本文是我之前看"Go程序设计语言"和"Go语言实战"的一些笔记。还没看完,后续有时间再补充。
1、程序结构
1.1、名称
- Go中函数、变量、常量、类型、语句标签和包的名称遵循一个简单地规则:名称的开头是一个字母或下划线,后面可以跟任意数量的字符、数字和下划线,并区分大小写。
- 如果一个名字是在函数内部定义,那么它只在函数内部有效。如果在函数外部定义,那么将在当前包的所有文件中都可以访问。名字的开头字母的大小写决定了名字在包外的可见性。如果一个名字是大写字母开头的(必须是在函数外部定义的包级名字;包级函数名本身也是包级名字),那么它将是导出的,也就是说可以被外部的包访问,例如fmt包的Printf函数就是导出的,可以在fmt包外部访问。包本身的名字一般总是用小写字母。
1.2、声明
声明就是给一个程序实体命名,并且设定其部分或全部属性。有4个主要的声明:变量(var)、常量(const)、类型(type)、函数(func)。
package main
import "fmt"
const boilingF = 212.0
func main() {
var f = boilingF
var c = (f - 32) * 5 / 9
fmt.Printf("boiling point = %g°F or %g°C
", f, c)
// 输出:boiling point = 212°F or 100°C
}
1.3、变量
变量的声明形式一般是:
var 变量名字 类型 = 表达式
其中"类型"和"表达式"可以省略一个,但是不能都省略。如果省略类型,它的类型将由表达式决定;如果表达式省略,其初始值对应于类型的零值——对于数字时0,布尔是false,字符串是"",接口和引用类型(slice、指针、map、chan和函数)是nil。对于一个像数组或结构体这样的复合类型,零值是其所有元素或成员的零值。
1.3.1、简短变量声明
名字:= 表达式
package main
import "fmt"
func main() {
var s string
fmt.Println(s) // 输出 ""
var n int
fmt.Println(n) // 输出 0
var f bool
fmt.Println(f) // 输出 false
i := 100 // 一个int类型的变量
fmt.Println(i) // 输出 100
}
1.3.2、指针
package main
import "fmt"
func main() {
x := 1
p := &x // p是整型指针,指向x
fmt.Println(*p) // 输出 1
*p = 2 // 等价于 x = 2
fmt.Println(*p) // 输出 2
}
1.3.3、new函数
另一个创建变量的方法是使用内置的new函数。表达式new(T)将创建一个T类型的匿名变量,初始化为T类型的零值,然后返回变量地址,返回的指针类型是 *T。
package main
import "fmt"
func main() {
p := new(int) // *int类型的p,指向未命名的int变量
fmt.Println(*p) // 输出 0
*p = 2 // 把未命名的int设置为2
fmt.Println(*p) // 输出 2
}
下面两个newInt函数有同样的行为:
func newInt() *int {
return new(int)
}
func newInt() *int {
var dummy int
return &dummy
}
1.3.4、变量的生命周期
变量的生命周期是指在程序运行期间变量有效存在的时间间隔。对于在包一级声明的变量,它们的生命周期和整个程序的运行周期是一致的。局部变量的生命周期则是动态的:每次从床架一个新变量的声明语句开始,直到该变量不再被引用为止,然后变量的存储空间可能被回收。函数的参数变量和返回值变量都是局部变量。它们在函数每次被调用的时候创建。
1.4、赋值
x = 1 // 有名称的变量
*p = true // 间接变量
person.name = "bob" // 结构体成员
count[x] = count[x] * scale // 数组或slice或map元素
count[x] *= scale // 等价于 count[x] = count[x] * scale
x, y = y, x
_, ok = x.(T) // 检查类型但丢弃结果
1.5、类型声明
一个类型声明语句创建了一个新的类型名称,和现有类型具有相同的底层结构。新命名的类型提供了一个方法,用来分隔不同概念的类型,这样即使它们底层类型相同也是不兼容的。
type 类型名字 底层类型
举例:
package main
import "fmt"
type Celsius float64 // 摄氏温度
type Fahrenhit float64 // 华氏温度
const (
AbsoluteZeroC Celsius = -273.15 // 绝对零度
FreezingC Celsius = 0 // 结冰点温度
BoilingC Celsius = 100 // 沸水温度
)
func CToF(c Celsius) Fahrenhit {
return Fahrenhit(c *9 / 5 + 32) // 注意这里Fahrenhit不是函数,而是类型转换
}
func FToC(f Fahrenhit) Celsius {
return Celsius((f - 32) * 5 / 9)
}
func main() {
fmt.Printf("%g
", BoilingC - FreezingC)
boilingF := CToF(BoilingC)
fmt.Printf("%g
", boilingF - CToF(FreezingC))
// fmt.Printf("%g
", boilingF - FreezingC) // 编译错误:类型不匹配
var c Celsius
var f Fahrenhit
fmt.Println(c == 0) // true
fmt.Println(f >= 0) // true
// fmt.Println(c == f) // 编译错误:类型不匹配
fmt.Println(c == Celsius(f)) // true
}
2、基本数据类型
Go语言将数据类型分为四类:基础类型、复合类型、引用类型和接口类型。基础类型包括:数字、字符串、布尔型。复合类型包括数组和结构体。引用类型包括指针、
切片(slice)、字典(map)、函数、通道(channel)。本章学习基础类型。
2.1、整型
Go同时具备有符号整数和无符号整数。有符号整数分四种:int8, int16, int32, int64、对应的无符号整数是uint8, uint16, uint32, uint64。此外,还有两种类型int 和 uint
2.2、浮点数
