Requests库get()函数访问google网页20次。
1.Requests模块介绍:
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库。用 Python 编写,真正的为人类着想。
Python 标准库中的 urllib2 模块提供了你所需要的大多数 HTTP 功能,但是它的 API 太渣了。它是为另一个时代、另一个互联网所创建的。它需要巨量的工作,甚至包括各种方法覆盖,来完成最简单的任务。
在Python的世界里,事情不应该这么麻烦。
Requests 使用的是 urllib3,因此继承了它的所有特性。Requests 支持 HTTP 连接保持和连接池,支持使用 cookie 保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码。现代、国际化、人性化。
(以上转自Requests官方文档
导入Requests模块。
![]()
2.插入代码:访问Google网页
# -*- coding: utf-8 -*- """ Spyder Editor This is a temporary script file. """ import requests def getHTMLText(ur1): try: r=requests.get(ur1,timeout=30) r.raise_for_status() #如果状态不是200,引发异常 r.encoding='utf-8'#无论原来用什么编码,都改成utf-8 return r.text except: return"" ur1="http://www.Google.com" for i in range(20): print(getHTMLText(ur1))
运行结果如下:
(好像访问不了哦。)
爬取中国大学排名(2017年)
1.插入代码
import requests from bs4 import BeautifulSoup allUniv = [] def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = 'utf-8' return r.text except: return "" def fillUnivList(soup): data = soup.find_all('tr') for tr in data: ltd = tr.find_all('td') if len(ltd)==0: continue singleUniv = [] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) def printUnivList(num): print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}".format(chr(12288),"排名","学校名称","省市","总分","培养规模")) for i in range(num): u = allUniv[i] print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8.1f}{5:{0}^10}".format(chr(12288),u[0],u[1],u[2],eval(u[3]),u[6])) def main(): url = 'http://www.zuihaodaxue.com/zuihaodaxuepaiming2017_0.html' html = getHTMLText(url) soup = BeautifulSoup(html, "html.parser") fillUnivList(soup) printUnivList(10) main()
2.运行结果。
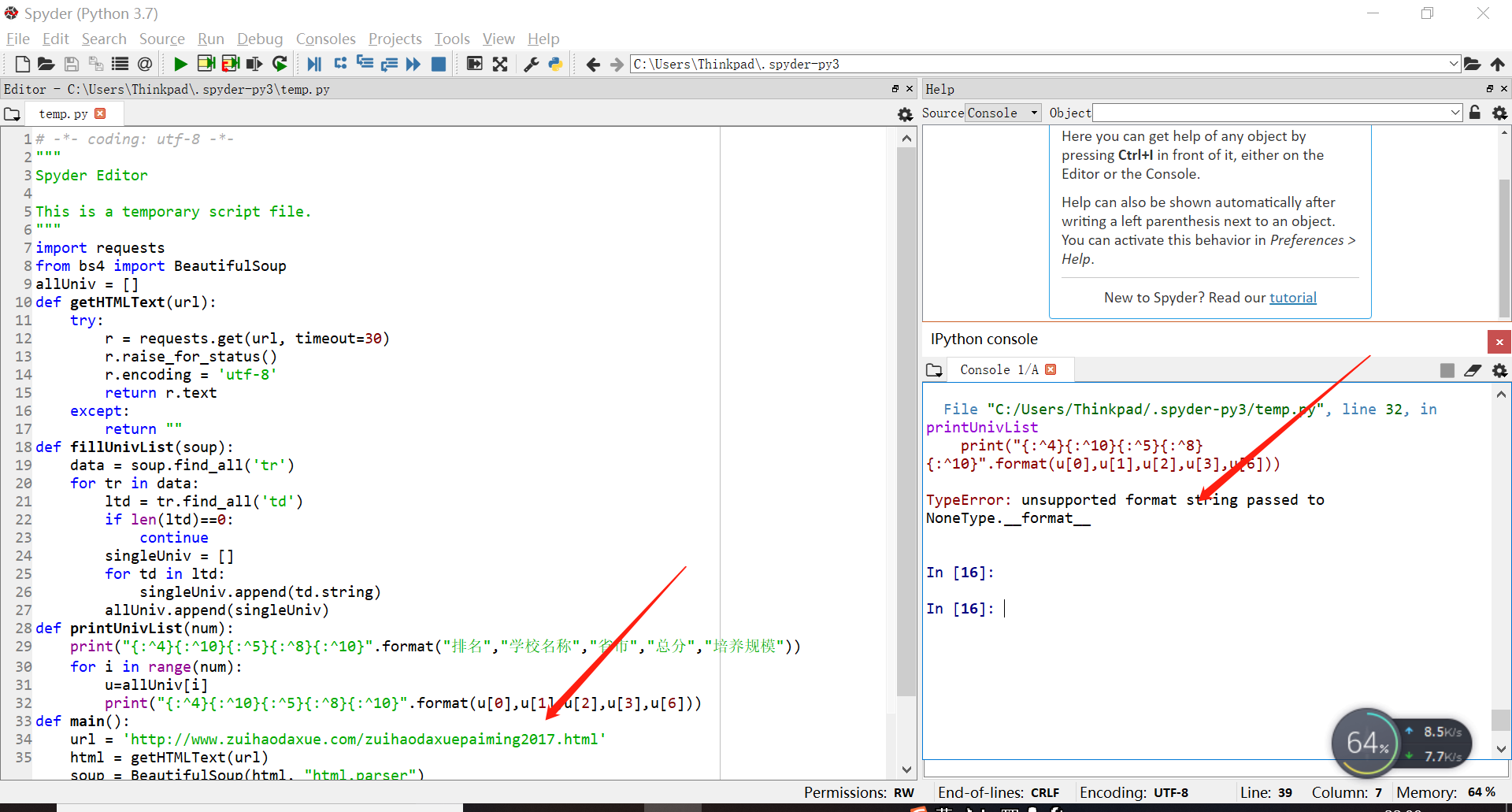
抱歉 初学者出现问题了,应该是那个网站的2017那个网页的代码有错误,代码没错。
初学者出现问题了,应该是那个网站的2017那个网页的代码有错误,代码没错。