在使用Jmeter进行性能测试时,难免遇到要求并发请求数比较的场景,此时单台测试机的配置(CPU、内存、带宽等)可能无法支持此性能测试场景。因而,此时 Jmeter 提供的分布式测试功能就有了用武之地。
下面就以Jmeter3.0 版本进行实例详解,敬请参阅!
一、Jmeter分布式执行原理
Jmeter分布式执行原理如下图所示:

调度机(Controller):主要负责性能测试脚本的分发,及各个执行机的测试结果收集汇总,报告产出。
执行机(Slave):主要负责执行性能测试脚本及断言等(命令行模式执行,无界面),并将执行结果及反馈给调度机(Controller),若断言执行成功则不返回请求响应数据及详细断言信息。
二、执行配置(Slave)
1、JDK版本为 1.8.0,配置相应的环境变量,可参阅 JDK环境配置
2、JMeter版本为 3.0,配置相应的环境变量,可参阅 JMeter环境配置
3、配置执行机服务器远程启动端口
修改配置文件:JMETER_HOME/bin/jmeter.properties 中如下信息即可完成配置执行机远程启动端口(默认为 1099)
server_port = 1029
server.rmi.localport = 1029
4、启动执行机服务器
管理员执行脚本:JMETER_HOME/bin/jmeter-server.bat 或 JMETER_HOME/bin/jmeter-server,启动后命令行页面如下图所示:
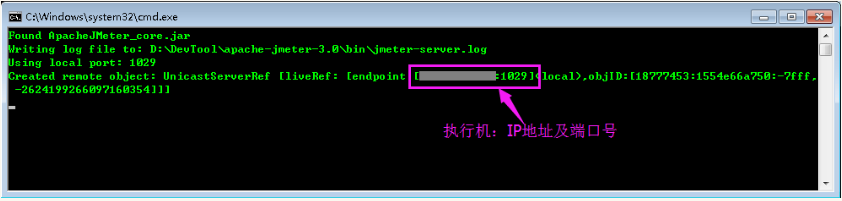
从启动命令行窗口可见,配置的远程启动端口已经生效。
三、调度机(Controller)配置
1、添加执行机(Slave)
路径:JMETER_HOME/bin/jmeter.properties,添加如下所示的执行机信息(IP为示例,请配置正确的执行机IP和端口):
remote_hosts=192.168.1.50:1029,192.168.1.51:1029
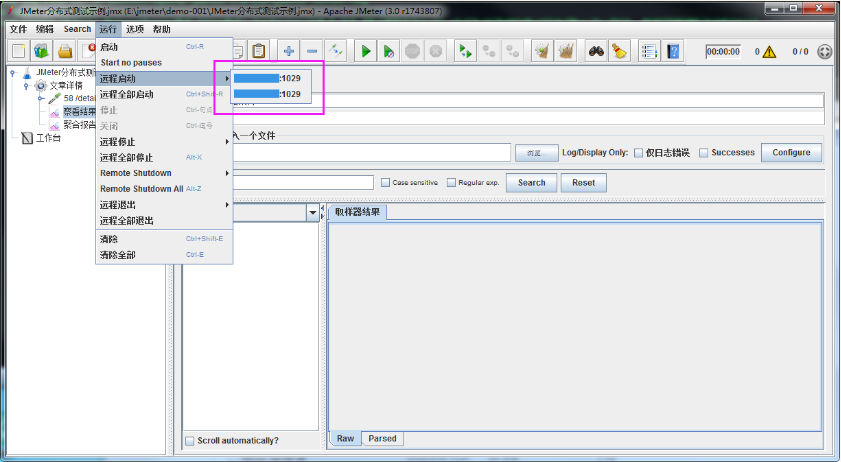
2、启动调度机