Go支持两种大小的浮点数float32和float64.十进制下,float32的有效数字大约是6位,float64的有效数字大约是15位。绝大多数情况下,应优先选择float64
2.3、复数
Go具备两种大小的复数complex64和complex128,二者分别由float32和float64构成。内置的complex函数根据给定的实部和虚部创建复数,而内置的real函数和imag函数则分别提取复数的实部和虚部。
package main
import (
"fmt"
"math/cmplx"
)
func main() {
var x complex128 = complex(1, 2) // 1 + 2i
var y complex128 = complex(3, 4) // 3 + 4i
fmt.Println(x * y) // (-5 + 10i)
fmt.Println(real(x * y)) // -5
fmt.Println(imag(x * y)) // 10
fmt.Println(1i * 1i) // (-1 + 0i)
fmt.Println(cmplx.Sqrt(-1)) // (0 + 1i)
}
2.4、布尔值
bool型的值只有两种可能:true或者false。
2.5、字符串
package main
import "fmt"
func main() {
s := "hello, world"
// 内置的len函数返回字符串的字节数(并非文字符号的数目)
fmt.Println(len(s)) // 12
// 下标访问操作s[i]
fmt.Println(s[0], s[7]) // 104 119 ('h' and 'w')
// 子串生成操作s[i:j]产生一个新字符串,下标从i开始,直到j(不包含j)
fmt.Println(s[0:5]) // hello
// 省略i,则默认i是0
fmt.Println(s[:5]) // hello
// 省略j, 默认值是len(s)
fmt.Println(s[7:]) // world
fmt.Println(s[:]) // "hello, world"
// 加号运算符连接两个字符串而生成一个新字符串
fmt.Println("goodbye" + s[5:]) // goodbye, world
s = "left foot"
t := s
// 字符串是一个不可改变的字节序列,但是这个表达式是正确的,
// 只是将 +=语句生成的新字符串赋给s,同时t仍有旧的字符串值
s += ", right foot"
fmt.Println(s)
fmt.Println(t)
//s[0] = 'L' // 编译错误,s[0]无法赋值
}
2.6、常量
若同时声明一组常量,除了第一项之外,其他项在等号右侧的表达式都可以省略, 这意味着会复用前面一项的表达式及其类型。
package main
import "fmt"
func main() {
const (
a = 1
b
c = 2
d
)
fmt.Println(a, b, c, d) // 1 1 2 2
}
常量生成器iota:常量的声明可以用常量生成器iota,它创建一系列相关值,而不是逐个值显式写出。常量声明中,iota从0开始取值,逐项加1。
type Weekday int
const (
Sunday Weekday = iota
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
)
上面的声明中,Sunday的值是0,Monday的值是1.以此类推。
3、复合数据类型
3.1、数组
package main
import "fmt"
func main() {
var a [5]int // 5个整数的数组
fmt.Println("array a:", a) // array a: [0 0 0 0 0]
a[1] = 10
a[2] = 30
fmt.Println("assign:", a) // assign: [0 10 30 0 0]
fmt.Println("len:", len(a)) // len: 5
b := [5]int{1, 2, 3, 4, 5}
fmt.Println("init:", b) // init: [1 2 3 4 5]
var c [2][3]int
for i := 0; i < 2; i++ {
for j := 0; j < 3; j++ {
c[i][j] = i + j
}
}
fmt.Println("2d: ", c) // 2d: [[0 1 2] [1 2 3]]
}
数组的切片操作
package main
import "fmt"
func main() {
a := [5]int{1, 2, 3, 4, 5}
b := a[2:4] // a[2]和a[3],但不包括a[4]
fmt.Println(b) // [3 4]
b = a[:4] // 从a[0]到a[4],但不包括a[4]
fmt.Println(b) // [1 2 3 4]
b = a[2:] // 从a[2]到a[4],且包括a[2]
fmt.Println(b) // [3 4 5]
}
当调用一个函数的时候,函数的每个调用参数将会被赋值给函数内部的参数变量,所以函数参数变量接收的是一个复制的副本,并不是原始调用的变量。因为函数参数传递的机制导致传递大的数组类型将是低效的,并且对数组参数的任何修改都是发生在复制的数组上,并不能直接修改调用时原始的数组变量。在这方面,Go语言对待数组的方式和其他很多编程语言不同,其他编程语言可能会隐式地将数组作为引用或指针对象传入被调用的函数。
当然,我们可以显式地传入一个数组指针,那样的话函数通过指针对数组的任何修改都可以直接反馈到调用者。
package main
import "fmt"
func zero(ptr [32]byte) {
for i := 0; i < 32; i++ {
ptr[i] = 0
}
}
func zero1(ptr *[32]byte) {
for i := range ptr {
ptr[i] = 0
}
}
func main() {
var q [32]byte
for i := 0; i < 32; i++ {
q[i] = (byte)(i)
}
// before: [0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31]
fmt.Println("before:", q)
zero(q) // 由于入参是数组,所以并不能改变外面数组的值
// after: [0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31]
fmt.Println("after:", q)
