[ERROR] Failed to execute goal net.alchim31.maven:scala-maven-plugin:3.2.2:compile (scala-compile-first) on project spark-tags_2.11: Execution scala-compile-first of goal net.alchim31.maven:scala-maven-plugin:3.2.2:compile failed. CompileFailed -> [Help 1]
注:那种告诉你要加什么什么配置,但是不告诉你在什么位置加的都是耍流氓!!!
废话不多说,直接进入正题
官方文档永远是第一手学习资料,bilibili是白嫖第二手,各大平台是人民币第三手,所有博客都是其他手!!!
所以,

一、环境准备
1) JDK 1.8+
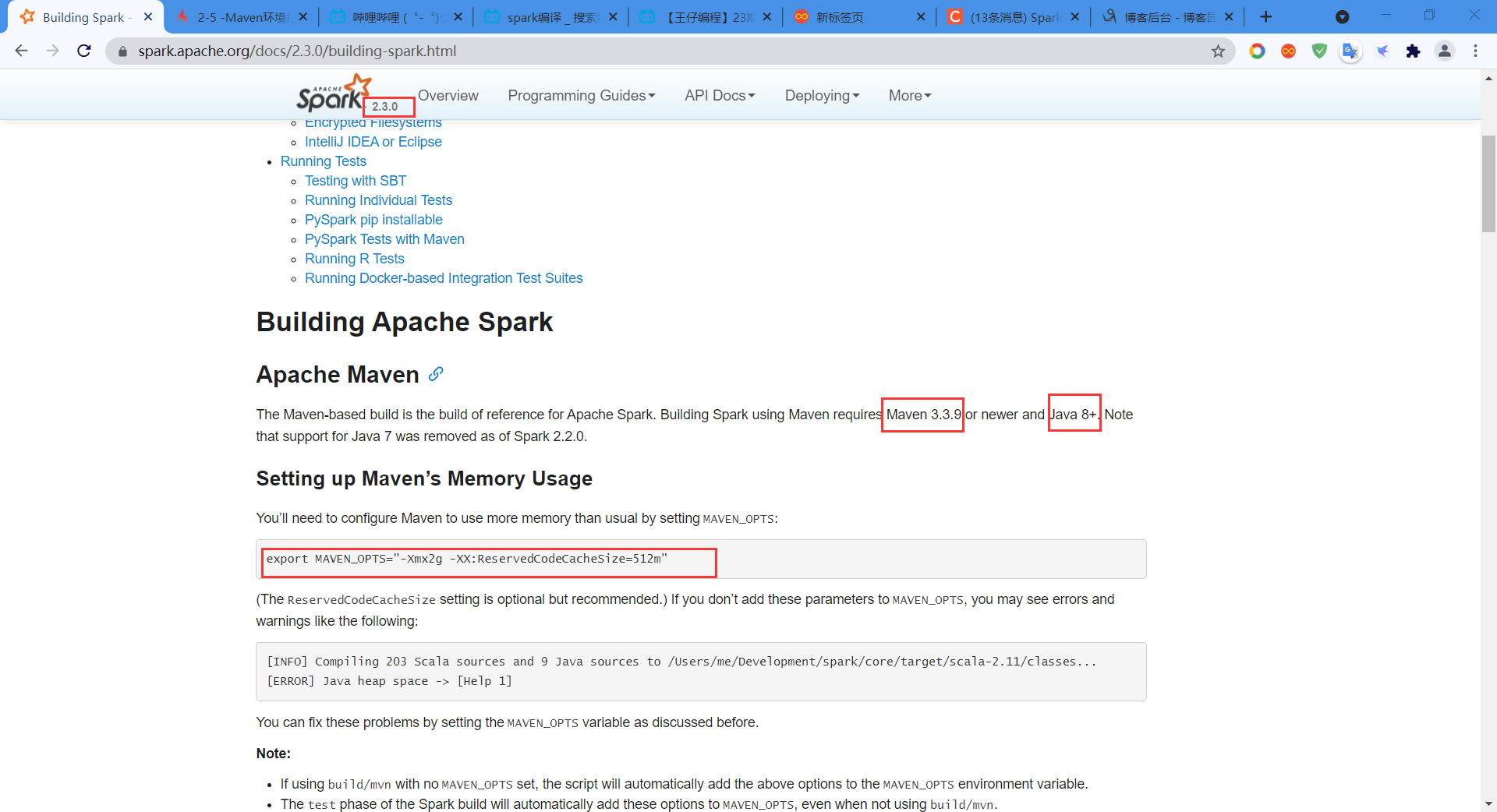
2) Maven 3.3.9+
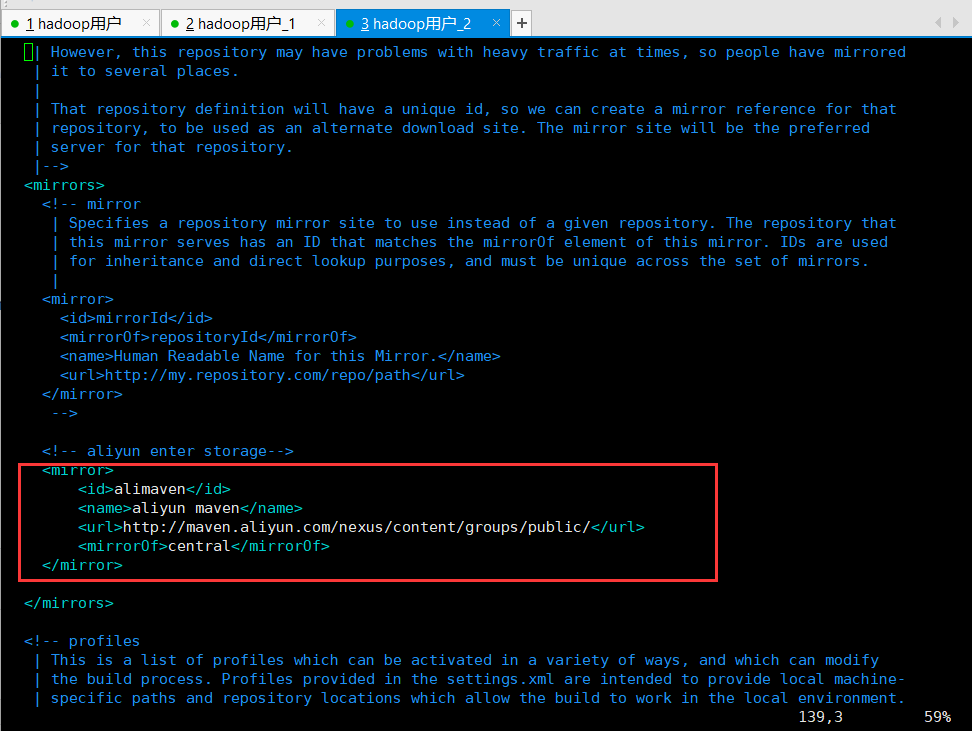
3) Scala 2.11.8(安装路径的conf文件夹下的配置文件settings.xml一定要正确配置,并且添加一个阿里云的maven中间仓库,加快编译Spark时下载相关包的速度)
添加的配置如下:

二、下载解压Spark-2.3.0源码并打包编译
正常来说make-distribution.sh打包编译Spark源码只需要三步,分别是:
1、设置maven内存大小,加到环境变量里
cd /home/haoop/
vim .bash_profile
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
2、CDH版本的Haoop需要配置pom.xml配置文件
cd Spark-2.3.0/
vim pom.xml
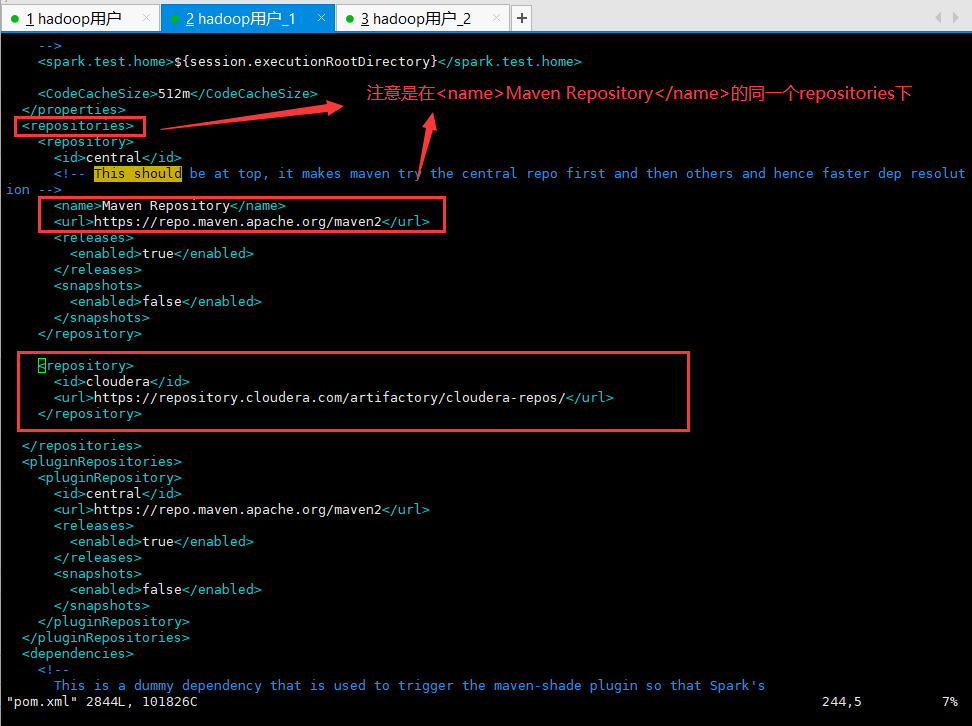
添加cloudera的maven仓库,配置内容:
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
添加配置的位置:
3、执行./dev/make-distribution.sh进行打包编译
./dev/make-distribution.sh --name 2.6.0-cdh5.15.1 --tgz -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.0-cdh5.15.1 -Phive -Phive-thriftserver
成功编译(快则十几分钟,慢则三四十分钟,再慢就编译失败吧,朋友们!)
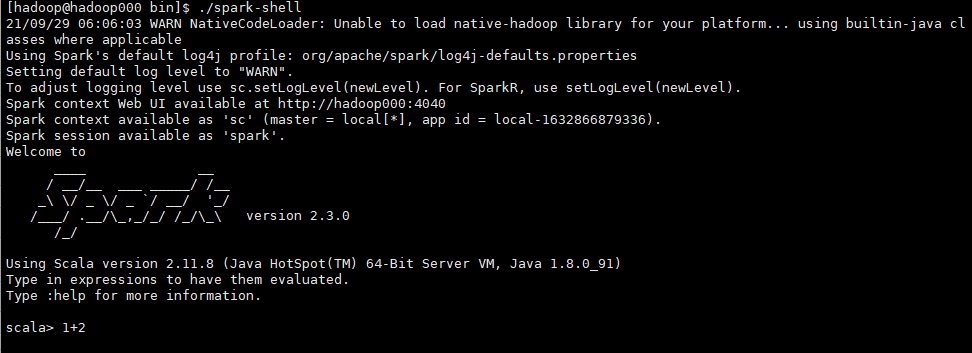
启动Saprk-shell
cd /home/hadoop/app/spark-2.3.0-bin-2.6.0-cdh5.15.1/bin/