启动后,依次点击【运行/远程启动】,即可查看配置的远程执行机信息,如下图所示:
四、启动单执行机(初步调试)
接第三步,任意启动一个执行机(Slave)查看执行结果,如下图所示:
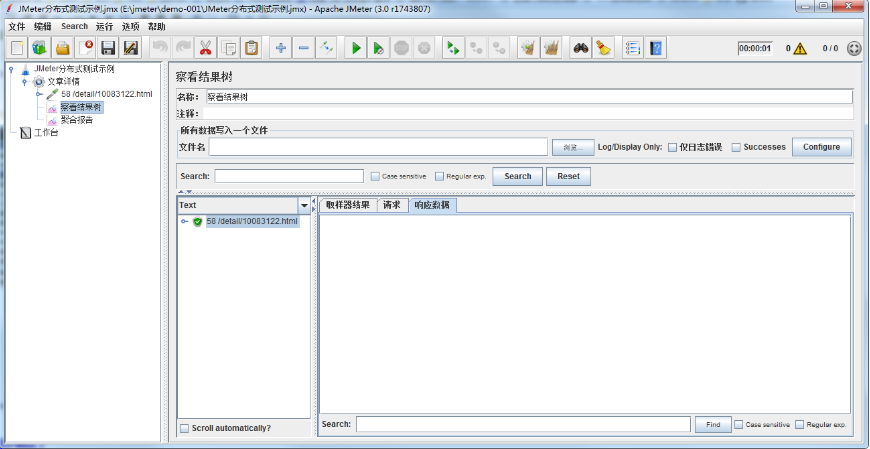
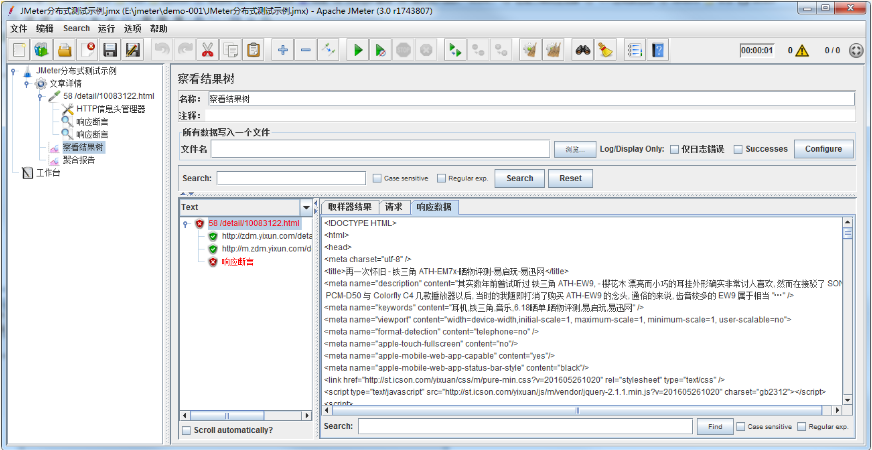
在执行机服务命令行窗口可见如下输出信息:

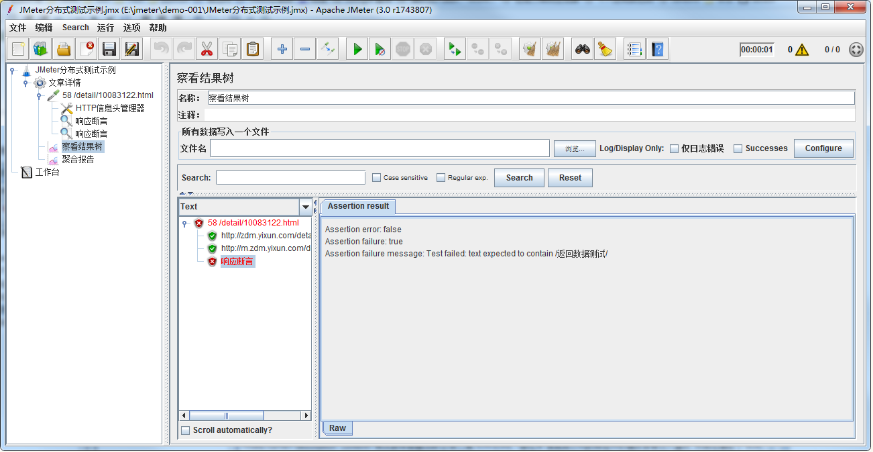
若断言执行失败,则在查看结果数中,可看到详细的请求响应数据及断言结果,如下所示:
五、启动全部执行机(性能测试)
1、执行机(Slave)初步调试:
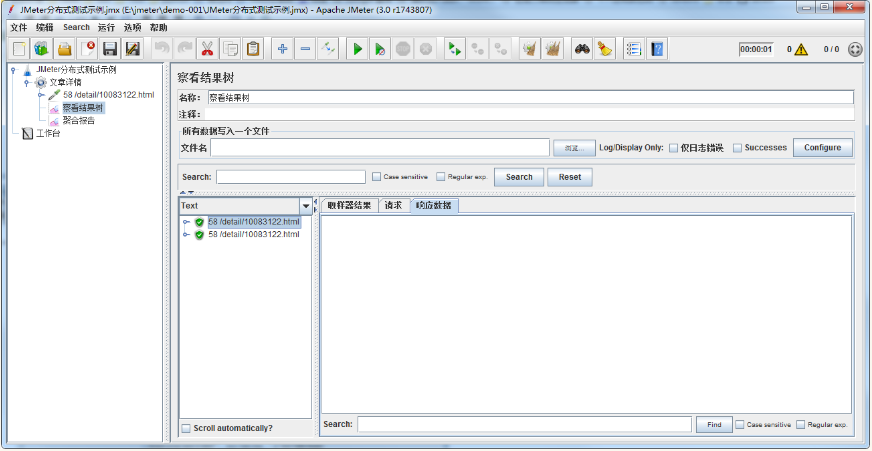
接第三步,点击【运行/远程全部启动】,可通过此步进行初步调试,执行结果如下所示:
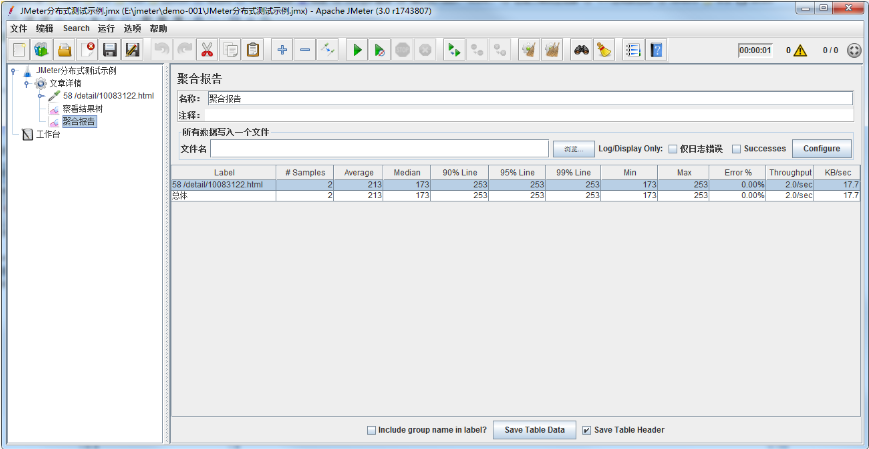
2、性能测试参数设置
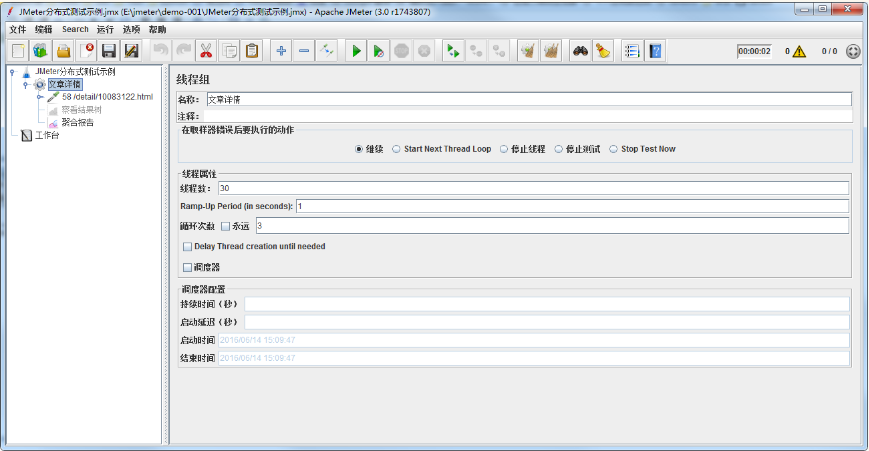