zero1(&q) // 传入的是指针,可以改变外面数组的值
// after1: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
fmt.Println("after1:", q)
}
3.2、切片:slice
slice表示一个拥有相同类型元素的可变长度的序列。slice通常写成[]T,其中元素的类型都是T。
数组和slice是紧密关联的。slice是一种轻量级的数据结构,可以用来访问数组的部分或者全部的元素,而这个数组称为slice的底层数组。slice有三个属性:指针、长度和容量。指针指向数组的第一个可以从slice中访问的元素,而这个元素并不一定是数组的第一个元素。长度是指slice中的元素个数,它不能超过slice的容量。容量的大小通常是从slice的起始元素到底层数组的最后一个元素间的个数。Go的内置函数len和cap用来返回slice的长度和容量。一个底层数组可以对应多个slice,这些slice可以引用数组的任何位置,彼此之间的元素还可以重叠。
package main
import "fmt"
func main() {
months := [...]string{1: "January", 2: "Februay", 3: "March", 4: "April",
5: "May", 6: "June", 7: "July", 8: "August",
9: "September", 10: "October", 11: "November", 12: "December"}
Q2 := months[4:7]
summer := months[6:9]
fmt.Println(Q2, len(Q2), cap(Q2)) // [April May June] 3 9
fmt.Println(summer, len(summer), cap(summer)) // [June July August] 3 7
}
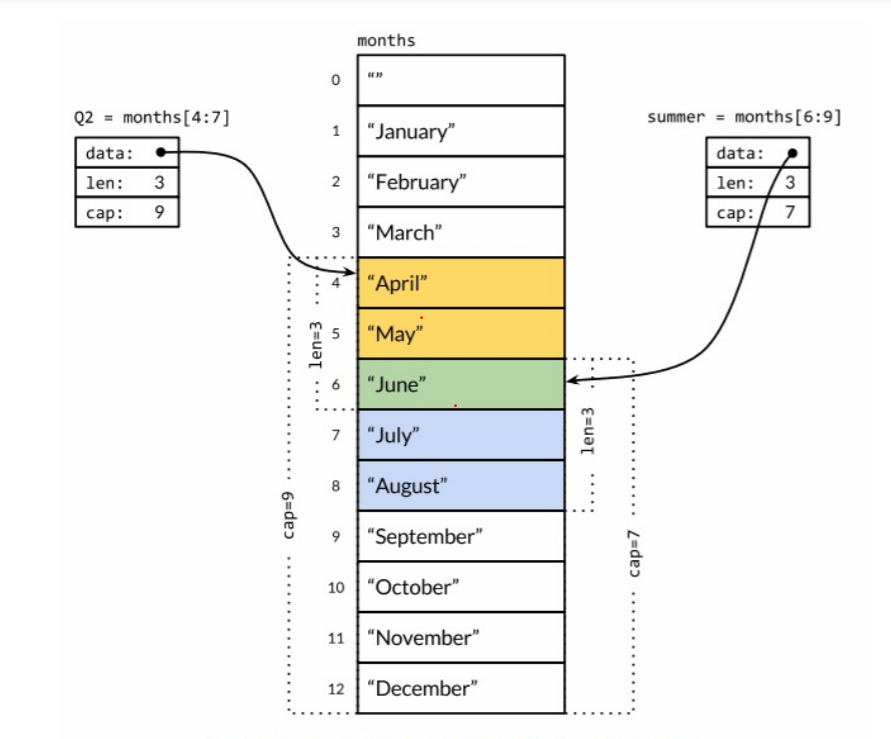
)
因为slice包含了指向数组元素的指针,所以将一个slice传递给函数时,可以在函数内部修改底层数组的元素。
package main
import "fmt"
func reverse(s []int) {
for i, j := 0, len(s)-1; i < j; i, j = i+1, j-1 {
s[i], s[j] = s[j], s[i]
}
}
func main() {
a := [...]int{0, 1, 2, 3, 4, 5}
reverse(a[:])
fmt.Println(a) // [5 4 3 2 1 0]
}
3.2.1、切片的创建与初始化
- 通过make
// 如果指指定长度,那么切片的长度和容量相等
// 创建一个字符串切片,其长度和容量都是5
slice := make([]string, 5)
// 指定长度和容量
// 创建一个整型切片,其长度为3个元素,容量为5
slice := make([]int, 3, 5)
// 不允许创建容量小于长度的切片,在编译时会报错
slice := make([]int, 5, 3) // Compiler Error:len larger than cap in make([]int)
- 使用切片字面量
// 创建字符串切片,其长度和容量都是5
slice := []string{"Red", "Blue", "Green", "Yellow", "Pink"}
// 创建一个整型切片,其长度和容量都是3
slice := []int{10, 20, 30}
3、创建nil切片
在声明时不做任何初始化,就会创建一个nil切片。nil切片的长度和容量都是0。
// 创建nil整型切片
var slice []int
3.2.2、append函数
内置函数append用来将元素追加到slice后面。
package main
import "fmt"
func main() {
// 创建一个整型切片,其长度和容量都是5个元素
slice := []int{10, 20, 30, 40, 50}
// 创建一个新切片,其长度为2个元素,容量为3个元素
newSlice := slice[1:3]
fmt.Println(newSlice) // [20 30]
// 使用原有的容量来分配一个新元素,将新元素赋值为60
newSlice = append(newSlice, 60)
fmt.Println(newSlice) // [20 30 60]
fmt.Println(slice) // [10 20 30 60 50], 由于是共享一个底层数组,所以一个切片改值了,另一个也改了
}
3.2.3、迭代切片
- 使用 for range 迭代切片
当迭代切片时,关键字range会返回两个值,第一个值是当前迭代到的索引位置,第二个值是该位置对应元素值的一份副本。
下面的程序中,因为迭代返回的变量是一个迭代过程中根据切片依次赋值的新变量,所以value的地址总是相同的。要想获取每个元素的地址,可以使用切片变量和索引值。
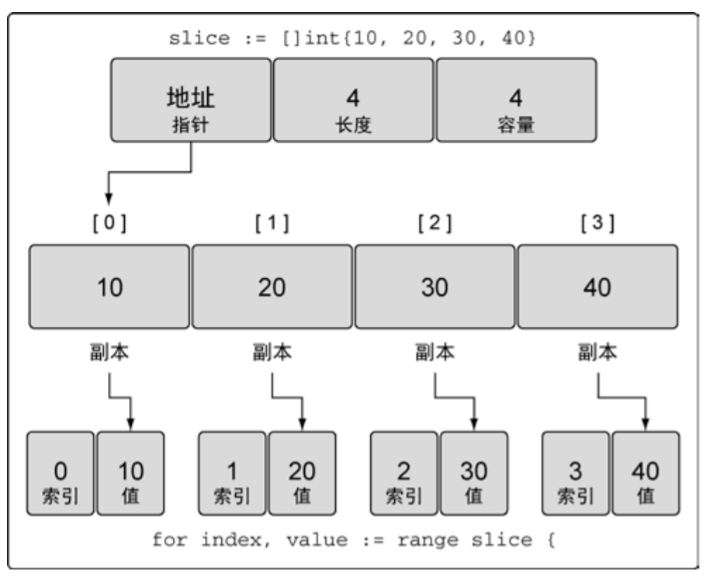
package main
import "fmt"
func main() {
// 创建一个整型切片,其长度和容量都是4个元素
slice := []int{10, 20, 30, 40}
// 迭代每个元素,并显示其值
for index, value := range slice {
fmt.Printf("Index: %d value: %d
", index, value)
}
// 迭代每个元素,并显示值和地址
for index, value := range slice {
fmt.Printf("Value:%d Value-Addr: %X ElemAddr:%X
",
value, &value, &slice[index])
}
}
输出:
Index: 0 value: 10
Index: 1 value: 20
Index: 2 value: 30
Index: 3 value: 40
Value:10 Value-Addr: C000012110 ElemAddr:C00000A420
Value:20 Value-Addr: C000012110 ElemAddr:C00000A428
Value:30 Value-Addr: C000012110 ElemAddr:C00000A430
Value:40 Value-Addr: C000012110 ElemAddr:C00000A438
- 使用下划线来忽略索引值
package main
import "fmt"
func main() {
// 创建一个整型切片,其长度和容量都是4个元素
slice := []int{10, 20, 30, 40}
