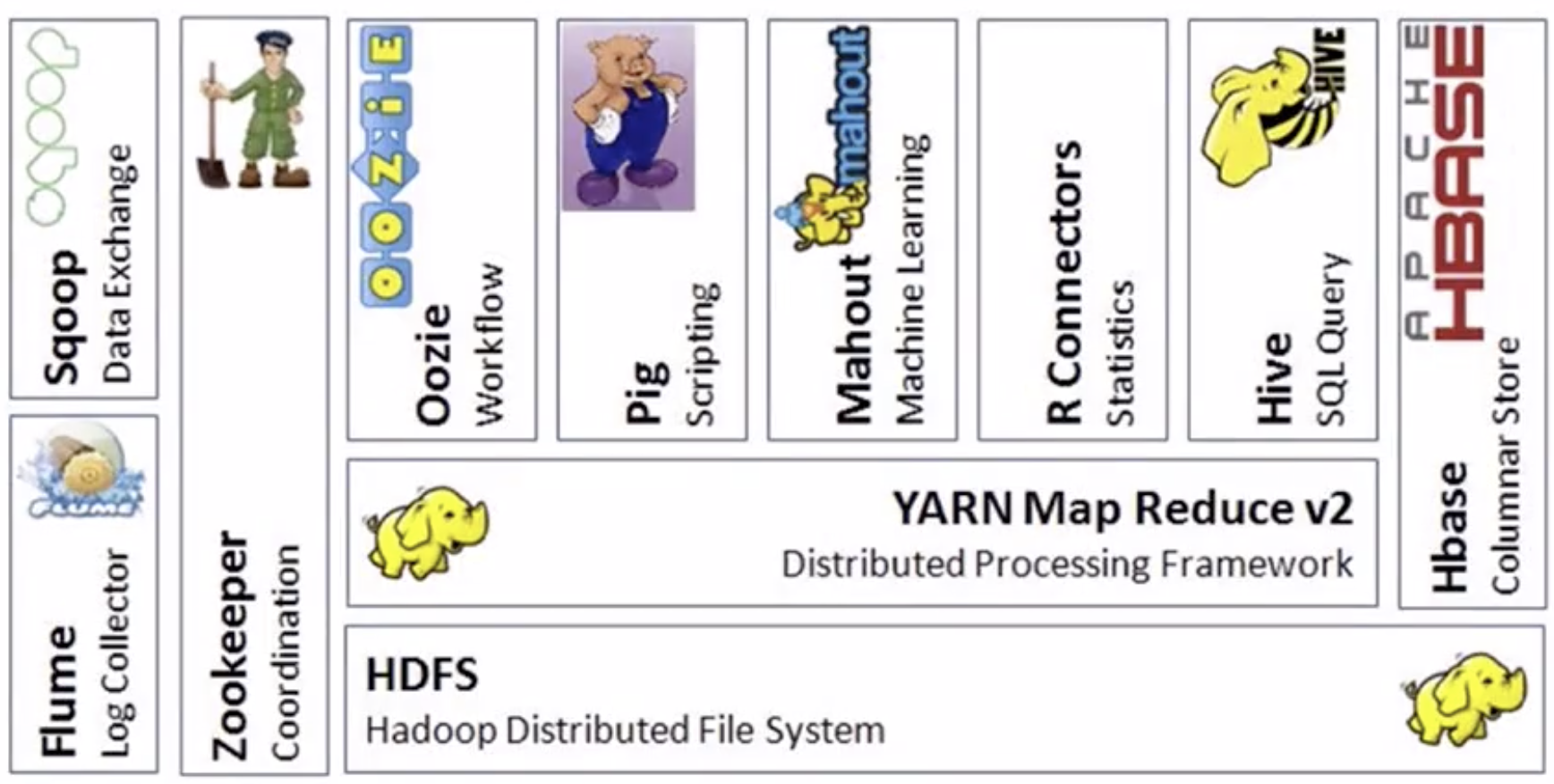
HBase 是 Hadoop 生态圈中的一个重要部分,HBase 构建在 HDFS 上,也就是说 HBase 的数据可以存储在 HDFS 上面,可以通过 MapReduce/Spark 来处理 HBase 中的数据。HBase 也提供 Shell、API 的方式来进行数据库的访问。
HBase 存储方式为列式存储。行式存储 是将每一行数据按行存储,整行读取查询的时候耗费大量的IO,可以用索引或者视图来提速。列式存储 压缩并行处理,查询的数据就是索引,降低了IO。
四、HBase 特点
1、能够存储的数据量大,数十亿行数百万列
2、面向列,列族(可存放很多列),列/列族独立索引
3、稀疏,对于空列不会占用存储空间
4、数据类型单一,Bytes/String
5、无模式,每一行数据所对应的列不一定相同
6、数据多版本,比如 Company 可以存储不同版本的值,默认情况下版本号是自动分配的,是列的值得插入时间的时间戳。
五、比较
1、 HBase vs RDBMS
* 数据类型不同
* 数据操作,HBase 表与表之间关联查询不行,需要用到 Spark/MapReduce/Phoenix
* 存储模式不同
* 事务,HBase单行有事务,RDBMS 多行都有事务
* 读写吞吐量: RDBMS 几千次/s HBase Billin级别
2、HBase vs HDFS
HDFS: 整个文件读取,或分区目录读取
HBase:随机读取、根据范围来查,整表读
SQL方面,HDFS 可以通过 Hive 来使用SQL,HBase 无法使用 SQL 语句
六、HBase 数据模型
| RowKey | Column Family | Column Family | |||
| Column1 | Column2 | Column3 | Column4 | Column5 | |
| Row1 | CellValue | CellValue | CellValue | ||
| Row2 | CellValue | CellValue | CellValue | ||
| Row3 | CellValue | CellValue | |||
| Row4 | CellValue |
Value1/Value2/Value3 |
CellValue | CellValue | |
| Row5 | CellValue | ||||
| Row6 | CellValue | CellValue | CellValue | ||
如(Row4,Column2),每个 Cell 保存同一份数据的不同版本, Cell 中的数据按照时间戳倒序排列。
1、RowKey 作为主键,字符串类型,按照字典顺序存储,内存保存的是字节数组
2、列族(Column Family) CF 创建表的时候就要指定,是一系列列的集合,一个列族的所有列有相同的前缀。
3、每条记录被划分成多个CF中,每个记录对应一个RowKey,每个CF有一个或多个列构成
七、安装
单机安装,HMaster, HRegionServer 都安装在本地。
1、下载 hbase 安装包 下载包地址:https://hbase.apache.org/downloads.html
2、配置 HBase,修改 conf 中的两个文件
hbase-env.sh
export JAVA_HOME = <本地 JAVA_HOME 地址> export HBASE_MANAGES_ZK=false
hbase-site.xml
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://localhost:8020/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>localhost:2181</value> </property> </configuration>
3、启动 HBase
bin/start-hbase.sh
启动成功后,jps 会发现 HMaster 和 HRegionServer 两个进程
HBase 本地web页面地址:http://localhost:16010/
在安装 HBase 之前需要先安装 Zookeeper,我上面的配置就是在我本地安装好了 Zookeeper 的前提。其实也可以不安装,因为HBase的安装包里自带Zookeeper。用自带的Zookeeper,则上面的配置不太一样。