初步调试通过后,依据测试场景所需进行性能测试设置,如下图所示:
3、执行性能测试
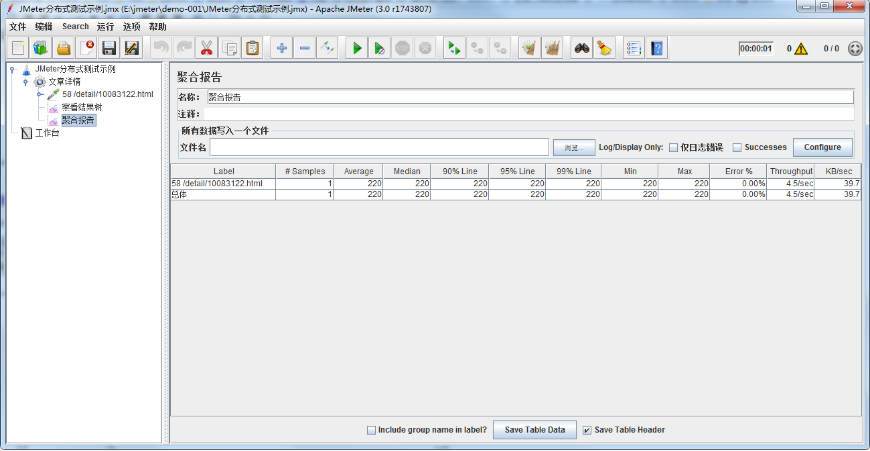
远程全部启动后,待测试执行完成,可查看性能测试聚合报告,如下图所示:
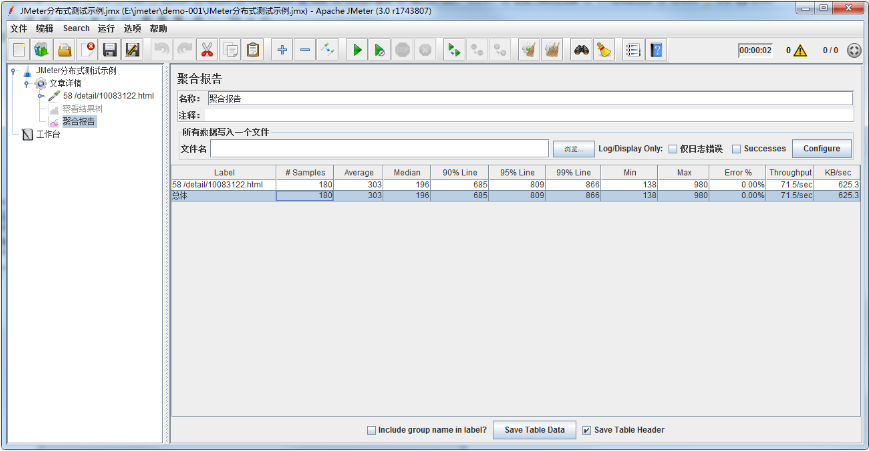
总样本数 = 线程数 * 循环次数 * 执行机总数
样本计数逻辑:由Jmeter分布式执行原理可知,执行机(Salve)执行的测试脚本是由调度机(Controller)分发的,故每台执行机执行的测试脚本都是相同的,故而性能测试总样本数 = 测试脚本
为更好的模拟性能并发场景,还需要设置集合点
六、注意事项
1、JMeter版本保持一致
2、JDK版本保持一致,否则可能出现各种其他的问题
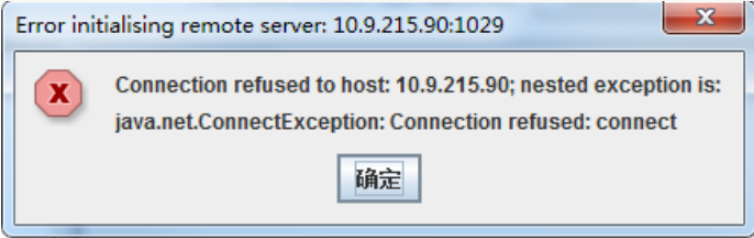
七、异常处理
1、若出现如下所示异常信息,请检查远程执行机是否成功启动jmeter-server.bat或信息配置是否正确。