// 迭代每个元素,并显示其值
for _, value := range slice {
fmt.Printf("value: %d
", value)
}
}
输出:
value: 10
value: 20
value: 30
value: 40
- 使用传统的for循环对切片进行迭代
package main
import "fmt"
func main() {
// 创建一个整型切片,其长度和容量都是4个元素
slice := []int{10, 20, 30, 40}
// 从第三个元素开始迭代每个元素
for index := 2; index < len(slice); index++ {
fmt.Printf("Index: %d Value: %d
", index, slice[index])
}
}
输出:
Index: 2 Value: 30
Index: 3 Value: 40
3.2.4、多维切片
package main
import "fmt"
func main() {
slice := [][]int{{10}, {100, 200}}
fmt.Println(slice[0], len(slice[0]), cap(slice[0]))
fmt.Println(slice[1], len(slice[1]), cap(slice[1]))
}
运行结果:
[10] 1 1
[100 200] 2 2

3.3、映射:map
在Go语言中,map是散列表的引用,map的类型是map[K]V,其中K和V是字典的键和值对应的数据类型。map中所有的键都拥有相同的数据类型,同时所有的值也都有相同的数据类型,但是键的类型和值的类型不一定相同。键的类型K,必须是可以通过操作符 == 来进行比较的数据类型,所以map可以检测某一个键是否已经存在。切片、函数以及包含切片的结构类型这些类型由于具有引用语义,不能作为映射的键。
3.3.1、创建和初始化
- 使用make声明映射
// 创建一个映射,键的类型是string, 值的类型是int
dict := make(map[string]int)
- 使用映射字面量
dict := map[string]string{"Red": "#da1337", "Orange": "#e95a22"}
上面说了,切片、函数以及包含切片的结构类型这些类型由于具有引用语义,不能作为映射的键。
// 创建一个映射,使用字符串切片作为映射的键
dict := map[[]string]int{} // Complier Exception:invalid map key type []string
但是可以使用切片等作为映射的值:
// 创建一个映射,使用字符串切片作为值
dict := map[int][]string{}
3.3.2、使用映射
- 为映射赋值
// 创建一个空映射,用来存储颜色以及颜色对应的十六进制代码
colors := map[string]string[]
// 将Red的代码加入到映射
colors["Red"] = "#da1337"
- 可以通过声明一个未初始化的映射来创建一个值为nil的映射(称为nil映射)。nil映射不能用于存储键值对,否则,会产生一个语言运行时错误。
// 通过声明映射创建一个nil映射
var colors map[string]string
// Runtime Error: panic: runtime error: assignment to entry in nil map
colors["Red"] = "#da1337"
- 从映射获取值并判断键是否存在
从映射取值时有两个选择。第一个选择是,可以同时获得值,以及一个表示这个键是否存在的标志:
// 获取键Blue对应的值
value, exists := colors["Blue"]
// 这个键存在吗
if exists {
fmt.Println(value)
}
另一个选择是,只返回键对应的值,然后通过判断这个值是不是零值来确定键是否存在:
value := colors["Blue"]
if value != "" {
fmt.Println(value)
}
- 使用range迭代映射
package main
import "fmt"
func main() {
colors := map[string]string{
"AliceBlue": "#f0f8ff",
"Coral": "#ff7F50",
"DarkGray": "#a9a9a9",
"ForestGreen": "#228b22",
}
for key, value := range colors {
fmt.Printf("Key: %s Value: %s
", key, value)
}
}
- 从映射中删除一项
如果想把一个键值对从映射中删除,可以使用内置的delete函数。
package main
import "fmt"
func main() {
colors := map[string]string{
"AliceBlue": "#f0f8ff",
"Coral": "#ff7F50",
"DarkGray": "#a9a9a9",
"ForestGreen": "#228b22",
}
for key, value := range colors {
fmt.Printf("Key: %s Value: %s
", key, value)
}
// 删除键为Coral的键值对
delete(colors, "Coral")
for key, value := range colors {
fmt.Printf("Key: %s Value: %s
", key, value)
}
}
3.3.3、在函数间传递映射
在函数间传递映射并不会制作出该映射的一个副本。实际上,当传递映射给一个函数,并对这个映射做了修改时,所有对这个映射的引用都会察觉到这个修改:
package main
import "fmt"
// removeColor将指定映射里的键删除
func removeColor(colors map[string]string, key string) {
delete(colors, key)
}
func main() {
colors := map[string]string{
"AliceBlue": "#f0f8ff",
"Coral": "#ff7F50",
"DarkGray": "#a9a9a9",
"ForestGreen": "#228b22",
}
for key, value := range colors {
fmt.Printf("Key: %s Value: %s
", key, value)
}
// 调用函数来移除指定的键
removeColor(colors, "Coral")
for key, value := range colors {
fmt.Printf("Key: %s Value: %s
", key, value)
}
}
运行结果:
Key: Coral Value: #ff7F50
Key: DarkGray Value: #a9a9a9
Key: ForestGreen Value: #228b22
Key: AliceBlue Value: #f0f8ff
Key: AliceBlue Value: #f0f8ff
Key: DarkGray Value: #a9a9a9
Key: ForestGreen Value: #228b2
3.4、结构体
package main
import (
"fmt"
"time"
)
type Employee struct {
ID int // 结构体变量名称首字母是大写的,那这个变量是可导出的
Name string
Address string
DoB time.Time
Position string
Salary int
ManagerId int
}
func main() {
var dilbert Employee
// 每个成员都是通过点号方式来访问的
dilbert.Salary -= 5000
position := &dilbert.Position
*position = "Senior " + *position
fmt.Println(dilbert)
// 点号同样可以用在结构体指针上
var employeeOfTheMonth *Employee = &dilbert
employeeOfTheMonth.Position += "proactive team player"
fmt.Println(employeeOfTheMonth.Position)
}
输出:
{0 0001-01-01 00:00:00 +0000 UTC Senior -5000 0}
Senior proactive team player
Go允许我们定义不带名称的结构体成员,只需要指定类型即可;这种结构体成员称为匿名成员:
type Point struct {
X, Y int
}
type Circle struct {
Point
Radius int
}
type Wheel struct {
Circle
Spokes int
}
上面的Circle和Wheel都有一个匿名成员。这里称Point被嵌套到Circle中,Circle被嵌套到Wheel中。
4、函数
4.1、函数的声明
函数声明包括函数名、形式参数列表、返回值列表(可省略)以及函数体。
func name(parameter-list) (result-list) {
body
}
举例:
package main
import (
"fmt"
"math"
)
func hypot(x, y float64) float64 {
return math.Sqrt(x*x + y*y)
}
func main() {
fmt.Println(hypot(3, 4)) // 5
}
实参是按值传递的,所以函数接收到的是每个实参的副本;修改函数的形参变量并不会影响到调用者提供的实参。然而,如果提供的实参包含引用类型,比如指针、slice、map、函数或者channel,那么当函数使用形参变量时就有可能会间接地修改实参变量。
4.2、函数的递归
package main
import "fmt"
func fact(n int) int {
if n == 0 {
return 1
}
return n * fact(n-1)
}
func main() {
fmt.Println(fact(7)) // 5040
}
4.3、多返回值
package main
import "fmt"
func swap(x, y string) (string, string) {
return y, x
}
func main() {
a, b :=swap("Google", "Runoob")
fmt.Println(a, b)
}
4.4、匿名函数
拥有函数名的函数只能在包级语法块中被声明,通过函数字面量(function literal),我们可绕过这一项限制,在任何表达式中表示一个函数值。函数字面量的语法和函数声明类似,区别在于func关键字后面没有函数名。函数值字面量是一种表达式,它的值被称为匿名函数(anonymous function)。匿名函数其实就是闭包。
package main
import "fmt"
func squares() func() int {
var x int
return func() int {
x++
return x * x
}
}
func main() {
f:=squares()
fmt.Println(f()) // 1
fmt.Println(f()) // 4
fmt.Println(f()) // 9
fmt.Println(f()) // 16
}
4.5、可变参数
参数数量可变的函数称为可变参数函数。在声明可变参数函数时,需要在参数列表的最后一个参数类型之前加上省略符号"...",这表示该函数会接收任意数量的该类型参数。
package main
import "fmt"
func sum(vals ...int) int {
total:=0
for _,val:=range vals {
total += val
}
return total
}
func main() {
fmt.Println(sum()) // 0
fmt.Println(sum(1)) // 1
values:=[]int{3,4,5}
fmt.Println(sum(3, 4, 5)) // 12
fmt.Println(sum(values...)) // 12
}
这里需要注意倒数第二行和倒数第一行它们两的作用是一样的。
4.6、延迟函数(defer)调用
Go语言的defer语句会将其后面跟随的语句进行延迟处理,在defer归属的函数即将返回时、将延迟处理的语句按defer的逆序进行执行,即:先被defer的语句最后被执行,最后被defer的语句,最先被执行。defer一般用于释放某些已分配的资源,典型的例子就是一对互斥解锁,或者关闭一个文件。
package main
import "fmt"
func main() {
fmt.Println("defer begin")
// 将defer放入延迟调用栈
defer fmt.Println(1)
defer fmt.Println(2)
defer fmt.Println(3)
fmt.Println("defer end")
}
输出:
defer begin
defer end
3
2
1
5、方法
方法能给用户定义的类型添加新的行为。方法实际上也是函数,只是在声明时,在关键字func和方法名之间增加了一个参数。这个参数被称作接收者。接收者有两者类型:值接收者和指针接收者。值接收者使用值的副本来调用方法,而指针接收者使用实际值来调用方法。
package main
import "fmt"
// user在程序里定义一个用户类型
type user struct {
name string
email string
}
// notify使用值接收者实现了一个方法
func (u user) notify() {
fmt.Printf("Sending User Email To %s<%s>
", u.name, u.email)
}
// changeEmail使用指针接收者实现了一个方法
func (u *user) changeEmail(email string) {
u.email = email
}
func main() {
// user类型的值可以用来调用使用值接收者声明的方法
bill := user{"Bill", "bill@email.com"}
bill.notify()
// 指向user类型值的指针也可以用来调用使用值接收者声明的方法
lisa := &user{"Lisa", "lisa@email.com"}
lisa.notify() // 为了支持这种做法,Go语言在背后做了一下调整: (*lisa).notify()
// user类型的值可以用来调用使用指针接收者声明的方法
bill.changeEmail("bill@newdomain.com") //为了支持这种做法,Go语言在背后做了一下调整: (&bill).changeEmail("bill@newdomain.com")
bill.notify()
// 指向user类型值的指针可以用来调用使用指针接收者声明的方法
lisa.changeEmail("lisa@comcast.com")
lisa.notify()
}
输出:
Sending User Email To Bill<bill@email.com>
Sending User Email To Lisa<lisa@email.com>
Sending User Email To Bill<bill@newdomain.com>
Sending User Email To Lisa<lisa@comcast.com>
6、接口与多态
package main
import (
"fmt"
"math"
)
// 接口
type shape interface {
area() float64 // 计算面积
perimeter() float64 // 计算周长
}
// 长方形
type rect struct {
width, height float64
}
func (r *rect) area() float64 { // 面积
return r.width * r.height
}
func (r *rect) perimeter() float64 { // 周长
return 2 * (r.width + r.height)
}
// 圆形
type circle struct {
radius float64
}
func (c *circle) area() float64 { // 面积
return math.Pi * c.radius * c.radius
}
func (c *circle) perimeter() float64 { // 周长
return 2 * math.Pi * c.radius
}
func main() {
r := rect{ 2.9, height: 4.8}
c := circle{radius: 4.3}
s := []shape{&r, &c} // 通过指针实现
for _, sh := range s {
fmt.Println(sh)
fmt.Println(sh.area())
fmt.Println(sh.perimeter())
}
}
输出:
&{2.9 4.8}
13.92
15.399999999999999
&{4.3}
58.088048164875275
27.01769682087222
7、并发
7.1、goroutine
Go语言的并发同步模型来自一个叫做通信顺序进程(Communicating Sequential Processes, CSP)的范型。
当一个程序启动时,只有一个goroutine来调用main函数,称为主goroutine。新的goroutine通过go语句进行创建。语法上,就是在普通的函数或者方法调用前加上go关键字前缀。
并发(concurrency)不是并行(parallelism)。并行是让不同的代码片段同时在不同的物理处理器上执行。并行的关键是同时做很多事情,而并发是指同时管理很多事情,这些事情可能只做了一半就被暂停去做别的事情了。
如果想要goroutine并行,必须使用多于一个逻辑处理器。当有多个逻辑处理器时,调度器会将goroutine平等分配到每个逻辑处理器上。这会让goroutine在不同的线程上运行。不过要想真的实现并行的效果,用户需要让自己的程序运行在有多个物理处理器的机器上。否则,哪怕Go语言运行时使用多个线程,goroutine依然会在同一个物理出其里上并行运行,达不到并行的效果。

看下goroutine的例子,这个程序会创建两个goroutine,以并发的形式分别显示大写和小写的英文字母
package main
import (
"fmt"
"runtime"
"sync"
)
func main() {
// 分配一个逻辑处理器给调度器使用
runtime.GOMAXPROCS(1)
// wg用来等待程序完成
// 计数加2,表示要等待两个goroutine
var wg sync.WaitGroup
wg.Add(2)
fmt.Println("Start Goroutines")
// 声明一个匿名函数,并创建一个goroutine
go func() {
// 在函数退出时调用Done来通知main函数工作已经完成
defer wg.Done()
// 显示字母表3次
for count := 0; count < 3; count++ {
for char := 'a'; char < 'a'+26; char++ {
fmt.Printf("%c ", char)
}
}
}()
// 声明一个匿名函数,并创建一个goroutine
go func() {
// 在函数退出时调用Done来通知main函数工作已经完成
defer wg.Done()
// 显示字母表3次
for count := 0; count < 3; count++ {
for char := 'A'; char < 'A'+26; char++ {
fmt.Printf("%c ", char)
}
}
}()
// 等待goroutine结束
fmt.Println("Waiting To Finish")
wg.Wait()
fmt.Println("
Terminating Program")
}
在这个代码中,调用了runtime包的GOMAXPROCS函数。这个函数允许程序更改调度器可以使用的逻辑处理器的数量。WaitGroup是一个计数信号量,可以用来记录并维护运行的goroutine。如果WatiGroup的值大于0,Wait方法就会阻塞。将这个WaitGroup设置为2,说明有两个goroutine。为了减小WaitGroup的值并最终释放main函数,使用defer声明在函数退出时调用Done方法。基于调度器的内部算法,一个正在运行的goroutine在工作结束前,可以被停止并重新调度。调度器这样做的目的是防止某个goroutine长时间占用逻辑处理器。当goroutine占用时间过长时,调度器会停止当前正在运行的goroutine,并给其他可运行的goroutine运行的机会。。下图从逻辑处理器的角度展示了这一场景。
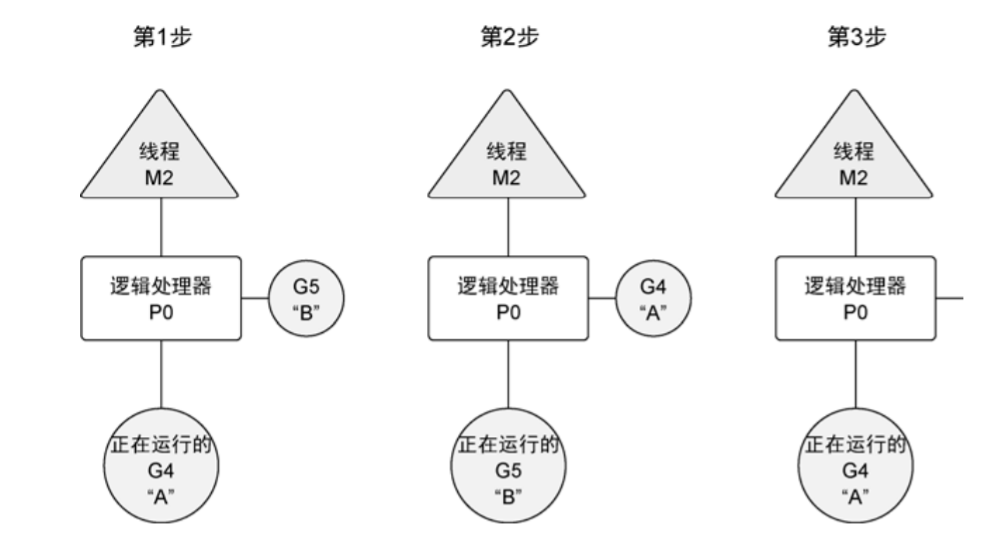
7.2、竞争状态
如果两个或者多个goroutine在没有互相同步的情况下,访问某个共享的资源,并试图同时读和写这两个资源,就出于竞争的状态,这种情况称为竞争状态(race condion)。对一个共享资源的读和写操作必须是原子化的,也就是说,同一时刻只能有一个goroutine对共享资源进行读和写操作。下面的一段代码是包含竞争状态的一个例子:
package main
import (
"fmt"
"runtime"
"sync"
)
var (
// counter是所有goroutine都要增加其值的变量
counter int
wg sync.WaitGroup
)
func main() {
// 计数加2,表示要等待两个goroutine
wg.Add(2)
// 创建两个goroutine
go incCounter(1)
go incCounter(2)
// 等待goroutine结束
wg.Wait()
fmt.Println("Final Counter", counter)
}
// incCounter增加包里counter变量的值
func incCounter(id int) {
// 在函数退出时调用Done来通知main函数工作已经完成
defer wg.Done()
for count := 0; count < 2; count++ {
// 捕获counter的值
value := counter
// 当前goroutine从线程退出,并放回到队列
runtime.Gosched()
// 增加本地value变量的值
value++
// 将该值保存回counter
counter = value
}
}
输出结果:
Final Counter 2
变量counter会进行4次读和写操作,每个goroutine执行两次。但是运行结果却是2,为什么呢?下面的图可以解释:

7.3、锁住共享资源
7.3.1、原子操作
为了解决上面那段程序的竞争问题,可以用原子函数的加锁机制来解决问题。下面是上面的一个解决办法:
package main
import (
"fmt"
"runtime"
"sync"
"sync/atomic"
)
var (
// counter是所有goroutine都要增加其值的变量
counter int64
// wg用来等待程序的结束
wg sync.WaitGroup
)
func main() {
// 计数加2,表示要等待两个goroutine
wg.Add(2)
// 创建两个goroutine
go incCounter(1)
go incCounter(2)
// 等待goroutine结束
wg.Wait()
// 显示最终的值
fmt.Println("Final Counter:", counter)
}
// incCounter增加包里counter变量的值
func incCounter(id int) {
// 在函数退出时调用Done来通知main函数工作已经完成
defer wg.Done()
for count := 0; count < 2; count++ {
// 安全的对counter加1
atomic.AddInt64(&counter, 1)
// 当前goroutine从线程退出,并放回到队列
runtime.Gosched()
}
}
运行结果:
Final Counter: 4
7.3.2、互斥锁
还有一种同步访问共享资源的方式是使用互斥锁(mutex)。互斥锁用于在代码上创建一个临界区,保证同一时刻只有一个goroutine可以执行这个临界区代码。
package main
import (
"fmt"
"runtime"
"sync"
)
var (
// counter是所有goroutine都要增加其值的变量
counter int
// wg用来等待程序结束
wg sync.WaitGroup
// mutex用来定义一段代码临界区
mutex sync.Mutex
)
func main() {
// 计数加2,表示要等待两个goroutine
wg.Add(2)
// 创建两个goroutine
go incCounter(1)
go incCounter(2)
// 等待goroutine结束
wg.Wait()
fmt.Printf("Final Counter:%d
", counter)
}
// incCounter使用互斥锁来同步并保证安全访问,增加包里counter变量的值
func incCounter(in int) {
// 在函数退出时调用Done来通知main函数工作已经完成
defer wg.Done()
for count := 0; count < 2; count++ {
// 同一时刻只允许一个goroutine进入这个临界区
mutex.Lock()
{
// 捕获counter的值
value := counter
// 当前goroutine从线程退出,并放回到队列
runtime.Gosched()
// 增加本地value变量的值
value++
// 将该值保存回counter
counter = value
}
mutex.Unlock() // 释放锁,允许其他正在等待的goroutine进入临界区
}
}
7.4、通道
当一个资源需要在goroutine之间共享时,通道在goroutine之间架起了一个管道,并提供了确保同步交换数据的机制。声明通道时,需要指定将被共享的数据的类型。可以通过通道共享内置类型、命名类型、结构类型和引用类型的值或者指针。向通道发送值或者指针需要用到<-操作符。当从通道里接收一个值或者指针时,<-运算符在要操作的通道变量的左侧。
// 使用make创建通道
// 无缓冲的整型通道
unbuffered := make(chan int)
// 有缓存的字符串通道
buffered := make(chan string, 10)
// 通过通道发送一个字符串
buffered <- "Gopher"
// 从通道里接收值
value := <- buffered
7.4.1、无缓冲的通道
无缓冲的通道(unbuffered channel)是指在接收前没有能力保存任何值的通道。这种类型的通道要求发送goroutine和接收goroutine同时准备好,才能完成发送和接收操作。
下面的图展示了两个goroutine如何利用无缓冲的通道来共享一个值的。在第1步,两个goroutine都到达通道,但是哪个都没有开始执行发送或者接收。在第2步,左侧的goroutine将它的手伸进了通道,这模拟了向通道发送数据的行为。这时,这个goroutine会在通道中被锁住,直到交换完成。在第3步,右侧的goroutine将它的手放入通道,这模拟了从通道里接收数据。这个goroutine一样也会在通道中被锁住,直到交换完成。在第4步和第5步,进行交换,并最终,在第6步,两个goroutine都将它们的手从通道里拿出来,这模拟了被锁住的goroutine得到释放。两个goroutine现在都可以去做别的事情了。

在网球比赛中,两位选手会把球在两个人之间来回传递。选手总是处在以下两种状态之一:要么在等待接球,要么将球打向对方。可以使用两个goroutine来模拟网球比赛,并使用无缓冲的通道来模拟球的来回,如下代码所示:
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
// wg用来等待程序结束
var wg sync.WaitGroup
func init() {
rand.Seed(time.Now().UnixNano())
}
func main() {
// 创建一个无缓冲的通道
court := make(chan int)
// 计数加2,表示要等待两个goroutine
wg.Add(2)
// 启动两个选手
go player("Nadal", court)
go player("Djokovic", court)
// 发球
court <- 1
// 等待游戏结束
wg.Wait()
}
func player(name string, court chan int) {
// 在函数退出时调用Done来通知main函数工作已经完成
defer wg.Done()
for {
// 等待球被击过来
ball, ok := <-court
if !ok {
// 如果通道被关闭,我们就赢了
fmt.Printf("Player %s Won
", name)
return
}
// 选随机数,然后用这个数来判断我们是否丢球
n := rand.Intn(100)
if n%13 == 0 {
fmt.Printf("Player %s Missed
", name)
// 关闭通道,表示我们输了
close(court)
return
}
// 显示击球数,并将击球数加1
fmt.Printf("Player %s Hit %d
", name, ball)
ball++
// 将球打向对手
court <- ball
}
}
输出:
Player Djokovic Hit 1
Player Nadal Hit 2
Player Djokovic Hit 3
Player Nadal Hit 4
Player Djokovic Hit 5
Player Nadal Hit 6
Player Djokovic Hit 7
Player Nadal Hit 8
Player Djokovic Hit 9
Player Nadal Missed
Player Djokovic Won
7.4.2、有缓冲的通道
有缓冲的通道(buffered channel)是一种在被接收前能存储一个或者多个值的通道。这种类型的通道并不强制要求goroutine之间必须同时完成发送和接收。通道会阻塞发送和接收动作的条件也会不同。只有在通道中没有要接收的值时,接收动作才会阻塞。只有在通道没有可用缓冲区容纳被发送的值时,发送动作才会阻塞。这导致有缓冲的通道和无缓冲的通道之间的一个很大的不同:无缓冲的通道保证进行发送和接收的goroutine会在同一时间进行数据交换;有缓冲的通道没有这种保证。
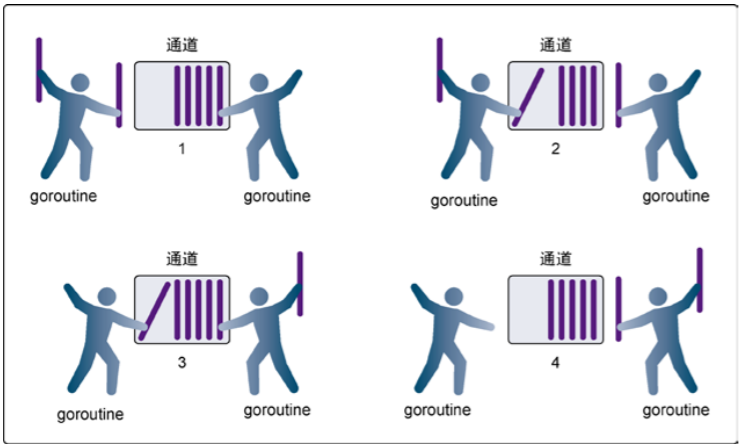
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
const (
numberGorouines = 4 // 要使用的goroutine的数量
taskLoad = 10 // 要处理的工作的数量
)
// wg用来等待程序完成
var wg sync.WaitGroup
// init初始化包,Go语言运行时会在其他代码执行前优先执行这个函数
func init() {
// 初始化随机数的种子
rand.Seed(time.Now().Unix())
}
func main() {
// 创建一个有缓冲的通道来管理工作
tasks := make(chan string, taskLoad)
// 启动goroutine来处理工作
wg.Add(numberGorouines)
for gr := 1; gr <= numberGorouines; gr++ {
go worker(tasks, gr)
}
// 增加一组要完成的工作
for post := 1; post <= taskLoad; post++ {
tasks <- fmt.Sprintf("Task :%d", post)
}
// 当所有工作处理完时关闭通道
close(tasks)
// 等待所有工作完成
wg.Wait()
}
// worker作为goroutine启动来处理,从有缓冲的通道传入的工作
func worker(tasks chan string, worker int) {
// 通知函数已经返回
defer wg.Done()
for {
// 等待分配工作
task, ok := <-tasks
if !ok {
// 这意味着通道已经空了,并且已被关闭
fmt.Printf("Worker:%d : Shutting Down
", worker)
return
}
// 显示我们开始工作了
fmt.Printf("Worker:%d : Started %s
", worker, task)
// 随机等一段时间来模拟工作
sleep := rand.Int63n(100)
time.Sleep(time.Duration(sleep) * time.Millisecond)
// 显示我们完成了工作
fmt.Printf("Worker:%d : Completed %s
", worker, task)
}
}